
d_genocide被移除,Al Viro自己删的,到底为啥?
Linux 6.19内核上线了,这回不是啥新功能,也不是性能提升,而是把一个叫“d_genocide”的函数给干掉了。这名字听着吓人,“genocide”是种族灭绝的意思,放在代码里的确 有点过头。虽然只是个内部函数,普通用户根本看不到,但还是被人提了意见。
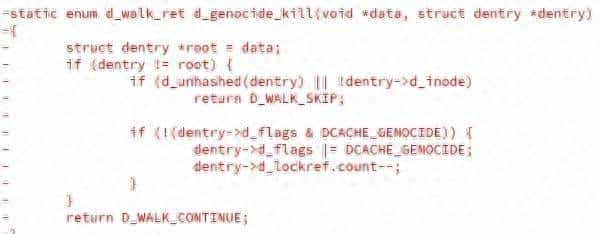
这事实则两年前就开始了。2023年那会儿,Linux内核开发者Al Viro提交了一段关于目录缓存(dcace)的代码更新。里面加了个函数,用来清理某些特殊文件系统残留的目录项。这些目录项由于设计缘由不会被自动回收,卸载文件系统的时候就得手动“清场”。
这个清理操作要一下子干掉一个目录和它下面所有的子目录、子文件,相当于整个树结构全删了。Al Viro就起了个名,叫d_genocide。意思是“目录大灭绝”。当时就有人在邮件列表里说这名字不合适。他自己也承认,这种彻底摧毁的操作很难找个完全中性的词来描述。
可问题是,这个词太敏感了。即便只出目前源码里,也不会影响用户使用,但它代表了一种态度。Linux社区这几年一直在搞术语改革。早几年就把“master/slave”改成了“primary/secondary”,把“blacklist/whitelist”换成了“blocklist/allowlist”。目前连“d_genocide”也不行了,说明标准越来越严。
有趣的是,这次删掉它的还是Al Viro本人。他在2025年12月提交了一个补丁,正式把d_genocide和配套的DCACHE_GENOCIDE宏从内核里清了出去。不是别人逼他,是他自己动手改的。
他是怎么改的呢?实则就是重构了一下文件系统卸载的逻辑。原来那种需要“灭绝”式清理的情况,目前统一交给了shrink_dcache_for_umount这个函数处理。它会遍历所有持久化的dentry,去掉它们的特殊标记,并减少引用计数。
这样一来,原来需要单独写一套“极端手段”的地方,目前也能用常规流程解决了。kill_litter_super这个函数的行为变得跟kill_anon_super一样简单直接。所谓的“genocide”逻辑,自然就没存在的必要了。
所以说,这不仅仅是换个名字那么简单。它是代码设计上的优化。以前是“有病才吃药”,目前是“人人都体检”,预防比治疗更重大。功能没变,实现更干净了。
有人可能会觉得,程序员不就爱搞这些文字游戏吗?起个猛一点的名字显得酷。但实则不是这么回事。内核开发是很严肃的事,每个符号名都得思考长期维护成本。像“genocide”这种词,容易引发误解,也容易让新人望而生畏。
而且,这年头开源项目面向全球,语言敏感性比十年前强太多了。一个美国开发者觉得没什么的词,可能对其他地区的人就是种冒犯。特别是历史背景复杂的地方,这种词很容易踩雷。
Al Viro作为资深内核维护者,肯定也意识到了这一点。所以他后来没再坚持,反而主动推动了移除工作。从最初辩护这个命名,到最后自己删代码,也算是经历了一个转变过程。
这事儿还说明一个问题:技术讨论和文化环境是分不开的。你以为写代码只需要管逻辑对不对,实则命名、注释、文档这些软性的东西,同样重大。一个好名字能让别人更容易理解你的意图。
反过来,一个糟糕的名字,哪怕功能再正确,也会成为项目的负担。d_genocide存在了两年多,期间没人说它功能有问题,问题全出在名字上。最后还得花时间专门去改,浪费人力。
更别说,这次改动实则是把机制理顺了。以前为了处理特殊情况,写了个暴力函数。目前通过调整流程,把特殊情况变成了常规操作。这才是真正的进步。
所以你看,表面看是个“政治正确”的事,实际上促进了代码质量的提升。有时候,外部的压力反而能推动内部的优化。这在开源世界里还挺常见的。
普通用户当然感受不到这些变化。系统该怎么用还是怎么用,开机速度不会变快,内存也不会多出来几百兆。但底层的代码变得更清晰、更一致了。
这也反映了Linux内核社区的一种成熟。不光追求性能和稳定性,也开始重点关注协作的可持续性。谁都不想在一个充满争议术语的代码库里工作。
这事就这么过去了。d_genocide成了历史,没人再提。下次你要是搜这个函数名,估计只能在老版本的源码里找到了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











