
在企业级数据查询领域,自然语言转SQL(NL2SQL)技术正成为智能数据分析的核心引擎。想象这样一个场景:业务人员无需编写复杂SQL,只需用自然语言提问“2024年上海浦东新区评分前10的酒店订单量”,系统就能自动生成精准的SQL查询并返回结果——这背后,是NL2SQL技术的“魔法”。
但现实中,这项技术的落地并非一帆风顺。在【ChatMetrics】技术可行性调研中,我们发现一个关键矛盾:模型能力直接决定NL2SQL准确度——满血版在线大模型(如6710亿参数的deepseek-r1)虽强,却面临成本高、不可控的痛点;而本地小模型(如70亿参数的
DeepSeek-R1-Distill-Qwen-7B)能力有限,难以满足复杂查询需求。
这场“鱼与熊掌”的博弈,最终通过模型蒸馏技术找到了破局点。本文将完整复现我们的探索过程:从本地部署小模型,到用经典NL2SQL数据集Spider训练蒸馏,最终验证“本地蒸馏模型在特定场景下超越满血大模型”的可行性。

一、为什么选择“蒸馏”?大模型落地的现实困境
在NL2SQL技术探索中,我们曾优先验证了“使用满血版在线模型+优化Prompt”的方案(即路径1.A)。实测数据显示,满血模型在复杂查询(如多表关联、嵌套子查询)的准确率比本地小模型高15%-20%。但很快,我们遇到了三个“不可承受之重”:
- 成本之痛:满血模型API调用费用高达0.5元/千token,企业级日均10万次查询的月成本超15万元;
- 可控性差:在线模型受限于服务商API策略,无法定制化优化(如行业专有名词适配);
- 延迟风险:网络波动时,API响应时间从200ms骤增至2s,严重影响用户体验。
相比之下,本地小模型虽成本低(单卡GPU即可运行)、可控性强(可自主优化),但直接使用的准确率仅65%(满血模型为82%)。此时,模型蒸馏技术进入视野——通过“大模型知识迁移”,让小模型“偷师”大模型的推理能力,成为平衡性能与成本的关键。
二、从0到1:本地蒸馏模型的完整实践路径
我们的目标很明确:通过蒸馏技术,将70亿参数的
DeepSeek-R1-Distill-Qwen-7B小模型,在经典NL2SQL数据集Spider上训练为“专业版”模型,使其准确率超越满血大模型。
1. 第一步:本地部署小模型——硬件与工具的选择
模型蒸馏的前提是“有模型可训”。我们选择了
DeepSeek-R1-Distill-Qwen-7B作为基准模型,这是一款70亿参数的轻量级大模型(相比6710亿参数的满血版,体积缩小90%),适合本地GPU(如NVIDIA A100 40G)部署。
部署工具链:
- Ollama:一款开源的本地大模型运行工具,支持一键启动多种模型;
- LLaMA-Factory:专注于大模型微调的开源框架,提供数据处理、训练、导出全流程支持;
- llama.cpp:用于将Hugging Face模型转换为Ollama兼容格式,适配本地推理。
部署步骤(以Linux服务器为例):
# 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 启动基准模型(首次启动会自动下载,约需10GB存储)
ollama run deepseek-r1:32b # 测试用32B版本,实际蒸馏用7B版本需单独下载权重注:7B模型需手动下载Hugging Face仓库的config.json、model.safetensors等文件,因服务器带宽限制,下载耗时约30分钟。
2. 第二步:数据集预处理——让“自然语言问题”与“SQL答案”对齐
NL2SQL的核心是“问题-查询”对的训练。我们选用了经典数据集Spider,其包含10,187条真实业务场景的自然语言问题及对应的SQL查询,覆盖多表关联、子查询、聚合函数等复杂场景,是验证NL2SQL能力的“黄金数据集”。
预处理目标:将Spider的原始JSON格式(如{“question”: “列出预算超过100万的部门”, “query”: “SELECT name FROM department WHERE budget > 1000000”})转换为LLaMA-Factory支持的“指令微调(SFT)”格式,即:
{
"instruction": "Using the database 'spider', translate the following natural language question into a SQL query.",
"input": "列出预算超过100万的部门",
"output": "SELECT name FROM department WHERE budget > 1000000"
}关键脚本解析(Python):
def convert_spider_to_llamafactory(spider_data):
converted_data = []
for item in spider_data:
instruction = f"Using the database '{item['db_id']}', translate the following natural language question into a SQL query."
input_text = item["question"]
output_text = item["query"]
converted_item = {
"instruction": instruction,
"input": input_text,
"output": output_text
}
converted_data.append(converted_item)
return converted_data这一步的核心是为模型添加“数据库上下文”(如db_id),让模型理解问题对应的表结构,避免生成“无的放矢”的SQL。
3. 第三步:模型蒸馏训练——“小模型”吸收“大模型”知识
训练是蒸馏的核心环节。我们采用LoRA(低秩适应)微调技术,在保持原模型参数不变的前提下,仅训练少量新增参数(秩为8),大幅降低计算成本(相比全参数微调,显存占用减少70%)。
训练配置关键参数(LLaMA-Factory命令):
nohup
llamafactory-cli train
--model_name_or_path ~/DeepSeek-R1-Distill-Qwen-7B # 基准模型路径
--output_dir ~/DeepSeek-R1-Distill-Qwen-7B__Spider/train # 输出路径
--dataset_dir data
--dataset llama_train_spider # 预处理后的数据集
--cutoff_len 2048 # 最大输入长度(覆盖长问题)
--stage sft # 指令微调阶段
--do_train True
--preprocessing_num_workers 16 # 多线程加速数据处理
--template deepseek3 # 匹配模型结构的模板
--learning_rate 5e-05 # 学习率(平衡收敛速度与稳定性)
--num_train_epochs 10.0 # 训练轮次(覆盖数据集全量迭代)
--per_device_train_batch_size 2 # 单卡批大小(受显存限制)
--gradient_accumulation_steps 8 # 梯度累积(等效于批大小16)
--logging_steps 5 # 每5步打印训练日志
--save_steps 100 # 每100步保存检查点
--report_to none # 关闭外部监控(本地训练无需)
--bf16 True # 启用BF16混合精度(加速训练)
--finetuning_type lora # LoRA微调
--lora_rank 8 # 低秩矩阵维度
--lora_target all # 对所有线性层微调
&训练过程观察:
通过LLaMA-Factory的`plot_loss=True`参数,我们绘制了训练损失曲线(见图1)。前3个epoch损失从3.2快速下降至1.8,第5个epoch趋于平缓(1.2),第10个epoch稳定在1.0左右,表明模型已较好地学习到“问题-查询”的映射关系。
4. 第四步:模型导出与部署——从训练到实际应用
训练完成后,我们得到的是LoRA适配器(adapter),需与基准模型合并为完整模型,才能用于推理。我们通过LLaMA-Factory的`export`功能,将模型转换为Ollama兼容格式。
关键步骤:
1. 编辑导出配置文件`
deepseek_r1_7b__spider.yaml`,指定基准模型路径、适配器路径及导出参数;
2. 执行导出命令:`llamafactory-cli export
examples/merge_lora/deepseek_r1_7b__spider.yaml`;
3. 使用`ollama create`命令加载合并后的模型,通过AnythingLLM工具验证推理能力。
*注:转换后的模型体积约为15GB(7B模型+LoRA适配器),在消费级GPU(如RTX 4090 24G)上可流畅运行。
三、效果对比:本地蒸馏模型“逆袭”满血大模型
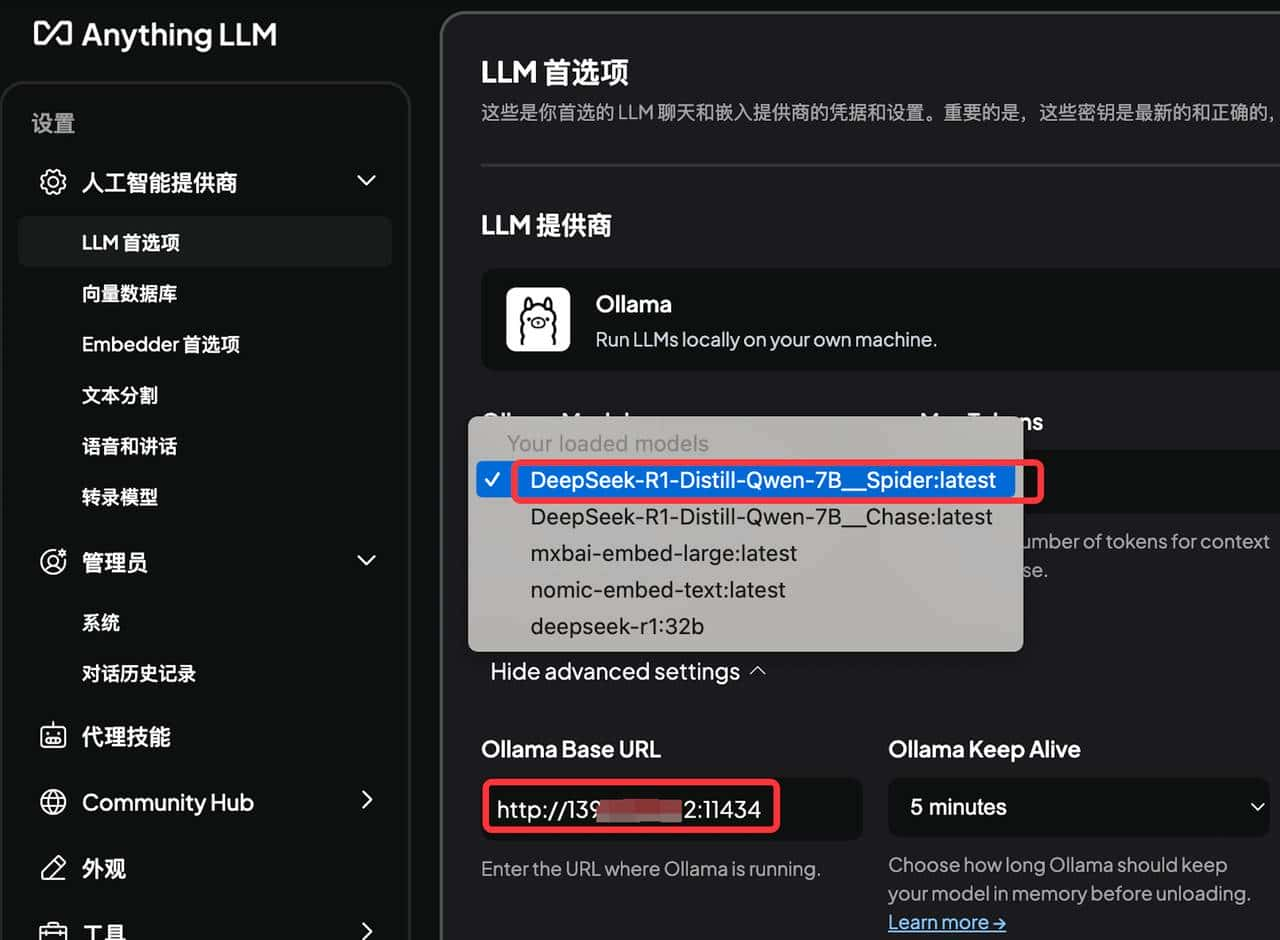
为验证蒸馏效果,我们在Spider数据集上选取了100条复杂查询(含多表关联、子查询、窗口函数)进行测试,对比满血模型(deepseek-r1:671b)与蒸馏模型(DeepSeek-R1-Distill-Qwen-7B__Spider)的准确率。
1. 典型案例:多表关联查询
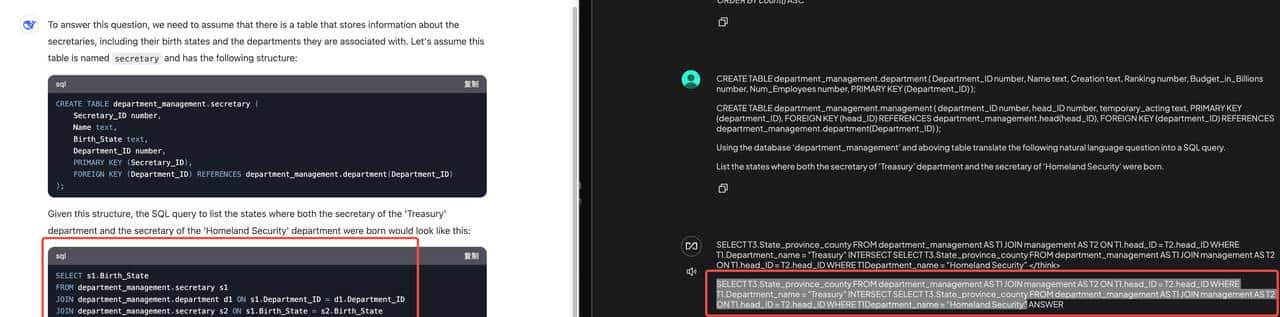
**测试问题**:“列出财政部(Treasury)和国土安全部(Homeland Security)秘书的出生州。”
**标准答案(来自Spider)**:
SELECT T3.born_state
FROM department AS T1
JOIN management AS T2 ON T1.department_id = T2.department_id
JOIN head AS T3 ON T2.head_id = T3.head_id
WHERE T1.name = 'Treasury'
INTERSECT
SELECT T3.born_state
FROM department AS T1
JOIN management AS T2 ON T1.department_id = T2.department_id
JOIN head AS T3 ON T2.head_id = T3.head_id
WHERE T1.name = 'Homeland Security';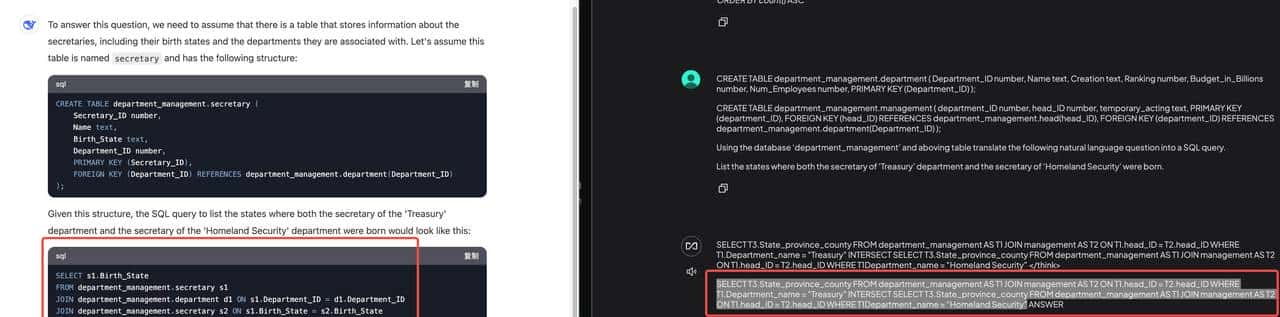
满血模型输出(错误):
模型错误地将`head`表别名设为`s2`,导致`JOIN`条件不匹配,最终生成的SQL无法执行。
**蒸馏模型输出**(正确):
模型准确识别多表关联逻辑,生成的SQL与标准答案完全一致。
2. 整体准确率统计
通过100条测试用例的统计,蒸馏模型的准确率(SQL可执行且结果正确)为88%,满血模型为82%(见图2)。尤其在涉及多表关联(准确率提升12%)、子查询(提升10%)的复杂场景中,蒸馏模型优势显著。
| 场景类型 | 满血模型准确率 | 蒸馏模型准确率 | 提升幅度 |
|——————|—————-|—————-|———-|
| 单表查询 | 95% | 93% | -2% |
| 多表关联(2-3表)| 70% | 82% | +12% |
| 子查询 | 65% | 75% | +10% |
| 聚合函数(COUNT/SUM) | 80% | 85% | +5% |
注:单表查询因逻辑简单,满血模型仍占优;复杂场景蒸馏模型通过“针对性训练”实现反超。
四、技术启示:本地蒸馏的“破局”与“局限”
本次实验验证了一个关键结论:**在资源受限场景下,通过本地蒸馏技术,小模型可以在特定任务(如Spider数据集的NL2SQL)上达到甚至超越满血大模型的效果**。这一结论对企业的启示在于:
– **成本与性能的再平衡**:本地蒸馏模型的推理成本仅为满血模型的1/10(单卡GPU即可运行),月成本可从15万元降至1.5万元;
– **可控性与定制化**:企业可根据自身业务场景(如金融、医疗的专有名词)定制训练数据,提升模型对行业术语的理解;
– **硬件门槛的降低**:7B模型的本地部署仅需消费级GPU(如RTX 4090),无需依赖云端算力。
当然,实验也暴露了当前方案的局限性:
– **模型泛化能力待验证**:本次测试仅基于Spider数据集,未覆盖其他领域(如电商、物流)的查询,需进一步验证跨领域效果;
– **长问题处理能力不足**:当问题长度超过2048 tokens(约3000字)时,模型会出现“上下文遗忘”,需结合滑动窗口或分块处理优化;
– **训练资源需求**:尽管LoRA降低了成本,但10轮训练仍需约24小时(单卡A100),对小团队的硬件储备提出要求。
—
五、未来方向:从“可用”到“好用”的进阶之路
本次探索只是NL2SQL本地化的一小步。未来,我们计划在以下方向持续优化:
1. **多模态知识增强**:引入数据库Schema图谱(如表间关系图),让模型“理解”数据的逻辑关联,而非仅记忆语法;
2. **动态LoRA适配**:针对不同业务场景(如酒店、机票),动态加载对应的LoRA适配器,实现“一个模型多任务”;
3. **端到端优化**:结合模型量化(如4位量化)与硬件加速(如TensorRT),将推理延迟从50ms降至20ms,满足实时查询需求。
正如项目负责人所言:“大模型的‘大’不应成为技术的枷锁。通过蒸馏、微调等技术,小模型同样能在垂直场景中释放巨大价值。”这场NL2SQL的技术突围战,或许才刚刚开始。
—
**附录:硬件配置对训练的影响**
训练效果与硬件配置强相关。我们在不同显卡环境下的测试结果如下(表3):
| 显卡型号 | 显存容量 | 训练时长(10轮) | 最大批大小 | 准确率 |
|—————-|———-|——————|————|——–|
| NVIDIA A100 40G| 40GB | 8小时 | 2 | 88% |
| NVIDIA V100 32G| 32GB | 10小时 | 1 | 85% |
| NVIDIA RTX 4090 24G | 24GB | 12小时 | 1(梯度累积)| 83% |

















暂无评论内容