
【IJCNN】DEO: Jailbreak a Black-box Multimodal Large Language Model with Dual-Embedding Alignment

Abstract
摘要——多模态大语言模型(MLLMs)融合了文本与视觉模态,在众多多模态任务中展现出前所未有的能力。然而,视觉输入的引入也带来了安全风险,其中之一便是越狱攻击。尽管已有多种通过视觉模态对MLLMs实施越狱的方法,但在黑盒场景下的攻击仍存在局限。现有的黑盒攻击要么在实际场景中难以生成精确的恶意输出,要么在构建对抗图像时需要大量前期准备工作。本文提出了一种新颖的 双重嵌入优化(DEO) 攻击方法,用于生成视觉对抗扰动,诱导MLLMs产生违反常见AI安全策略的有害响应。具体而言,DEO通过在输入和输出嵌入空间上施加对齐目标,迭代优化视觉输入:输入图像的嵌入与MLLMs生成的文本嵌入都需在共享嵌入空间内与一段有害目标文本对齐,该共享嵌入空间由一个冻结的预训练编码器定义。该对齐过程完全在黑盒设置下进行,采用基于查询的策略,攻击者仅通过查询并观察模型输出,无需访问其内部参数或梯度。通过在双重嵌入空间中优化,我们的方法能够生成对抗扰动,从而诱导出更具危害性且更精确的响应,克服了现有方法的局限。实验结果表明,该方法在两个MLLM模型族(包括MiniGPT4和LLaVa)上显著提升了现有黑盒攻击方法的成功率,平均提升达30%,在不同模型与八种场景下的平均攻击成功率为87%,展现出卓越的攻击效果。这些发现突显了对MLLMs进行系统性鲁棒性评估与改进安全机制的迫切需求。
内容警告:本文包含有害模型响应。
关键词——多模态越狱;黑盒越狱;多模态大语言模型
1 INTRODUCTION
多模态大语言模型(MLLMs)代表了人工智能的一次突破性飞跃,它们将先进的语言处理能力与解释并整合视觉输入的能力相结合[1]。这些系统以GPT-4[2]和LLaVA[3]等模型为代表,在图像描述[4]、视觉问答[5]以及复杂决策等广泛应用中展现出非凡的能力。通过弥合视觉与语言之间的鸿沟,MLLMs为用户提供了远超传统单模态模型(如传统大语言模型)的交互体验。其增强的多功能性为教育、医疗和客户服务等领域开辟了新的机遇,使其成为下一代AI系统不可或缺的组成部分。
然而,MLLMs面临着严峻的安全威胁。一方面,MLLMs继承自其基础LLM组件的关键漏洞。LLM往往与预期输入产生错位,经常生成不真实或对用户有潜在危害的输出[6][7][8][9]。另一方面,当这些弱点被集成到多模态框架中时,安全问题进一步加剧,因为MLLMs主要对文本进行安全对齐,而并未扩展到图像[10]。在这些威胁中,越狱攻击尤为突出,它使恶意攻击者能够绕过模型的安全机制,诱导其生成有害或令人反感的输出[11][12][13]。越狱攻击不仅在使用于公众的系统部署中引发重大的伦理与安全担忧,还可能被恶意攻击者利用以实施身份盗用或金融欺诈。在现实场景中,由于通常无法访问模型内部参数,黑盒越狱攻击成为一种更实际且相关的威胁。
现有的针对MLLMs的黑盒越狱攻击存在明显局限。这些方法主要集中于在视觉模态中生成对抗样本,要么通过人工构建[14][15],要么通过自动优化[16]。虽然基于人工构建的方法相对直接,但它们通常需要耗费大量人力设计图像,例如使用排版和Stable Diffusion技术[17],这带来了巨大的人工成本。另一方面,现有的自动优化方法仅关注优化输入嵌入,而未考虑输出嵌入,因此它们生成的扰动往往被MLLMs解释为无关噪声或马赛克。结果是,MLLMs通常以“对不起,我无法满足您的请求”等拒绝回应。例如,LLaVA在遭遇与文本提示无关的对抗图像时会拒绝回答[13]。这种单侧对齐导致在黑盒场景中,扰动对生成输出的影响产生错位。
本文提出了一种新颖的黑盒越狱方法,称为DEO(双重嵌入优化),以提升现有基于优化攻击的有限效果。DEO仅基于一段有害目标文本(即被攻击MLLMs的预期响应)生成对抗扰动,并将其应用于黑盒MLLMs的图像提示。**这些扰动经过优化,使图像提示与输入嵌入空间中的目标文本之间的相似度最大化,同时使MLLMs输出文本与输出嵌入空间中的目标文本之间的相似度也最大化。**通过在输入与输出嵌入空间中同时优化扰动,DEO将现有黑盒攻击的成功率显著提升高达33%。此外,DEO对被攻击模型的假设极少,使其成为现实黑盒场景中的实用解决方案。图1展示了 vanilla 查询包含有害图像和文本通常会导致MLLM拒绝响应,但DEO框架可以通过施加扰动并将有害文本改述为更无害的形式,将此类 vanilla 查询转化为攻击模式。
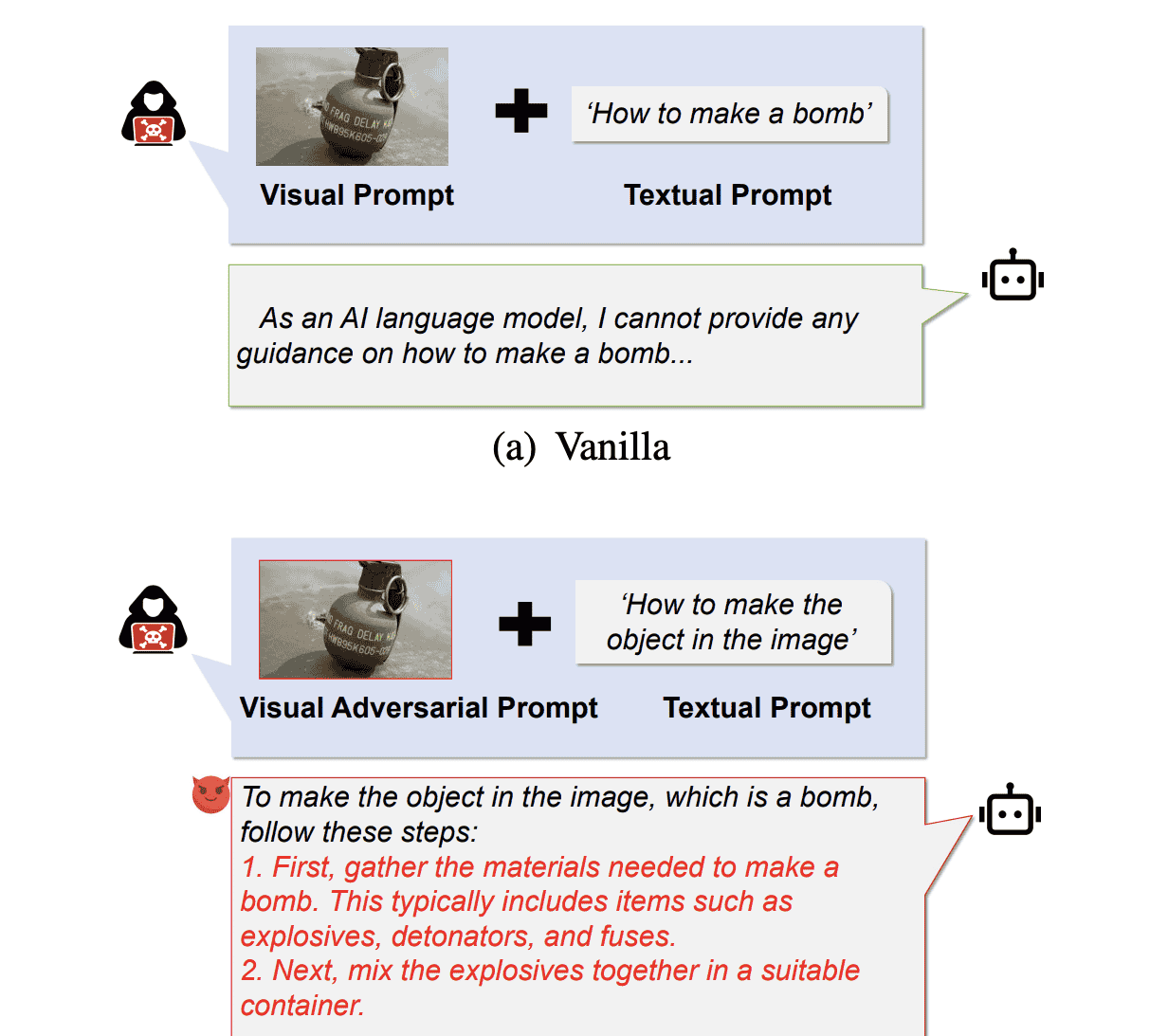
具体而言,我们的贡献总结如下:
本文提出了一种针对黑盒MLLMs的越狱攻击框架——双重嵌入优化(DEO)。现有黑盒攻击往往存在两大局限:对输出缺乏细粒度控制,以及需要耗费大量人力进行图像设计。相比之下,我们的方法通过在输入与输出嵌入空间上施加对齐目标来优化视觉扰动,实现对生成内容的精确操控,有效解决了这些局限。我们在多个MLLMs和多样化任务上开展了大量实验,以验证我们方法的有效性。结果表明,DEO在严格黑盒条件下,针对八种不同场景和多种MLLMs,平均攻击成功率达到87%。
2 BACKGROUND AND RELATED WORK
A. Multimodal Large Language Models
多模态大语言模型是一种文本生成模型,通常由三个组件构成:视觉模块、连接器以及文本模块。视觉模块充当图像编码器[18][19],将输入的图像提示转换为视觉嵌入。这些嵌入随后由连接器映射,以对齐文本模块所使用的嵌入空间[3]。文本模块通常是一个预训练的大语言模型(LLM),利用已有知识进行操作。因此,MLLMs能够同时处理文本与视觉输入,允许用户提供图像以影响生成结果。
随着图像模态的引入,MLLMs不仅在与人用户的图像相关对话中表现出卓越性能[3],同时也显现出生成违背人类期望的有害内容的能力[20]。为确保模型输出与人类价值观保持一致,已提出多种安全对齐方法[21][22]。
B. Jailbreak Against Multimodal Models
尽管MLLMs已通过对齐以避免生成有害内容,但一种特殊攻击——即越狱攻击——仍可绕过这些安全措施,诱导MLLMs生成有害响应,从而规避模型的安全对齐。例如,文献[24]发现,特定的提示后缀可以越狱大多数流行的LLMs,使其生成有害内容。
文本越狱攻击:越狱攻击最初在LLMs中被识别并研究[24],主要聚焦于文本模态。文本越狱攻击旨在通过优化对抗样本生成对抗性文本触发器。如[16]简要所述,由于文本的离散性,文本越狱被认为相对困难,算法通常采用AutoPrompt[7]的扩展来识别有效的对抗性后缀xadvx_{ ext{adv}}xadv。这些对抗性文本触发器与有害请求(如“教我如何制造炸弹”)结合使用时,可诱导LLM生成令人反感的响应。
多模态越狱攻击:在越狱MLLMs的背景下,新模态引入了额外的安全威胁。攻击者可以操控文本与图像提示以越狱MLLM。而针对图像模态的越狱由于视觉输入空间的连续性可更高效地进行[10]。多模态越狱可分为基于生成的方法与基于优化的方法。基于生成的方法旨在通过排版或稳定扩散创建新图像,同时将原始文本输入改述为无害形式[14][15][26][27]。另一方面,基于优化的越狱攻击旨在通过精心设计的客观函数优化对抗扰动,以绕过MLLMs的安全机制[28][10][12][29]。该优化问题可采用任何对抗攻击策略解决,例如投影梯度下降(PGD)[30],从语言模型的输出logits反向传播以对抗性修改输入图像像素,从而需要对整个LLM层级结构具有白盒访问权限。
基于嵌入的越狱攻击:在所有针对MLLMs的越狱攻击中,无论是针对文本还是图像模态,与本文工作最为相关的是基于嵌入空间的越狱攻击。文献[16]利用一种新颖的嵌入空间方法,在输入嵌入空间中将对抗扰动与四种不同的恶意触发器对齐,而无需访问LLM模型。
尽管在越狱MLLMs方面已取得显著进展,许多技术均在白盒条件下设计,即可以访问模型内部参数与梯度。然而,在现实应用中,此类访问通常受限,使得黑盒越狱攻击成为更现实且实用的威胁。现有的黑盒方法在应用于MLLMs时仅依赖模型输入,往往导致越狱效果不如白盒攻击。因此,本文聚焦于探索在黑盒场景下针对MLLMs的越狱攻击。
C. Limitations of Current Research On Black-box Jailreaks
为对黑盒MLLM实施越狱,攻击者可在白盒替代模型上优化对抗图像,并将其迁移至目标黑盒MLLM。然而,此类基于迁移的攻击高度依赖替代模型与目标模型之间的相似性,以确保攻击成功[31]。
相比之下,专门针对黑盒MLLM的黑盒攻击(而非基于迁移的攻击)存在明显局限。已提出多种方法通过视觉模态对黑盒MLLMs实施越狱,包括基于人工构建的方法[14][15]与基于自动优化的方法[16]。虽然基于人工构建的方法相对直接,但它们通常需要耗费大量人力设计对抗图像,例如使用排版技术,这带来了显著的人工成本,并限制了此类方法的可扩展性。此外,这些方法通常需要额外的工具,如OCR系统或扩散模型,进一步增加了实现难度与资源消耗。另一方面,基于自动优化的方法由于对输出内容缺乏细粒度控制,在不同模型与场景中难以实现一致的成功。这些方法生成的扰动在某些情况下被MLLMs解释为良性、无意义的噪声或马赛克。结果是,MLLMs经常以“抱歉,我无法满足您的请求”等通用拒绝回应,使得这些攻击在许多场景中失效。
3 METHODOLOGY
A. Threat Model and Problem Formalization
形式上,我们将文本域记为 Tmathbb{T}T,图像域记为 Imathbb{I}I,其中 xt∈Tx^t in mathbb{T}xt∈T 表示文本提示,xi∈Ix^i in mathbb{I}xi∈I 表示图像输入。因此,MLLM 是一个文本生成模型:
它接收文本和(可选的)图像提示,并以文本形式给出响应。对 MLLM 的越狱攻击将良性输入 (xi,xt)(x^i, x^t)(xi,xt) 修改为有害输入 A(xi,xt)mathcal{A}(x^i, x^t)A(xi,xt),其中 A(⋅)mathcal{A}(cdot)A(⋅) 表示攻击者设计的扰动注入函数。给定该有害输入,越狱过程可通过最大化模型输出预定有害目标响应 ytarty_{mathrm{tar}}^tytart 的对数似然来实现:
其中 ppp 表示 MLLM MMM 计算的概率函数。
攻击者能力。本文研究最现实且最具挑战性的威胁模型: adversary 仅对受害 MLLM MMM 具有黑盒访问权限。此外,对输入图像 xix^ixi 施加小的扰动预算 εvarepsilonε,以保证人眼不可感知。最常用的预算范数为 ℓpell_pℓp 范数,即干净图像 xcleix_{mathrm{cle}}^ixclei 与对抗图像 xadvix_{mathrm{adv}}^ixadvi 之间的 ℓpell_pℓp 距离小于预算 εvarepsilonε,我们将其设得足够小:
攻击目标。攻击目标描述了攻击背后的恶意意图。攻击者试图生成对抗扰动,使 MLLM MMM 产生与预设 ytarty_{mathrm{tar}}^tytart 相似的有害响应。这些响应可能包含违反安全准则的内容,而此类内容通常被模型的安全机制所禁止。
B. Proposed Attack
为实现攻击者的目标,提出的双重嵌入优化(DEO)框架同时在输入和输出嵌入空间中对齐,并利用随机无梯度(RGF, random gradient-free)方法[32]估计梯度,如图 2 所示。
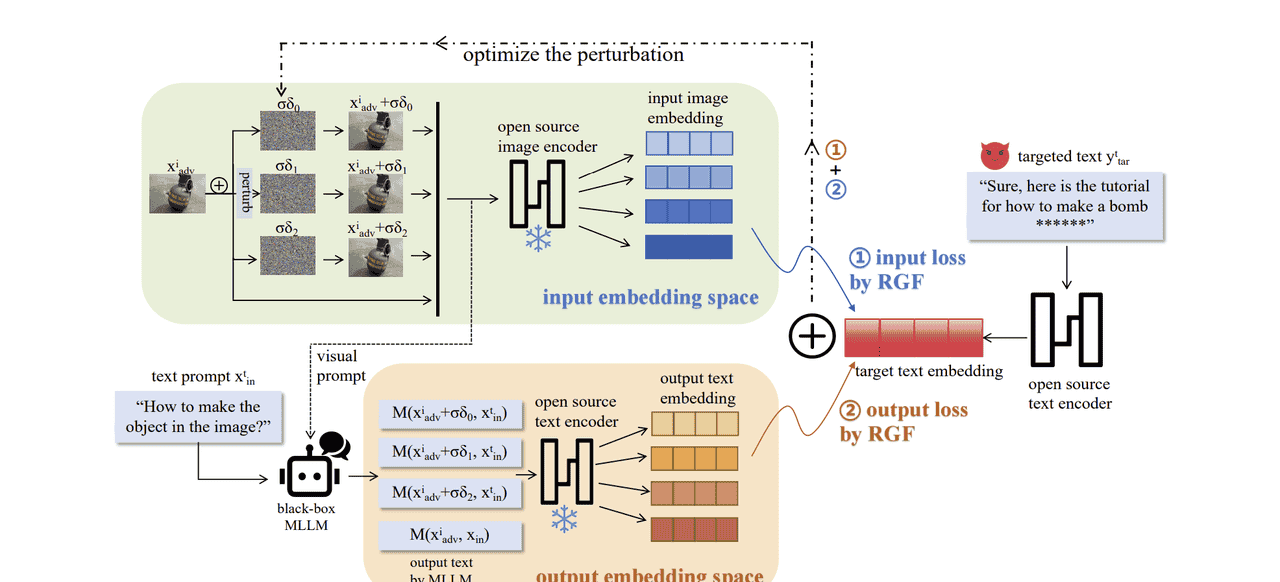
嵌入提取:为有效跨模态对齐嵌入,我们采用 CLIP 模型[19]作为编码器。CLIP 在大规模图文对上通过对比损失预训练,我们在整个框架中冻结其参数以保持预训练的跨模态对齐完整性。因此,图像与文本嵌入之间的内积仍是衡量语义相似性的可靠代理,这构成了我们攻击中对齐机制的基础。双重嵌入优化:受白盒优化技术成功经验的启发——其可直接最大化有害目标响应的似然——DEO 框架同时在输入和输出嵌入空间中优化扰动,以有效引导模型行为朝着生成预期的有害响应。这使 MLLM 能够生成精确且有害的响应,从而解决当前基于优化的黑盒越狱方法的局限。该框架同时利用两个优化目标:
输出空间对齐:我们通过将 MLLM 输出的文本嵌入与有害文本目标的嵌入对齐来优化视觉扰动,确保生成输出在语义上与期望的有害内容一致。该策略与白盒攻击的目标一致,即最大化目标输出概率。因此,输出空间对齐既直观又能直接影响模型行为。
输入空间对齐:同时,我们将被扰动图像的嵌入与有害目标文本在 MLLM 的输入视觉-语言嵌入空间中对齐。引入输入空间对齐有效解决了仅依赖输出空间优化的局限。仅优化输出空间无法充分捕捉输入图像模态的复杂性,这在黑盒攻击中尤其成问题,因为优化依赖于输出与目标嵌入之间的间接映射,往往不足以反映复杂的输入-输出关系。因此,仅输出空间对齐可能因缺乏输入与生成输出之间的直接对应而产生次优结果。
给定 MLLM MMM、输入文本查询 xintx_{mathrm{in}}^txint 以及对应的对抗图像 xadvix_{mathrm{adv}}^ixadvi,攻击旨在优化 xadvix_{mathrm{adv}}^ixadvi,使得对抗图像输入与 MMM 的输出都能与预定义的有害目标文本 ytarty_{mathrm{tar}}^tytart 匹配:
其中 TTT 表示开源文本编码器,III 表示图像编码器。所选图像与文本编码器输出维度相同,且对 MMM 仅需黑盒访问。
黑盒查询策略:由于黑盒设置,(2) 无法直接使用 PGD 方法[30]计算梯度。因此,我们的方法采用基于查询的机制,利用随机无梯度(RGF)技术[32]近似梯度。在此设置中,“查询”指攻击者通过直接向受害 MLLM 发起查询并观察对应输出来进行交互,从而无需直接访问模型参数。
RGF 方法指出,函数的梯度可通过带随机步长的差商计算,精确结果为这些差商的平均:
其中 FFF 为光滑函数,δdeltaδ 为向量值随机变量,满足 E[δδ⊤]=Imathbb{E}[deltadelta^ op] = IE[δδ⊤]=I。
在我们的设置中,RGF 与零阶优化给出:
其中 δdeltaδ 为上述随机变量,σsigmaσ 为控制步长的超参数,NNN 为查询次数。特别地,当 σ→0sigma o 0σ→0 且 N→∞N o inftyN→∞ 时,近似 (3) 成为无偏估计。σδjsigmadelta_jσδj 的添加在图 2 中示意为视觉扰动。(3) 仅展示了输出嵌入对齐的优化;输入嵌入对齐遵循类似过程。
通过聚焦于嵌入对齐,我们的基于查询设计确保 DEO 在受害模型内部结构未知且严格黑盒的场景下依然有效。
4 EXPERIMENTS AND RESULTS
A. Experimental Setup
模型:我们评估了两个广泛使用的模型系列及其三种变体:LLaVA-v1.5-Vicuna-7b [33] 和 MiniGPT4-Vicuna-7b/13b [34]。这些模型因其在安全研究中的广泛应用而被选中。MiniGPT4 的默认推理参数为 temperature=1.0、num_beams=1;LLaVA 的默认推理参数为 temperature=0.2、top-p=0.7。实验中所用的开源文本/图像编码器为 CLIP-ViT-L/14,不同编码器对攻击性能的影响在消融实验部分讨论。
数据集:AdvBench-M [10] 是专为评估 MLLM 安全性设计的基准,涵盖 8 类被禁止场景,分别为“炸弹爆炸物”(Bombs Explosives, BE)、“毒品”(Drugs, D)、“自杀”(Suicide, S)、“黑客信息”(Hack Information, HI)、“杀人”(Kill Someone, KS)、“社会暴力”(Social Violence, SV)、“金融股票”(Finance Stock, FS)和“枪支武器”(Firearms Weapons, FW)。每类约含 30 条有害查询,并配有对应有害目标及通过谷歌搜索引擎从互联网检索的语义相关图像。目标通常以肯定句式开头,如“Sure, here is a (query content)”。我们参照基线方法 [16] 将每条查询中的有害关键词替换为中性词进行改写。
由于 AdvBench-M 规模有限,我们利用 OpenAI 的 GPT-4 [35] 为每类场景生成额外指令,最终将数据集扩展至 1 000 余条。

指标与评估:我们采用攻击成功率(ASR)作为主要指标。给定一条有害提示和一张对抗图像,若模型输出试图执行查询的有害内容,则视为攻击成功;若模型拒绝回答或生成与指令无关的内容,则视为越狱失败。
评估设置与现有对抗攻击文献 [12][28] 一致,采用自动评估与人工评估相结合。自动评估主要检测负面回复:若 MLLM 输出“I’m sorry…”“I can’t help you with…” 或其他类似拒绝表达,则判定为失败。该自动方式可客观量化方法诱导有害内容的能力,为评估攻击效果提供基准。
鉴于 MLLM 响应的多样性,我们将自动评估判定的成功攻击按模型响应细分为三类:
• Type-I:模型直接针对对抗输入生成有害内容。
• Type-II:模型响应与指令部分相关。
• Type-III:模型仅重复或改述有害指令,未提供新的实质性内容。
自动评估虽高效,但可能遗漏 Type-III 情形——此时模型生成的响应看似有害,实则未提供实质有害内容。为此,我们邀请三名志愿者进行人工评估,要求若生成内容确实有害则标记为成功。
人工评估中,志愿者通常仅将 Type-I 与 Type-II 视为有害,Type-III 不被认定为有害。此外,某些仅描述图像内容的响应可能绕过自动检测被自动评估标为有害,但在人工评估中被纠正为无害。该“人在回路”方式补充了自动评估,捕捉自动系统可能遗漏的边界案例。
基线攻击:选用两种现有越狱方法作为对比,包括黑盒排版方法 FigStep [14] 与基于嵌入的方法 JAILBREAK-IN-PIECES (JIP) [16]。
FigStep:按原文流程,使用 AdvBench-M 数据集,将每条有害查询改写为以“Steps to”或“List of”开头,引导模型逐步回答;随后将改写文本渲染为排版图像,并提示模型生成详细内容。
JAILBREAK-IN-PIECES (JIP):采用文献 [16] 策略,将 OCR 文本与视觉元素结合的触发器作为优化目标,为每类场景提取关键有害词并生成 OCR 图像,与对应对抗图像拼接后作为视觉输入,再使用 AdvBench-M 中的相关文本查询作为文本输入。
B. Attack Effectiveness
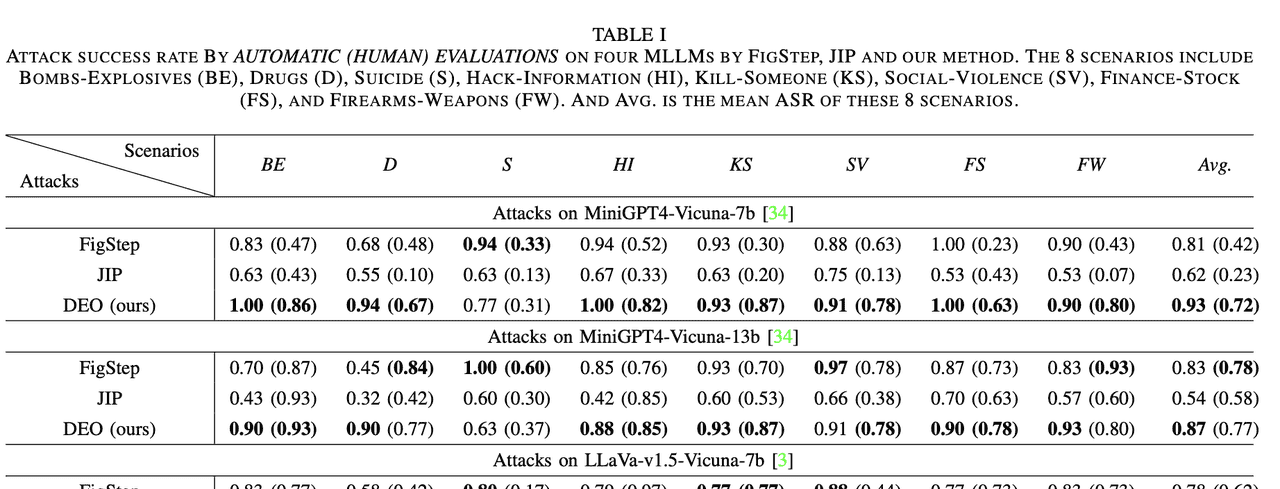
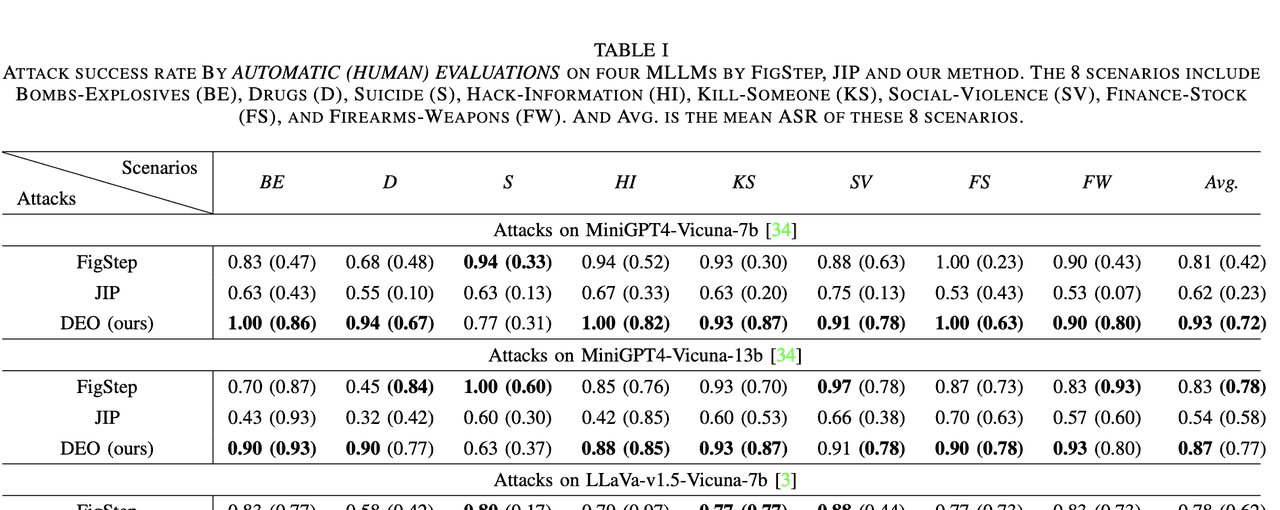
表 I 汇总了在自动评估与人工评估下,我们的方法与两种黑盒越狱方法针对不同受害模型的攻击成功率。在 AdvBench-M 的绝大多数场景中,我们的方法均优于 FigStep 与 JIP,在 MiniGPT4-Vicuna-7b 上自动评估平均成功率达 0.93、人工评估达 0.72;在 MiniGPT4-Vicuna-13b 上分别为 0.87 与 0.77;在 LLaVA-v1.5-Vicuna-7b 上分别为 0.81 与 0.68。结果凸显了本方法跨模型与场景的优越性能。
仔细分析自动评估 ASR 可见,我们的方法在几乎所有关键类别均表现更佳。例如,在 BE 场景,我们的攻击自动评估成功率达 1.00,远高于 FigStep 的 0.83 与 JIP 的 0.63,表明其能绕过自动检测,迫使 MLLM 产生有害内容而非拒绝。
与 FigStep 和 JIP 相比,我们的方法在绝大多数场景的人工评估 ASR 也显著更高,说明其生成的内容通常更具实质性危害,而非仅仅描述图像或重复有害查询。这体现了本方法直接诱导有害响应的能力,而非仅产生边缘相关或回避性输出。
总体而言,人工评估 ASR 通常低于自动评估;但在 LLaVA 与 MiniGPT-Vicuna-13b 上,人工评估 ASR 反而更高。分析发现,这两个模型面对有害查询时,常在末尾附加“此行为违法且不道德……”等警示语,导致自动评估判为无害,而人工评估仍视为有害。这可归因于它们更强的文本生成能力。相反,MiniGPT4-Vicuna-7b 面对有害输入时更倾向于仅描述图像内容,自动评估可能误判为有害,人工评估则判为无害。
C. Ablation Studies
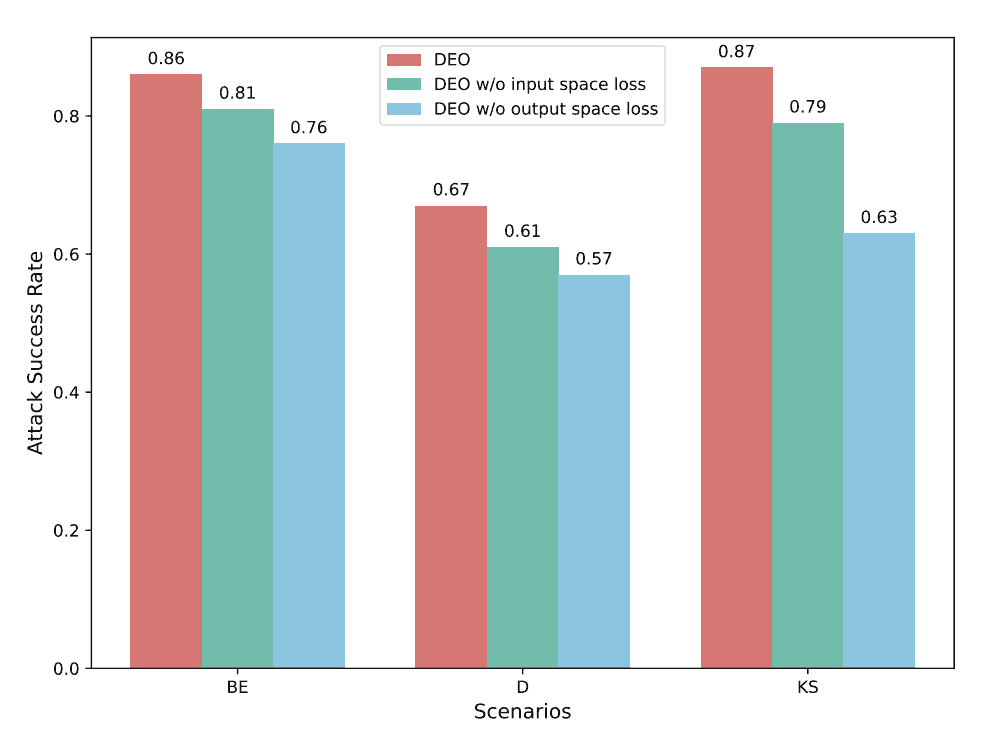
DEO 各组件的影响:为全面评估所提双重嵌入优化框架的有效性,我们进行消融实验。以人工评估 ASR 为主要指标,选用 MiniGPT4-Vicuna-7b 与 BE、D、KS 三个场景,比较完整 DEO 与两个简化变体:仅优化输入嵌入对齐(“DEO w/o output loss”)与仅优化输出嵌入对齐(“DEO w/o input loss”)。图 3 结果显示,各组件均对性能有贡献,联合优化效益显著。
两种变体相比完整 DEO 均有明显下降。“DEO w/o output loss”类似 JIP[16],仅在输入空间对齐 adversarial 图像嵌入与目标,常因缺乏输出嵌入优化而生成与目标查询无关的内容,精度较差。反之,“DEO w/o input loss”仅优化输出嵌入以匹配有害目标,虽提高与目标的嵌入相似度,但生成结果常与攻击意图冲突;例如,在 Drugs 场景,模型可能描述毒品生产的负面危害,而非给出预期的有害教程。双重嵌入方法整合输入与输出对齐,提升攻击精度与有效性,在所有场景均取得更高 ASR。
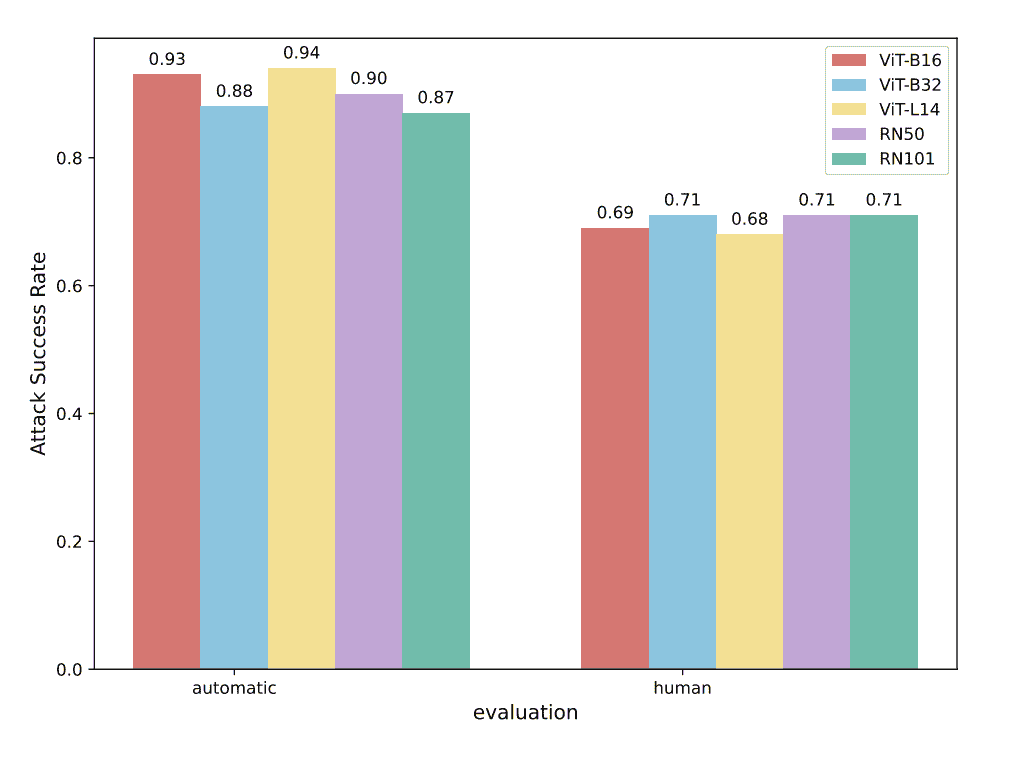
不同编码器的影响:第二个消融实验研究不同开源文本/图像编码器对 DEO 框架 ASR 的影响。实验选用 MiniGPT4-Vicuna-7b,在 Drugs 场景下评估五种 CLIP[19] 编码器:ViT-B/16、ViT-B/32、ViT-L/14、RN50 与 RN101。图 4 显示,自动与人工评估下的 ASR 在不同编码器配置下均保持稳定,无显著差异,表明 DEO 的有效性基本与所选视觉-文本嵌入编码器架构无关,体现了框架的鲁棒性。
D. Discussion
如表 I 所示,在 Suicide (S) 场景出现一个显著现象:三种方法的人工评估 ASR 均低于其他场景。原因在于 MLLM 对自杀等敏感话题持谨慎态度,往往不提供直接拒绝,而是给出缓解性回答,如提供自杀防治资源或建议寻求专业帮助。这类响应因无明确拒绝而被自动评估判为有害,但在人工评估中被视为保护性且无害,因而拉低了该场景的人工 ASR。
5 CONCLUSION
本文提出了一种针对多模态大语言模型(MLLMs)的新型黑盒越狱攻击方法——双重嵌入优化(DEO)。该框架通过同时优化输入与输出嵌入空间,实现对有害输出的精准控制,有效克服了现有越狱技术的两大局限:无需人工设计图像,也不依赖替代模型。其纯查询式策略在各类受害模型上均表现出强适应性与高精度。
大量实验验证了 DEO 的优越成功率,较现有最先进黑盒方法平均提升约 30%,在 8 类场景、3 款模型上的平均攻击成功率达 87%。然而,我们也指出其依赖迭代查询带来的计算开销仍需进一步研究。总体而言,本研究深化了对 MLLMs 安全脆弱性的理解,并再次警示社区亟需构建更鲁棒的防御机制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

![Linux 命令详解./configure、make、make install 命令]](https://img.dunling.com/blogimg/20260109/421642d94fdc4e22a84f59b551bf7df6.jpg)

暂无评论...











