
SIF
Smooth Inverse Frequency
A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS
- 用weighted average of the word vectors表明句子;
对词w,词频表明为 ,权重为a,则:
,权重为a,则:

- 在用PCA或者SVD进行降维:去掉 first principal component (common component removal)。

FastSent
Learning to understand phrases by embedding the dictionary
We propose using the definitions found in everyday dictionaries as a means of bridging this gap between lexical and phrasal semantics. Neural language embedding models can be effectively trained to map dictionary definitions (phrases) to (lexical) representations of the words defined by those definitions. We present two applications of these architectures: reverse dictionaries that return the name of a concept given a definition or description and general-knowledge crossword question answerers. On both tasks, neural language embedding models trained on definitions from a handful of freely-available lexical resources perform as well or better than existing commercial systems that rely on significant task-specific engineering.
Skip-Thought
Skip-Thought Vectors
Code: https://github.com/ryankiros/skip-thoughts
无监督学习句子向量。
数据集:continuity of text from books
Hypothesize:Sentences that share semantic and syntactic properties are thus mapped to similar vector representations。
OOV的处理:vocabulary expansion,使得词表可以覆盖million级别的词量。
Model
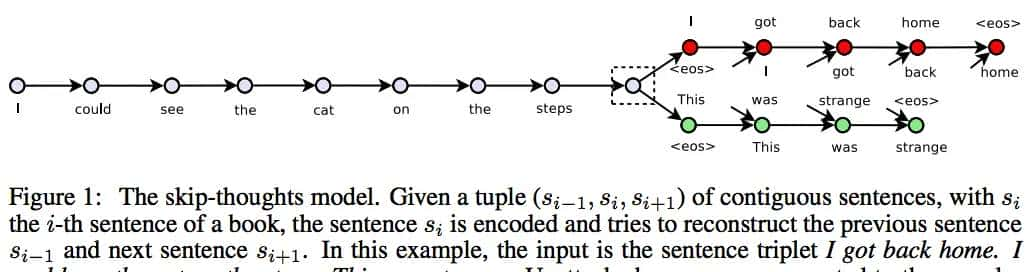
模型结构:encoder-decoder
skip-gram: use a word to predict its surrounding context;
skip-thought: encode a sentence to predict the sentences around it.
Training corpus: BookCorpus dataset, a collection of novels, with 16 different genres,.
输入:a sentence tuple ( )
)
Encoder: feature extractor –> skip-thought vector
Decoders: one for  , one for
, one for 
Objective function: 
下游任务:8种, semantic relatedness, paraphrase detection, image-sentence ranking, question-type classification and 4 benchmark sentiment and subjectivity datasets。
InferSent
Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
Code: https://github.com/facebookresearch/InferSent
监督式学习句子向量。
数据集:Standford Natural Language Inference datasets(SNLI),包含570k个人工生成的英语句子对,3种标签判读句子对的关系,entailment, contradiction, neutral。
向量表明:300d GloVe vectors
Hypothesize:使用SNLI数据集,足够学习到句子表达。
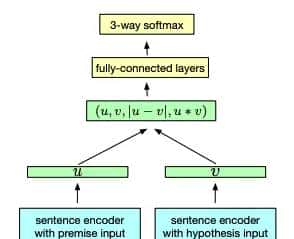
Model
3种向量拼接方式:
- concatenation of u,v;
- element-wise product
 ;
; - absolute element-wise difference

7种模型结构:
- LSTM
- GRU
- GRU_last: concatenation of last hidden states of forward and backward
- BiLSTM with mean pooling
- BiLSTM with max pooling
- Self-attentive network
- Hierarchical convolutional networks.
Universal Sentence Encoder
Universal Sentence Encoder
code: https://tfhub.dev/google/universal-sentence-encoder/2
通过学习多个NLP任务来encode句子,从而得到句子表达。
Model
训练集:SNLI
迁移任务:MR, CR, SUBJ, MPQA, TREC, SST, STS Benchmark, WEAT
迁移的输入:concatenation (sentence, word)
模型结构:2种encoders:
-
Transformer
准确率高,但模型复杂度高,计算开销大。
步骤:
a. Word representation:element-wise sum (word, word_position)
c. PTB tokenized string得到512d的句子表明 -
DAN(deep averaging network)
损失一点准度,但效率高。
a. Words + bi_grams
b. averaged embeddings
c. DNN得到sentence embeddings
SentenceBERT
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
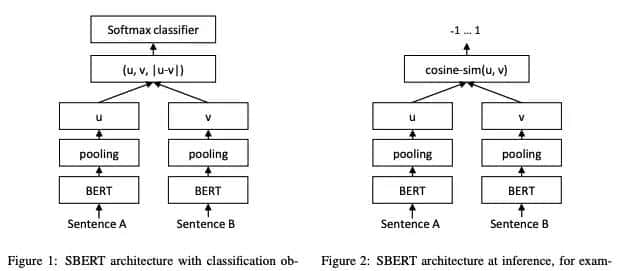
Model
训练集:SNLI, Multi-Genre NLI,前者为3分类数据,后者为sentence-pair形式。
使用的BERT向量:
- [CLS]:BERT output [CLS]token
- MEAN:BERT output 向量平均
- MAX:BERT output 向量取max
目标函数:
- 分类:

- 回归
- Triplet:

其中:
 :anchor sentence
:anchor sentence
 :positive sentence
:positive sentence
 :negative sentence
:negative sentence
模型需要让anchor和positive的距离小于anchor和negative的距离。














暂无评论内容