
在上本书中,我们已经掌握了 Transformer 架构在自然语言处理(NLP)领域的统治力。它将人类语言这一复杂的离散符号系统,成功转化为数学上的向量计算。不过,当我们尝试将这颗“大脑”连接到物理世界时,立刻撞上了一堵看似不可逾越的墙:模态的鸿沟。
本章作为全书的开篇,将探讨多模态融合的第一性原理——序列化(Serialization)。我们将通过代码实证看到,计算机视觉(CV)是如何通过一次深刻的思维跃迁,放弃了对“像素空间结构”的执念,转而拥抱“Token(词元)”的哲学。
1.1 模态的鸿沟:当像素遇见符号
在很长一段时间里,AI 被割裂为两个平行的宇宙。
一边是 NLP 的研究者,他们处理的是离散的(Discrete)、高语义密度的符号。一段文字中的每个字(如“猫”)都蕴含着明确的概念。另一边是 CV 的研究者,他们处理的是连续的(Continuous)、低语义密度的信号。一张图片本质上是一个由红、绿、蓝数值构成的巨大矩阵,其中任何一个单独的像素点(Pixel)都没有意义,只有成千上万个像素组合在一起,才可能涌现出“猫”的边缘。
这种底层数据结构的差异,导致了算法架构的完全不同。我们急需一种通用的“货币”来进行信息交换。如图 1.1 所示,左侧的像素世界杂乱而连续,右侧的符号世界整齐而离散,我们需要一座桥梁。

图1.1 模态的鸿沟:像素世界与符号世界的连接
1.2 暴力美学:图像切片 (Patching) 原理
2020 年 10 月,Google Research 提出的 ViT (Vision Transformer) 横空出世。这篇论文的核心贡献不在于提出了新模型,而在于它用一种近乎“暴力”的方式回答了一个问题:如果不把图片当图片看,而是把它切碎了当成一句话看,会发生什么?
在 NLP 中,我们把句子切分成 Token;在 CV 的新范式中,我们将图像切分成 Patch(图像块)。
假设输入图像

1.3 代码实证:用卷积实现 Patch Embedding
理论听起来很简单,但在工程代码中是如何最高效地实现的?
许多初学者会尝试用循环或者切片操作来处理图片,但在生产级代码(如 PyTorch 官方实现或 Hugging Face)中,我们使用一个令人意想不到的技巧:步长等于核大小的卷积(Strided Convolution)。
见图 1.2,我们通过代码来验证这一过程。我们将对比“手动切片”和“卷积投影”两种方式,证明它们在数学上是等价的,而后者正是当前大模型主流的实现方式。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# 设置随机种子以保证结果可复现
torch.manual_seed(42)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体,以正常显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号'-'显示为方块的问题
def visualize_patch_embedding():
# 1. 模拟一张单通道的简单图片 (H=8, W=8)
# 为了可视化方便,我们用一个简单的数字矩阵代表像素强度
H, W = 8, 8
P = 4 # Patch Size
image_tensor = torch.arange(H * W, dtype=torch.float32).reshape(1, 1, H, W)
# 2. 方法一:使用 Unfold 手动切片 (逻辑上的 Patching)
# kernel_size=P, stride=P 意味着无重叠切片
unfold = nn.Unfold(kernel_size=P, stride=P)
# 输出形状: [Batch, Patch_Pixel_Vol, Num_Patches]
patches_unfold = unfold(image_tensor)
# 3. 方法二:使用 Conv2d 实现 (工程上的 Patching)
# 核心技巧:卷积核大小 = Patch大小,步长 = Patch大小
# 输入通道1,输出通道1 (为了对比,暂时不映射到高维),bias=False
conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=P, stride=P, bias=False)
# 强行将卷积核权重设置为全1矩阵,这样卷积结果就是Patch内像素之和
# 仅为了演示位置对应关系,实际训练时权重是随机初始化的
with torch.no_grad():
conv.weight.fill_(1.0)
output_conv = conv(image_tensor)
# 展平以便对比: [Batch, Out_Channel, N_Patches]
patches_conv_flatten = output_conv.flatten(2)
# 4. 可视化绘图
image_np = image_tensor.squeeze().numpy()
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 子图1: 原始图像
ax = axes[0]
im = ax.imshow(image_np, cmap='Blues')
ax.set_title(f"原始图像 ({H}x{W})", fontsize=14)
# 画网格线示意 Patch 边界
for i in range(0, H+1, P):
ax.axhline(i-0.5, color='red', linestyle='--', linewidth=2)
ax.axvline(i-0.5, color='red', linestyle='--', linewidth=2)
# 标注像素值
for i in range(H):
for j in range(W):
ax.text(j, i, int(image_np[i, j]), ha='center', va='center', color='black')
# 子图2: 逻辑切片 (Patch)
ax = axes[1]
ax.axis('off')
ax.set_title(f"逻辑切分: 4个 {P}x{P} Patches", fontsize=14)
patch_list = patches_unfold.squeeze().numpy() # shape [16, 4]
# 绘制4个小方块
for idx in range(4):
# 获取当前patch的像素值
p_vals = patch_list[:, idx].reshape(P, P)
# 在子图中创建一个小轴
sub_ax = fig.add_axes([0.38 + (idx%2)*0.12, 0.55 - (idx//2)*0.25, 0.1, 0.1]) # 手动定位
sub_ax.imshow(p_vals, cmap='Blues', vmin=0, vmax=H*W)
sub_ax.set_xticks([])
sub_ax.set_yticks([])
sub_ax.set_title(f"Patch {idx}", fontsize=10)
for r in range(P):
for c in range(P):
sub_ax.text(c, r, int(p_vals[r, c]), ha='center', va='center', fontsize=6)
# 子图3: 卷积输出 (Embedding)
ax = axes[2]
# 卷积后的输出实则是 2x2 的 Feature Map
out_map = output_conv.squeeze().detach().numpy()
im2 = ax.imshow(out_map, cmap='Greens')
ax.set_title("Conv2d 输出 (Feature Map)
Kernel=4, Stride=4", fontsize=14)
for i in range(2):
for j in range(2):
ax.text(j, i, f"Sum:
{int(out_map[i, j])}", ha='center', va='center', fontweight='bold')
plt.tight_layout()
return fig
fig = visualize_patch_embedding()
fig.savefig("fig1_2_patching.png", dpi=300)运行结果如下:

图1.2 卷积实现 Patch Embedding 的原理可视化
通过运行上述代码,我们可以清晰地观察到:一次步长(Stride)等于核大小(Kernel Size)的卷积操作,在数学上等价于先将图像切块,再对每一块进行加权求和(线性投影)。
这就是为什么在阅读 ViT 或 LLaVA 的源码时,你会看到如下定义的 Embedding 层:
Python
self.proj = nn.Conv2d(in_channels=3, out_channels=embed_dim, kernel_size=patch_size, stride=patch_size)这行简洁的代码,完成了从“图像空间”到“向量空间”的惊险一跃。
1.4 线性投影:建立通用的语义坐标系
切分只是第一步。原始的像素值(0~255 的整数)与文本的 Embedding 向量在分布上完全不同。我们需要将这些像素 Patch 映射到模型理解的高维空间。
这一步被称为线性投影(Linear Projection)。在图 1.2 的代码中,卷积层的 out_channels 参数(对应代码中的 embed_dim)决定了映射后的维度。
例如,在 ViT-Base 模型中,每个16×16×3的彩色 Patch(共 768 个数值),会被卷积层映射为一个长度为 768 的一维向量。此时,这个向量在数学形式上,已经与 NLP 中的单词 Embedding 没有任何区别了。
这就是“万物皆可序列化”的本质——在 Embedding 的高维空间里,光线与文字众生平等。
1.5 上帝视角:Transformer 的全局感受野
为什么我们要费尽周折把图片变成序列?这需要对比传统的卷积神经网络(CNN)。
CNN 的核心假设是**“归纳偏置(Inductive Bias)”,特别是局部性(Locality)**。CNN 认为,像素之间的关系主要存在于邻域内(列如猫的眼睛和鼻子离得很近),因此它使用滑动窗口来提取特征。
而 Transformer 没有这种预设。它通过自注意力机制(Self-Attention),让图像中的每一个 Patch 都能直接“看见”其他所有的 Patch,无论它们在图片中相距多远。
如图 1.3 所示,我们将 CNN 的局部感受野与 Transformer 的全局注意力进行了对比。Transformer 在第一层就拥有了“上帝视角”。
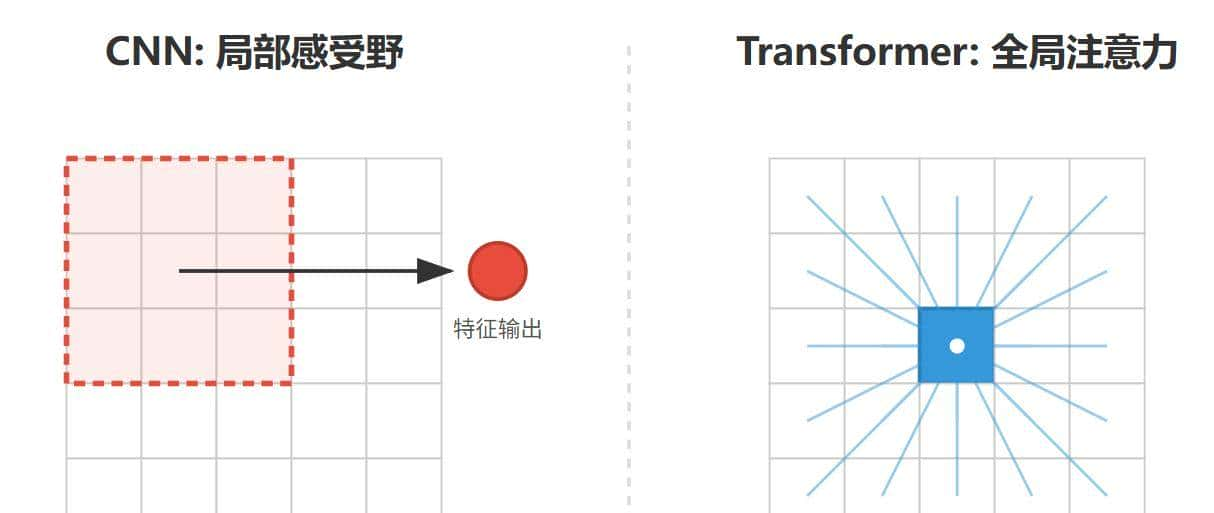
图1.3 CNN 局部感受野与 Transformer 全局注意力的对比
1.6 位置编码:找回丢失的空间秩序
Transformer 处理序列的能力很强,但它有一个致命的弱点:它是“空间盲”的。
如果你将输入句子中的单词顺序打乱,“我爱你”变成“你爱我”,标准的 Transformer(不带位置编码)计算出的 Attention 权重是一模一样的(由于点积运算不依赖顺序)。同样的,如果我们把图 1.2 中的 Patch 顺序打乱,图像就变成了一堆乱码,但模型却浑然不知。
为了解决这个问题,我们必须人为地注入位置编码(Positional Encoding)。这就像给每一个 Patch 贴上一个 GPS 标签:“我是第一行第二列”。
1.7 迈向通用的两条路径
当视觉信号成功序列化并转化为 Embedding 之后,我们通往通用人工智能(AGI)的道路就豁然开朗。如图 1.4 所示,这开启了两条激动人心的路径:
- 端到端融合(End-to-End): 像 LLaVA 或 GPT-4V 那样,直接训练一个多模态大脑,让它同时“吃”进图像 Token 和文本 Token。这是本书第四、五部分的重点。
- 工具使用(Tool-Use): 大模型依然是文本大脑,但它学会了生成代码来调用 YOLO、OCR 等外部视觉工具。这是本书第二部分的重点。
图1.4 通往通用感知的两条路径:端到端融合与工具使用
1.8 本章小结
本章我们推倒了 CV 与 NLP 之间的柏林墙。我们没有沉迷于复杂的公式推导,而是通过 nn.Conv2d 的代码实证,确立了 “万物皆可序列化(Everything is Token)” 这一核心思想。
- 打破隔阂: 图像不再是不可分割的像素矩阵,而是可以被切分、投影的 Patch 序列。
- 代码为证: Patch Embedding 在工程本质上就是一个步长等于核大小的卷积操作。
- 全局计算: Transformer 架构赋予了视觉处理前所未有的全局关联能力。
在接下来的章节中,我们将暂时把视线从高深莫测的 Transformer 移开,回头去捡起那些被我们遗落在路边的“旧武器”——卷积神经网络与经典视觉模型。由于在新的大模型时代,它们并没有消亡,而是化身为智能体手中最锋利的“手术刀”。
思考与面试角
问题 1:ViT(Vision Transformer)一般需要比 CNN 更多的数据量才能训练好,为什么?
- 参考答案: 这涉及“归纳偏置(Inductive Bias)”。
- CNN 具有很强的归纳偏置:平移不变性(猫在左上角和右下角是一样的)和局部性(相邻像素关系更紧密)。这种先验知识就像老师教的口诀,让 CNN 在小数据上也能快速学到规律。
- ViT 几乎没有这种空间假设(除了切 Patch 这一步)。它必须从海量数据中自己“悟”出“相邻的像素一般是相关的”这一规律。因此,ViT 是典型的数据饥渴型(Data-hungry)架构。
问题 2:在使用 nn.Conv2d 实现 Patch Embedding 时,如果不加 Padding,对输入图片的尺寸有什么硬性要求?如果图片尺寸不符合要求该怎么办?
- 参考答案:
- 硬性要求: 输入图片的高度H和宽度 W 必须能被 Patch Size PP 整除。即 H%P==0 且 W%P==0。否则,卷积操作会丢弃边缘无法填满一个 Kernel 的像素,或者报错。
- 解决方案: 在实际推理(Inference)中,如果遇到非标准尺寸的图片(例如224×224 的模型输入了一张 225×2252 的图),一般有两种做法:
- Resize/Crop: 强制缩放或裁剪到224×224(最常用,但可能丢失长宽比或边缘信息)。
- Pad: 在右侧和下侧填充 0 或边缘像素,使其补齐为P 的倍数,并在 Attention 阶段使用 Mask 屏蔽掉这些填充区域(多模态大模型处理任意分辨率图片时常采用此法)。
——完——
专注模型与代码
喜爱的朋友,欢迎赞同、关注、分享三连 ^O^















- 最新
- 最热
只看作者