
AI 大模型:从 Transformer、GPT 再到应用
—— 示例: 客户支持聊天机器人

【编者按】
对于AI大模型,我们常常看到它有几亿、几十亿乃至更多的参数,对计算的要求超级高。它可以被用来开发各种应用,可以和我们像人类一样地进行对话,可以部署到企业提升业务能力和效率。
那么作为大模型,它的基本结构是什么样的?是如何创建的、如何训练的、如何优化调整的?在应用场景或程序中,是如何使用和调整它的 … … 我们又是如何根据实际需求来设计和开发大模型的?
文中我们先了解Transformer模型及其经典代表之一GPT的一些基本概念和结构,然后假设以“客户支持聊天机器人”为场景,遍历它的整个应用开发过程。
目录

【续前文】
示例:应用场景(续)
模型训练
下一步,让我们对于为客户支持聊天机器人量身定制的基于 transformer 的 GPT 模型的训练过程,做一更加深入地了解,涵盖数据准备、损失函数、反向传播、优化算法和训练代码,以及最佳实践和注意事项。
为客户支持聊天机器人训练基于 Transformer 的 GPT 模型
1.数据准备
1.1 收集数据
训练聊天机器人模型的第一步是收集一个大型且多样化的数据集,该数据集反映了用户将与聊天机器人进行的交互类型。以下是一些常见的数据收集来源:
- 客户支持转录:从客户服务互动中收集转录,包括聊天记录、电子邮件和电话录音(如果可用)。
- 常见问题解答和知识库: 使用涵盖常见客户查询和响应的现有常见问题解答和知识库文章。
- 产品手册和指南:包括可协助聊天机器人提供有关产品和故障排除步骤的详细信息的产品文档。
- 用户反馈:从过去的互动中收集用户反馈,以了解常见问题和需要改善的领域。
1.2 预处理数据
收集数据后,需要对其进行预处理以确保质量和一致性。这涉及几个步骤:
- 清理数据:删除任何不相关的信息,例如个人数据、系统消息或不相关的对话。确保文本没有拼写错误和格式问题。

- 分词化:将文本数据转换为模型可以理解的分词(即标记)。这一般涉及使用与模型架构兼容的分词器。

- 格式化:将数据构建为输入-输出对。对于聊天机器人,每个输入都应对应于一个用户查询,并且输出应为预期响应。

2.损失函数
2.1 交叉熵损失
对于像 GPT 这样的语言模型,最常见的损失函数是交叉熵损失。此损失函数测量序列中下一个单词的预测概率分布和实际分布之间的差异。
- 数学定义:交叉熵损失 定义为:
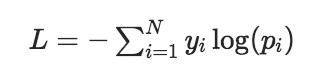
[
其中
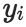
是真实分布(独热one-hot编码),
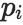
是预测的概率分布。
- 实现:在使用 Hugging Face 的 Transformers 库的上下文中,损失在训练期间自动计算。该模型输出词汇表中每个标记的 logits,并根据这些 logit 和真实标签计算交叉熵损失。
3.反向传播
3.1 渐变下降
反向传播是用于计算损失函数相对于模型参数的梯度的算法。这包括:
- 计算梯度:计算损失后,使用链式法则计算梯度。这告知我们如何调整权重以最大限度地减少损失。
- 更新权重:权重在梯度的相反方向更新以减少损失。这是对每批数据迭代完成的。
3.2 在 PyTorch 中实现
在 Hugging Face 中,当使用 ‘Trainer’ 类时,这个过程被抽象出来了,但理解底层机制是必不可少的。以下是它一般的工作原理:

4.优化算法
4.1 Adam 优化器
Adam (Adaptive Moment Estimation 自适应矩估计) 优化器由于其效率和有效性而常用于训练 transformer 模型。它结合了随机梯度下降的另外两个扩展的优点:AdaGrad 和 RMSProp。
- 自适应学习率:Adam 根据梯度的第一矩和第二矩调整每个参数的学习率,从而实现更快的收敛。
- 实现:在 Hugging Face 中,使用 ‘Trainer’ 类进行训练时,默认使用 Adam 优化器。

5.训练代码
目前我们已经介绍了训练的基本组成部分,下面是一个使用 Hugging Face 的 Transformers 库的完整训练脚本:
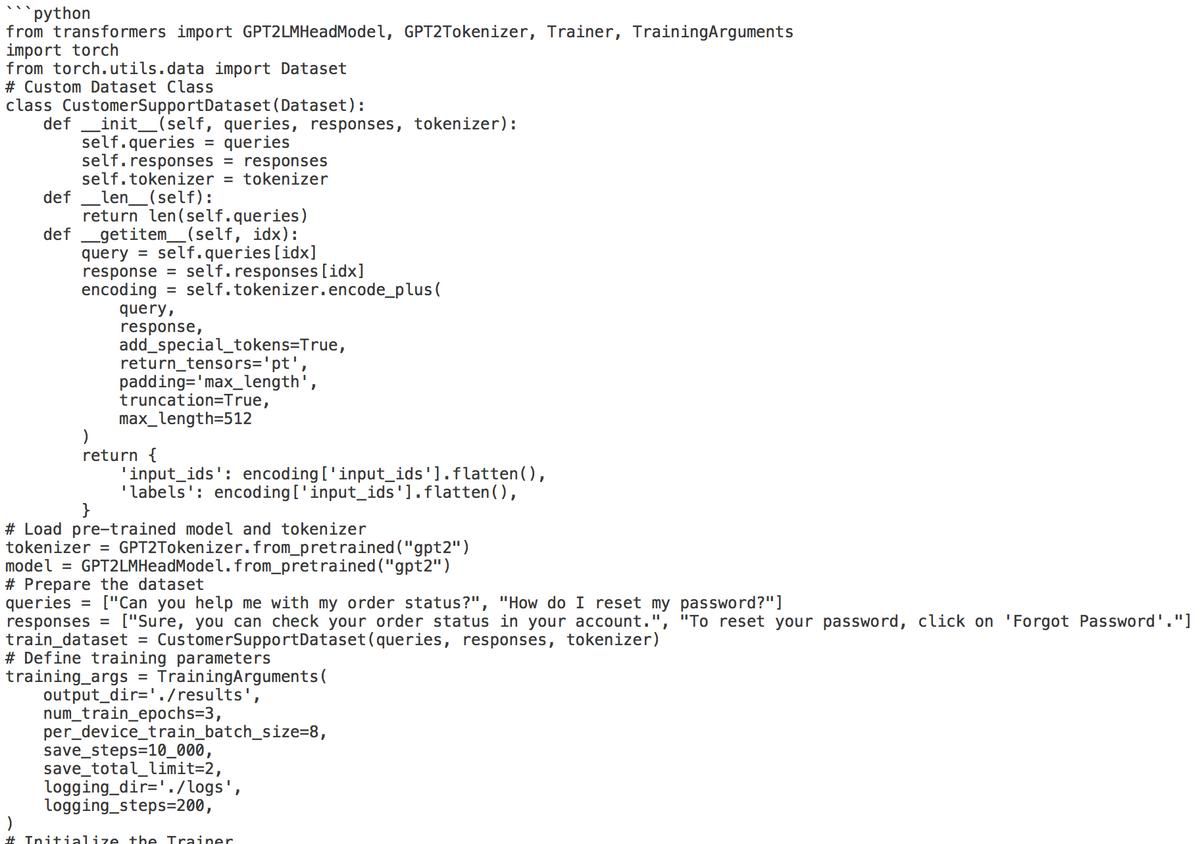
6.培训最佳实践
6.1 监控器培训
- 日志记录:使用日志记录来跟踪训练进度和性能指标。可以集成 TensorBoard 等工具来可视化损失和准确性。
- 验证集:始终维护验证集以监控过拟合。在每个 epoch 之后评估此集上的模型。
6.2 超参数调整
- 调整学习率:学习率对于训练至关重大。思考使用学习率计划程序来动态调整学习率。
- 批次大小: 尝试不同的批次大小。较大的批处理大小可以加快训练速度,但需要更多内存。
6.3 正则化技术
- Dropout:实施 dropout 层以防止过拟合。这会在训练期间将一小部分输入单位随机设置为零,这有助于泛化。
- 权重衰减:将权重衰减正则化应用于优化器,以防止模型与训练数据拟合得太紧密。
7.训练后注意事项
7.1 模型评估
训练后,使用各种指标评估模型,例如:
- 困惑度:衡量模型预测的概率分布与文本中下一个单词的实际分布的一致性程度。
- 用户满意度:进行用户测试,以收集有关聊天机器人在实际场景中性能的定性反馈。
7.2 微调和更新
- 持续学习:为聊天机器人实施一种机制,以便不断从新的交互中学习。这可能涉及定期使用新数据重新训练模型。
- 反馈循环:收集用户交互和反馈,以确定需要改善的领域,并相应地更新数据集。
为客户支持聊天机器人训练基于 transformer 的 GPT 模型,涉及数据准备、损失函数选择、反向传播和优化的系统方法。通过利用如 Hugging Face 的 Transformers 库等,您可以有效地实现和微调模型,以满足特定的客户需求。持续的监控、评估和适应,将确保聊天机器人在提供客户支持方面保持有效和相关性。
上面这份指南为训练聊天机器人模型提供了坚实的基础,但请记住,AI 和 NLP 领域在不断地发展,随时了解最新研究和最佳实践,以便进一步增强聊天机器人的功能。
【未完待续】

农历甲辰九月廿八

2024.10.30
【部分图片来源网络,侵删】


















暂无评论内容