
在数据分析过程中,我们常常会按某一列对数据进行排序,以便对比、查找和进一步分析。同时,也常常会把某一列中内容一样且连续行进行单元格合并,使表格看上去更加直观,列如下图,左侧红框内为合并单元格,左侧红框内为没有合并的独立单元格。
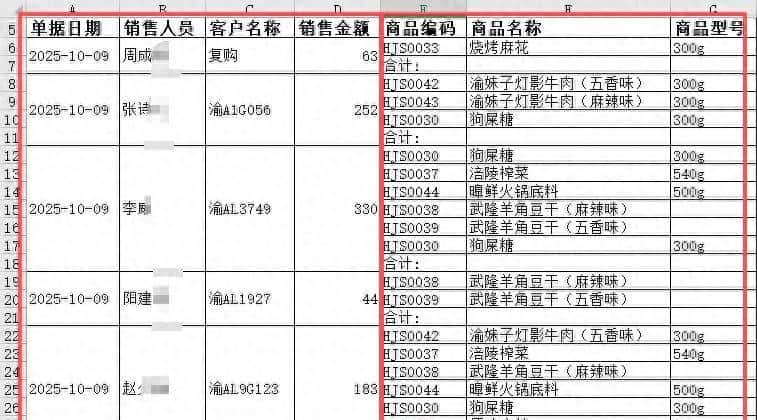
如果作为最终文档呈现给使用者,合并单元格更加符合日常的阅读习惯。不过,如要对表格进行编辑,这样的格式会带来诸多的不便。这不,目前的问题是要按第一列“单据日期”进行时间先后排序,原文中的数据是按时间倒序排列,日期越早的记录越靠后。最后发生的在工作表的最上方。

表格的前4列为合并单元格,且合并的行数并不固定,第5列为商品编码,每一组的最后一行为该组数据的合计。如果要手动处理排序,第一需要撤销单元格合并,并对撤销合并单元格后出现的空单元格进行填充,还要增加辅助列对第5列每一组数据进行组内排序,保证合计在最后一行,再通过自定义排序方法对整个工作表进行排序。
完成上述步骤后,还需要对前4列执行单元格合并操作。目前问题又来了:前4列单元格每一行与前一行全部一样时再进行合并,如果只是简单的选择单元格执行合并操作,你会发现第一列的日期同一日期的多个单元格只留下了一个日期,并没有与第二列(销售人员)、第三列(客户名称)和第四列(销售金额)的合并区域精准匹配,最终导致各列之间无法在行上保持对齐。实则,这样的结果并不符合我们的阅读习惯。
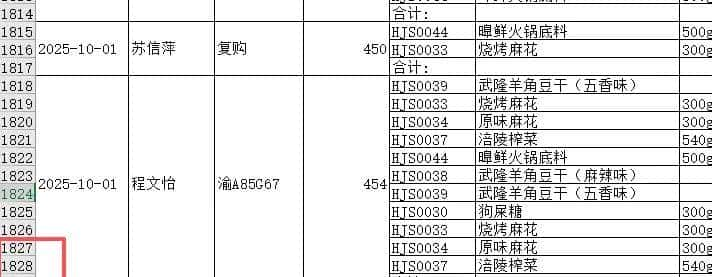
原文档有1829行数据,显然手动一个一个去完成是不可能的。目前,该我们的主角上场了——Python。
下面是用Python的pandas和openpyxl来解决这个问题的完成代码:
import pandas as pd
from openpyxl import Workbook
from openpyxl.styles import Border, Side, Alignment
from openpyxl.utils.dataframe import dataframe_to_rows
import time
strat_time = time.time()
df = pd.read_excel(r"D:销售单导出_20251009215739.xlsx",header=4)
df.iloc[:, :4] = df.iloc[:, :4].ffill()
df_group = df.groupby(["单据日期","销售人员","客户名称","销售金额"])
dfs = pd.concat([df_g for _,df_g in df_group])
wb = Workbook()
ws =wb.active
for r in dataframe_to_rows(dfs,index=False,header=True):
ws.append(r)
max_row,max_col = ws.max_row,ws.max_column
start_row = 2
for i in range(2, max_row + 2):
if i > max_row + 1 or
[ws.cell(row=i, column=c).value for c in range(1, 5)] !=
[ws.cell(row=start_row, column=c).value for c in range(1, 5)]:
if i - start_row > 1:
for c in range(1, 5):
ws.merge_cells(start_row=start_row, start_column=c, end_row=i - 1, end_column=c)
start_row = i
for row in range(1, max_row + 1):
for col in range(1, max_col + 1):
cell = ws.cell(row=row, column=col)
cell.border = Border(left=Side(style='thin'),right=Side(style='thin'),top=Side(style='thin'),bottom=Side(style='thin'))
cell.alignment = Alignment(horizontal="center", vertical="center")
wb.save(r"D:销售单导出.xlsx")
end_time = time.time()
print(f"合并完成!用时{end_time-strat_time:.3f}秒")先来看运行的效果:
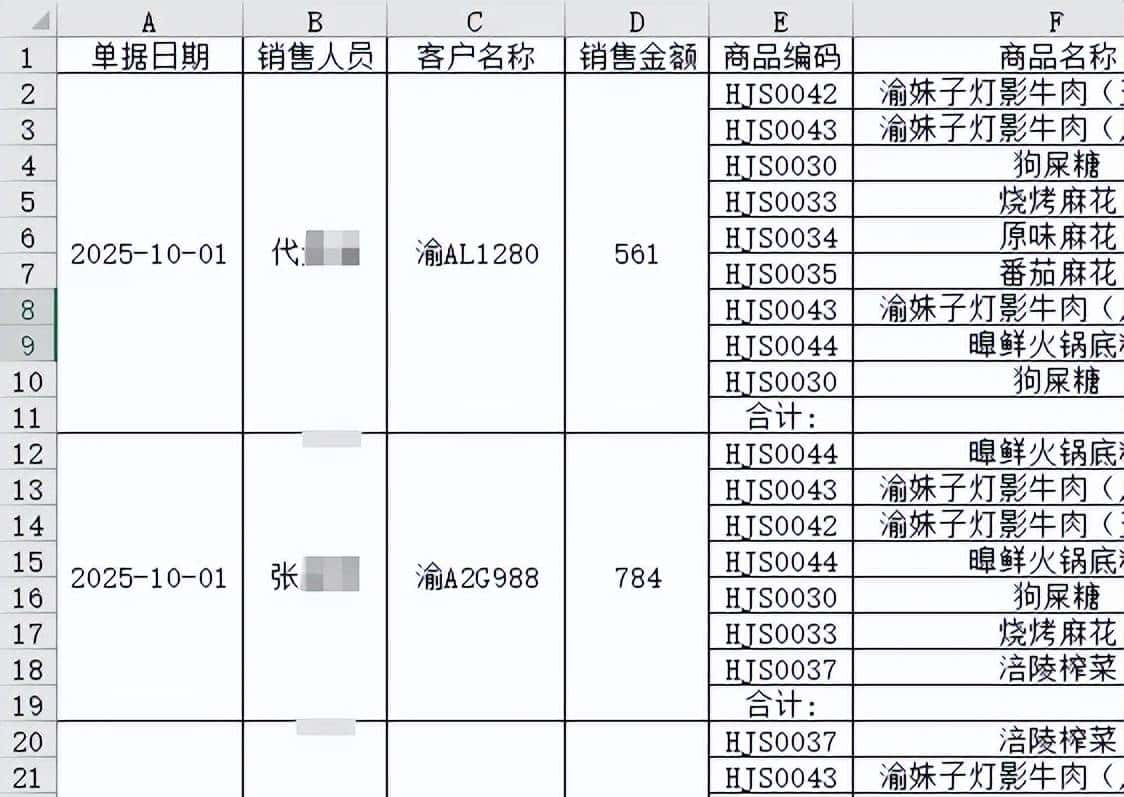
再来看一下代码的运行逻辑:
第1-5行导入所需要的模块。第3行是用于后续工作表格式的调整。第4行用于把pandas生成的DataFrame导入到openpyxl中。
第8-11行用于数据的读取、填充、分组与合并。第8行header=4表明将工作表的第5行设置为标题行。第9行df.iloc[:, :4]用于选择前4列,.ffill()表明用上一个有效数据的值来填充当前的空值。第10行使用groupby方法按照前4列进行分组。在默认情况下,groupby对按照分组的键进行升序排列,在这里按第1列“日期”升序排序,如果要保持原始顺序,则添加sort=False即可。第12行将分组的后的数据合并为新的DataFrame。
第13-16行把pandas整理后的数据写入openpyxl。第15行使用dataframe_to_rows方法将pandas格式的数据转化为一行一行的数据,参数index=False表明不需要原数据的索引列,header=True表明需要把DataFrame的表头插入到excel。第16行ws.append(r)逐行写入excel。
第19-26行实现单元格合并。第20-22行为条件判断前4列同行数据是否一样。句末的“”为续行符,表明这一行代码还没有结束,下一行是它的继续。这里使用了两列表推导式来进行判断是否一样。第23-26行对符合条件的单元格进行合并。
第28-32行代码是对工作表进行合并调整。第31行为单元格添加边框。第32行设置垂直和水平居中对齐。
第33-35行代码保存工作簿到指定路径,显示运行结果和时长。
在这里,通过pandas高效的数据处理,并结合openpyxl灵活的操作,仅仅35行代码就成功解决了合并单元格的排序的问题。即使后期需要进行维护,只需简单的修改即可。实则无论是整理报表、分析数据还是批量汇总,掌握必定的自动化技巧可以使我们的工作效率极大提升,让我们抽出更多的时间专注于更有创造性的任务。
希望这篇文章能够协助你理解其中的逻辑,并激发出更多的灵感。如果这篇文章对你有所启发,还请点赞、推荐+转发。你的鼓励是我更新的最大动力~~~


















暂无评论内容