
嗨,大家好,我是徐小夕。
8年+程序员,曾任职多家上市公司,4年架构经验,打造过上亿用户规模的如软件产品,目前全职创业,创业项目主要聚集于“Dooring AI零代码搭建平台”和“flowmixAI多模态办公软件”。
大家都知道这两年我一直在研究和迭代多模态文档引擎 flowmix/docx:
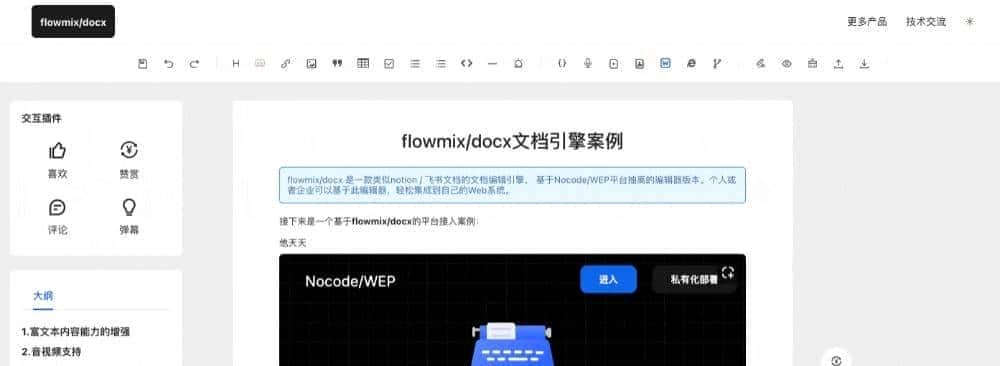
flowmix/docx
其中涉及到许多复杂的技术实现,列如多模态内容嵌入,文档解析和渲染等。
在研发的过程中,有一个超级棘手的问题——文档结构化解析,用传统工程化的方式基本上很难实现对docx,pdf等文件内的复杂格式进行提取和识别, 列如公式,表格,艺术字等。
flowmix/docx
恰巧最近在逛 github 的时候,发现一款超级有价值的文档解析方案——DocExt。
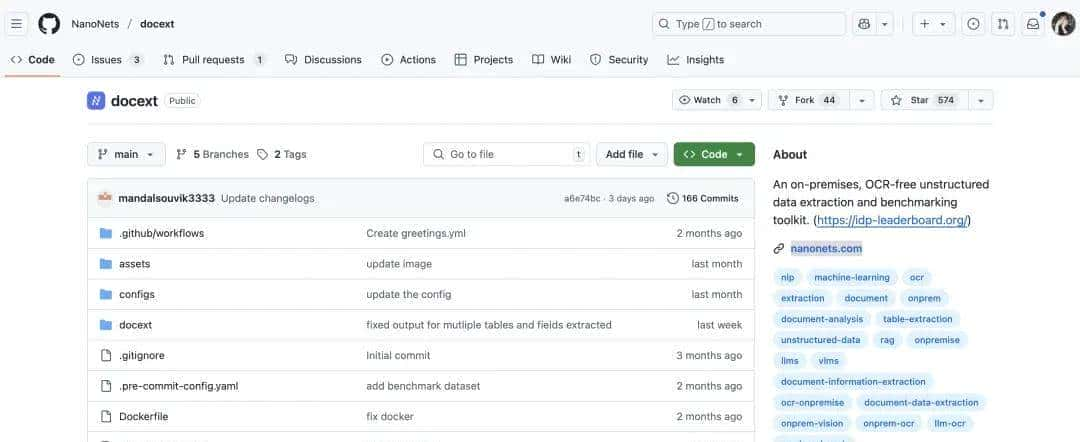
github地址:
https://github.com/NanoNets/docext
DocExt 最大的技术亮点在于摒弃了传统 OCR 技术逐字识别的模式,转而采用视觉语言模型(VLM),从整体语义和视觉布局层面理解文档。
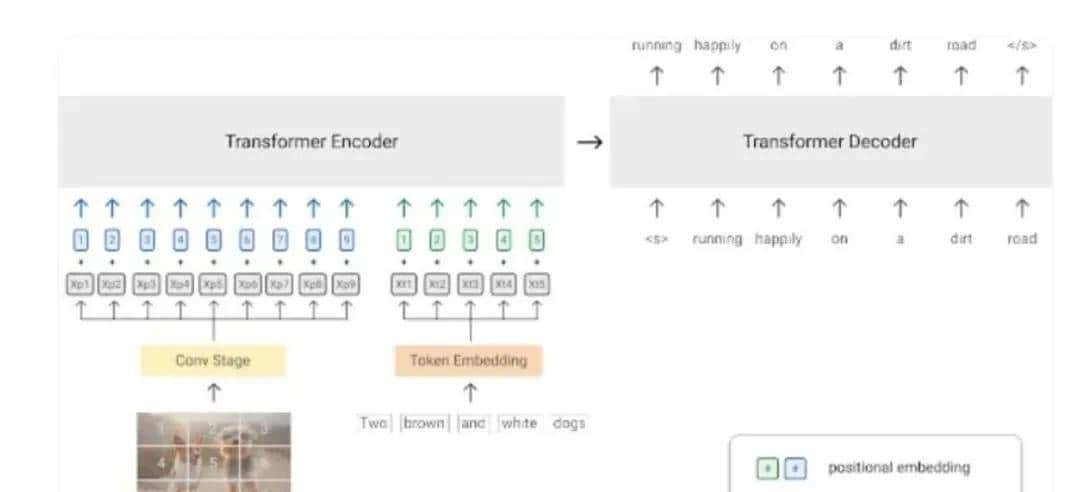
这一转变,彻底重构了文档解析全流程。传统 OCR 在面对模糊字迹、复杂表格、多语言混排等情况时,识别准确率会大幅下降;而 DocExt 的 VLM 技术,如同人类阅读文档般,通过对上下文和整体结构的分析,精准定位并提取关键信息。例如,在处理一份格式混乱的发票时,DocExt 能够快速锁定金额、日期、发票抬头等字段,无需依赖复杂的模板匹配或人工校正,极大提升了文档解析效率与准确性。
视觉语言模型是视觉和自然语言模型的融合。它将图像及其各自的文本描述作为输入,并学习将两种模式的知识关联起来。该模型的视觉部分从图像中捕获空间特征,而语言模型则对文本中的信息进行编码。
之所以我觉得这种方案比较优秀,是由于它充分利用了AI大模型的能力,并能生成结构化的文档数据。
这里不得不提一下目前主流的文档内容系统。
大家对飞书文档,Notion笔记管理工具想必不会陌生,它们的文档数据结构都是基于DSL:
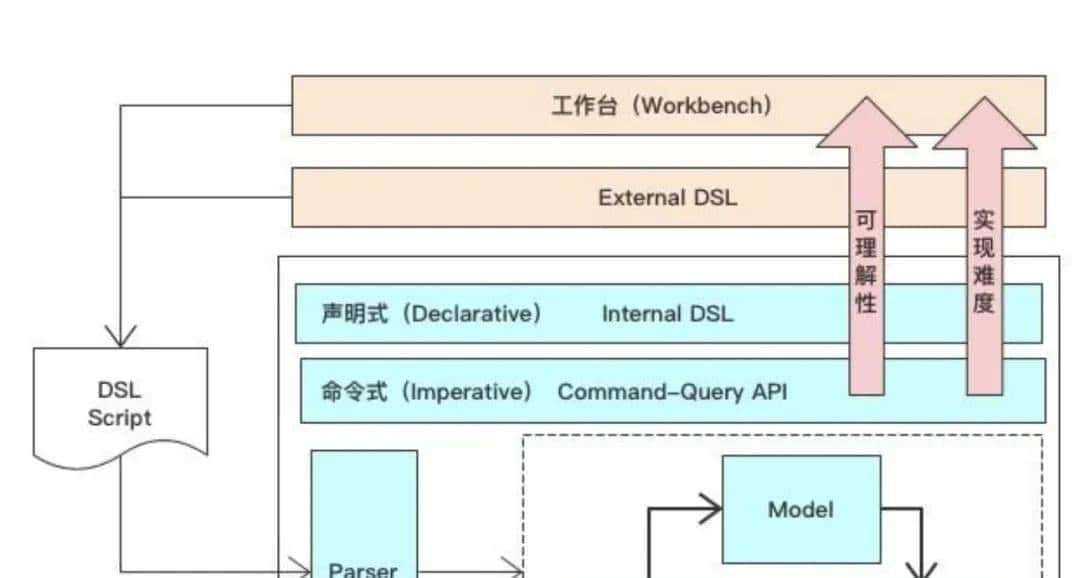
通俗一点来说,也就是结构化的json数据。到这里相比大家为什么我比较推荐DocExt 了。

DocExt 基于大模型的文档结构化提取技术,是其区别于其他工具的核心竞争力。通过训练视觉语言模型,DocExt 可以直接将非结构化的文档图像转化为结构化数据,支持发票、合同、证件、报表等多种常见文档类型。
以表格提取为例,即使是跨页、格式不规则的表格,DocExt 也能准确识别行列关系,完整提取数据,这是传统 OCR 技术难以企及的。并且,DocExt 支持本地部署,数据无需上传至云端,在保障数据安全与隐私的同时,也满足了金融、政务等对数据合规要求较高的行业需求。
所以 DocExt + flowmix/docx 可以实现超级强劲的云端文档编辑能力,我们可以基于 flowmix/docx 强劲的文档编辑能力和 DocExt 的文档解析能力,来实现对传统文档(DOCX,PDF, Excel)等的线上解析和编辑。
本地安装和部署
DocExt 的本地安装部署也超级简单,接下来和大家介绍一下它的几种安装方式。
1. 通过虚拟环境安装
# 安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建 Python 3.11 的虚拟环境
uv venv --python=3.11
source .venv/bin/activate
# 从 PyPI 安装
uv pip install docext
# 本地运行
python -m docext.app.app当然安装方式我们除了通过虚拟环境,也可以直接通过源码的方式安装:
git clone https://github.com/nanonets/docext.git
cd docext
uv pip install -e .启动后打开 Web 页面,可看到以下典型界面模块:
- 文档上传区域:拖拽或选择 PDF/图片后,自动触发处理,可批量上传;
- 字段 & 表格识别结果:关键字段高亮展示、表格直观渲染;
- 导出按钮:一键导出 JSON、CSV、Markdown 等格式,适合各类使用习惯。
当然 github 上有完整的介绍,大家可以参考研究一下。
github地址:
https://github.com/NanoNets/docext
当然大家有好的方案和提议也欢迎随时在留言区交流反馈~
最后
我们最近研发的 flowmix/docx多模态文档引擎,目前也在持续更新中,欢迎体验参考:

文档地址:
https://flowmix.turntip.cn
大家有好的想法和提议。欢迎随时评论区交流反馈~















- 最新
- 最热
只看作者