10月21号,由中宣部组织的“推动高质量发展调研行”来皖聚焦采访活动在合肥市正式启动。近百位央媒记者和部分省级媒体记者参与,高规格大规模全媒体聚焦安徽发展。活动首站走进合肥京东方光电科技有限公司。

京东方光电科技有限公司创立于1993年4月,是一家为信息交互和人类健康提供智慧端口产品和专业服务的物联网公司。核心事业包括端口器件、智慧物联及智慧医工等。


当解说员讲到透明显示部分时,屏幕后文物的生平简介与事物属性完整地显目前透明的“玻璃”上,使橱窗内的文物开始变得“透明”。
原本用于保护文物,以防观赏者触摸损坏的玻璃橱窗,利用京东方开发的32英寸彩色透明液晶显示屏,瞬间成了文物说话的窗口。



BOE画屏展区看上去更像是一个艺术“画廊”,显示屏对画作细节的还原度超高,甚至同一个画屏中还会出现交替变化。



这里拥有全球第一条最高世代液晶面板生产线。合肥京东方第10.5代TFT-LCD生产线,主要生产65英寸及以上超大尺寸超高清液晶显示屏。整体设备的自动化和智能化水平、采用的核心工艺技术都达到业界最高水平。由于不断自主创新,合肥京东方在新型显示领域已从跟跑、并跑,到实现领跑,技术水平跻身世界前列。



8K屏幕的分辨率高达7680×4320,显示效果为4K显示屏的4倍,是目前主流高清(FHD)分辨率的16倍,可以让人拥有4.3倍的高清视觉体验。


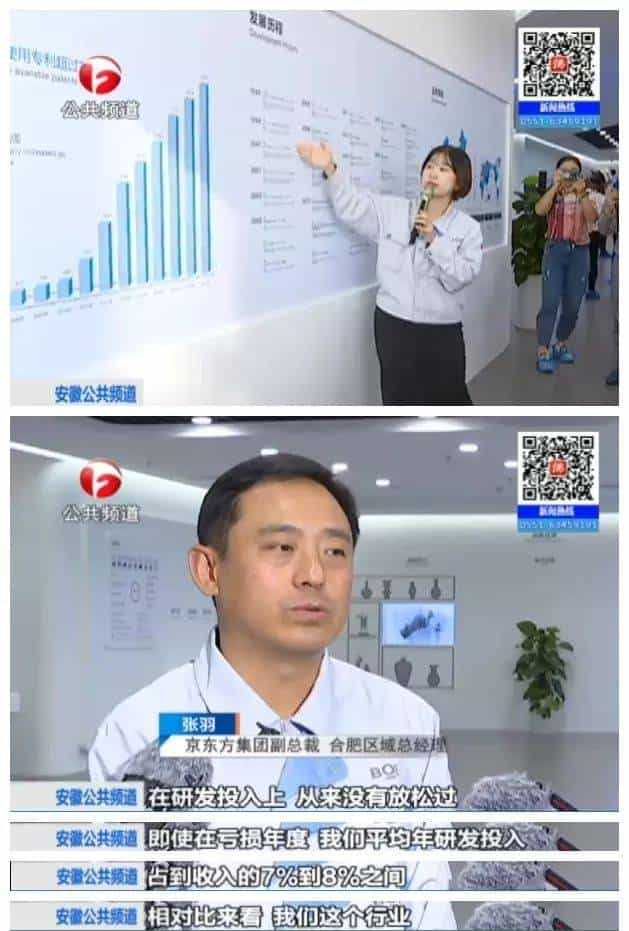
近几年,以京东方为代表的国产液晶屏已经崛起。目前,全球每四块液晶屏幕,就有一块来自京东方。高质量发展离不开科技创新投入。京东方在合肥还相继投资了智能制造工厂、数字医院和打印OLED技术平台等项目,总投资超过1000亿,提供就业岗位超过25000个,其中专职研发人员超1000人。
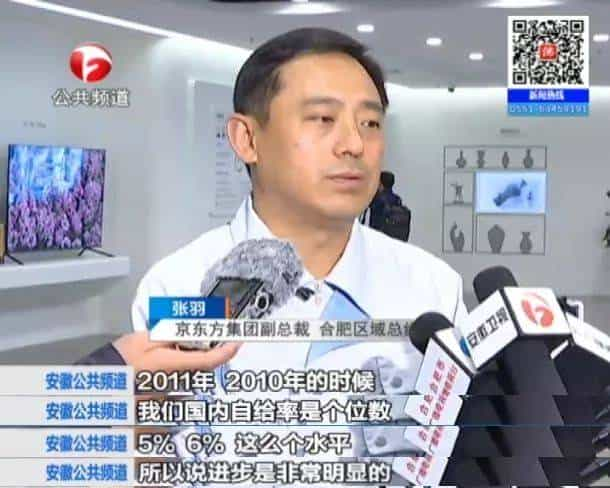
从投建第一条5代TFT—LCD生产线,到全球首条10.5代TFT—LCD生产线的成功量产,如今的京东方已拥有14条半导体显示生产线,结束了液晶显示器件长期依赖外购的状态,在智能手机、平板电脑、笔记本电脑、显示器、电视显示屏等五大应用领域出货量都稳居全球第一。


(公共频道记者 范亚峰 项飞 编辑赵娟娟 报道)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...