
本文是2016年的论文《word2vec Parameter Learning Explained》的论文笔记。经过该论文的分析,词的word2vec预训练模型不再是一个黑盒子。该论文透彻地回答了一个问题:
为什么在一个以onehot词向量作为输入和输出的三层神经网络里,第一层与第二层中间的权重矩阵能够表达词的信息呢?更简洁地来说,为什么word2vec能够训练出表达语言信息的稠密词向量呢?
简单模型:一个输入词和一个输出词
先抛弃掉带有滑动窗口概念的CBOW模型和skip-gram模型,先思考以下简单的模型,只有一个输入词和一个输出词(输入和输出都是onehot):
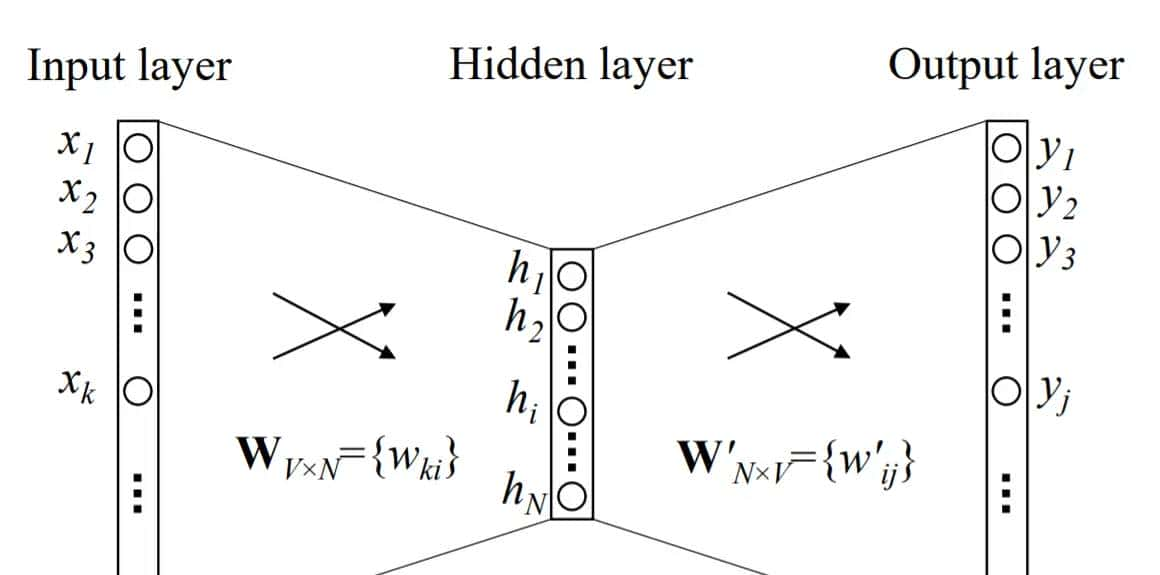
word2vec模型里,只要输入词和输出词在语言上是接近的,就能通过训练得到表达语言信息的稠密词向量。注意,在这个简单的模型里,还未有句子里相邻的词的概念。
 是输入词;
是输入词;
 是词的总数;
是词的总数;
 是词的onehot向量;
是词的onehot向量;
 是第一层到第二层的权重矩阵;
是第一层到第二层的权重矩阵;
 是权重矩阵
是权重矩阵 里代表词的那一行向量的转置;
里代表词的那一行向量的转置;
 是隐藏层向量:
是隐藏层向量:

 是第二层到输出层的权重矩阵;
是第二层到输出层的权重矩阵;
 是权重矩阵
是权重矩阵 的第
的第 列;
列;

%7D%3D%5Cfrac%7Bexp(%7Bv _%7Bw_j%7D%7D%5ETv_%7Bw_I%7D)%7D%7B%5Csum_%7Bj %3D1%7D%5E%7BV%7Dexp(%7Bv _%7Bw_%7Bj %7D%7D%7D%5ETv_%7Bw_I%7D)%7D)
必须注意的是,向量 和
和 都是词
都是词 的稠密表达。前者是输入层到隐藏层的权重矩阵的某一行,后者是隐藏层到输出层的某一列。为了简化表达,下文将称为输入词向量,将称为输出词向量。
的稠密表达。前者是输入层到隐藏层的权重矩阵的某一行,后者是隐藏层到输出层的某一列。为了简化表达,下文将称为输入词向量,将称为输出词向量。
假设 是输出词的onehot向量的第个元素,如果输出词恰好是第个词,那么
是输出词的onehot向量的第个元素,如果输出词恰好是第个词,那么
 ,否则为
,否则为 。假设输出词是第
。假设输出词是第 个词,交叉熵损失函数为
个词,交叉熵损失函数为

套用一下求导公式,当 时有
时有 ,当
,当 时有
时有 ,总而言之,有:
,总而言之,有:

 的含义是第个词的error。对于权重矩阵的其中一个元素:
的含义是第个词的error。对于权重矩阵的其中一个元素:

假设学习率是 ,那么矩阵的某个元素的梯度更新的公式为:
,那么矩阵的某个元素的梯度更新的公式为:
%7D%3D%7Bw _%7Bij%7D%7D%5E%7B(old)%7D-%5Ceta%20e_jh_i)
或者,矩阵的某一列的梯度更新公式为:
%7D%3D%7Bv _%7Bw_j%7D%7D%5E%7B(old)%7D-%5Ceta%20e_jh)
在最初的时候,权重 是被随机初始化的。上式是的某一列的梯度更新,该权重矩阵的每一列都是要被更新的。如果第列刚好是输出词,那么
是被随机初始化的。上式是的某一列的梯度更新,该权重矩阵的每一列都是要被更新的。如果第列刚好是输出词,那么 ,
, 就会加上一小部分的,这使得与输入词的输入向量
就会加上一小部分的,这使得与输入词的输入向量 的距离更近;如果第列不是输出词,那么
的距离更近;如果第列不是输出词,那么 0″ mathimg=”1″>,就会减去一小部分的,这使得与输入词的输入向量的距离更远。这里说的近和远,都是在内积测度下的距离。思考一下如果输入词和输出词是在一个小窗口里面的两个词,那么这两个词大抵上是在语言上意思接近的两个词。以上的梯度更新过程能让输入词和输出词的对应的权重更接近。这里说的权重是。接下来我们来看一下权重。
0″ mathimg=”1″>,就会减去一小部分的,这使得与输入词的输入向量的距离更远。这里说的近和远,都是在内积测度下的距离。思考一下如果输入词和输出词是在一个小窗口里面的两个词,那么这两个词大抵上是在语言上意思接近的两个词。以上的梯度更新过程能让输入词和输出词的对应的权重更接近。这里说的权重是。接下来我们来看一下权重。

标量 并成一个向量:
并成一个向量: ,其含义是输出权重的每一列(每一个输出词向量)的加权和,而权重是error。
,其含义是输出权重的每一列(每一个输出词向量)的加权和,而权重是error。
经过简单的矩阵运算可以得到:

上式便是梯度,而只有输入词的那一行的梯度会被更新,其它梯度都不变:

直观地来说,由于EH是以作为权重的输出词向量的加权求和,我们可以理解为对输入词的输入向量加上了所有词的输出词向量的一部分,以 为权重。加上了
为权重。加上了 ,以及减去了其它所有词
,以及减去了其它所有词 。在内积测度上,每次更新梯度,向输出词的输出向量走得更近了,以及向所有不是输出词的词的输出向量走得更远了。
。在内积测度上,每次更新梯度,向输出词的输出向量走得更近了,以及向所有不是输出词的词的输出向量走得更远了。
在使用一个语料库不断地更新梯度时,所有词的输出向量被输入词的输入向量“来回地拉扯”,输入词的输入向量也被所有词的输出向量“来回地拉扯”,就像有一个物理的力量在不断调整词向量在空间的位置,使得意思相近的词在空间上的距离更接近。只要通过一种工程方法保证输入词和输出词是意思接近的或者有联系的,那就能够保证在梯度下降的过程中,意思相近的词在空间上的距离更接近。而这种工程方法就是基于滑动窗口的CBOW或者skip-gram。
CBOW:多个输入词与一个输出词
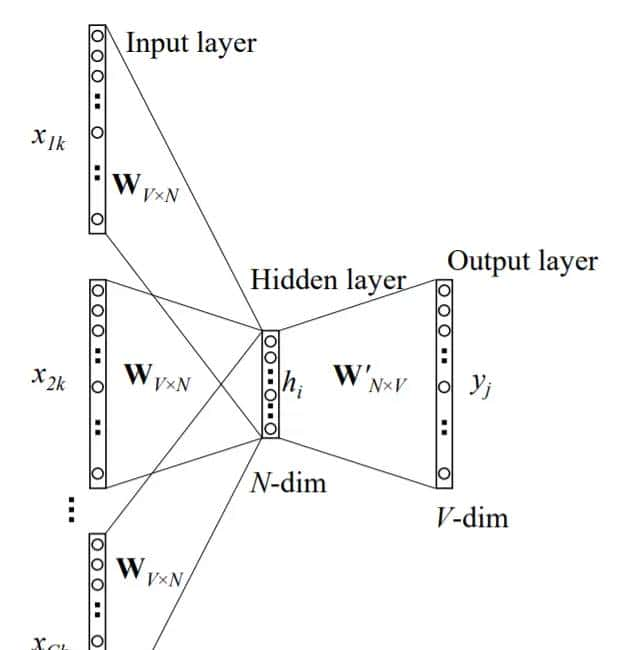
如图所示,句子的滑动窗口的中心词 作为输出词,中心词旁边的C个词
作为输出词,中心词旁边的C个词 作为输入词。输入层到隐藏层里,不同的输入词共享一个权重矩阵:
作为输入词。输入层到隐藏层里,不同的输入词共享一个权重矩阵:

%7D)

这种情况下损失函数、 以及的梯度更新的含义都是和上面一样的。重点探究一下的梯度更新的含义。
以及的梯度更新的含义都是和上面一样的。重点探究一下的梯度更新的含义。
上面的简单模型里,的梯度下降只需要更新一个输入词的输入向量的梯度。此处的CBOW里,需要更新C个词的输入向量的梯度。通过简单的矩阵运算得到:

 是一个梯度矩阵,这个矩阵里只有对应着输入词的行的梯度才是非零的。梯度更新的公式如下:
是一个梯度矩阵,这个矩阵里只有对应着输入词的行的梯度才是非零的。梯度更新的公式如下:

其含义与上面的分析也是一样的。实则多对一的CBOW模型与上面简单的一对一模型几乎没有变化,只不过是窗口内多个输入词输入进去一起训练了。
skip-gram:一个输入词与多个输出词
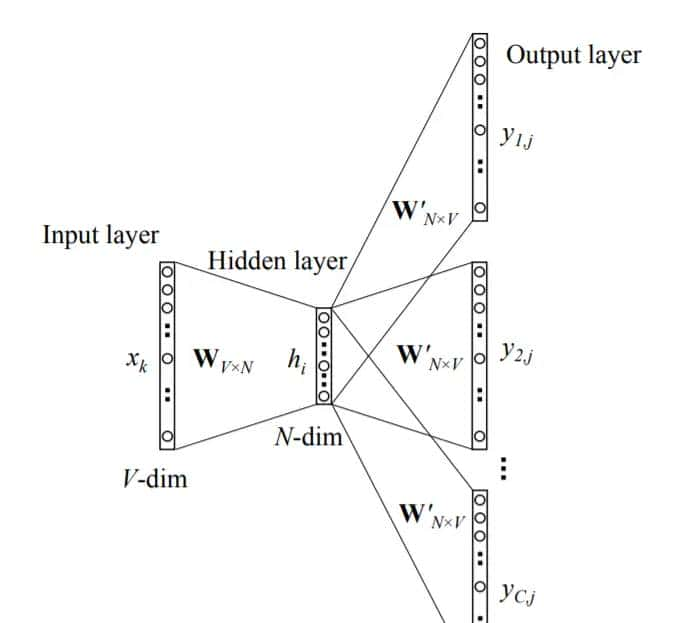
skip-gram模型的输入层到隐藏层与简单模型一样,仅考察输出层。对于第 个词:
个词:
%7D)
由于隐藏层到输出层是共享权重的,所以 与
与 是相等的。下标多了个字母c只是为了表达这是第c个输出词的预测。
是相等的。下标多了个字母c只是为了表达这是第c个输出词的预测。

skip-gram的一个细节是,假定C个输出词之间是独立的。因此C个输出词的联合概率密度的对数,作为损失函数,可以写成:

%7D%3D-%5Csum_%7Bc%3D1%7D%5E%7BC%7Du_%7Bc%2Cj_c%5E*%7D%2BClog%5Csum_%7Bj %3D1%7D%5E%7BV%7Dexp(u_%7Bj %7D))
对于第个词( )有:
)有:

定义 ,
, 的含义是C个词的error加起来。便得到了损失函数对的梯度:
的含义是C个词的error加起来。便得到了损失函数对的梯度:

梯度下降的公式:
%7D%3D%7Bw _%7Bij%7D%7D%5E%7B(old)%7D-%5Ceta%20EI_jh_i)
或者,矩阵的某一列的梯度更新公式为:
%7D%3D%7Bv _%7Bw_j%7D%7D%5E%7B(old)%7D-%5Ceta%20EI_jh)
令 ,只与简单模型的有了些许变化,其含义并没有变;在简单模型里,是朝着一个输出词的输出向量接近,朝着所有不是输出词的输出向量远离,在skip-gram理则是朝着C个输出词的输出向量接近,朝着所有不是输出词的输出向量远离(内积测度下的接近和远离)。的梯度下降公式:
,只与简单模型的有了些许变化,其含义并没有变;在简单模型里,是朝着一个输出词的输出向量接近,朝着所有不是输出词的输出向量远离,在skip-gram理则是朝着C个输出词的输出向量接近,朝着所有不是输出词的输出向量远离(内积测度下的接近和远离)。的梯度下降公式:
word embedding的优良性质
词embedding向量有超级优良的性质,这些性质使得embedding向量包含了语义信息,因此可以直接用于深度语言模型的有监督训练;例如:
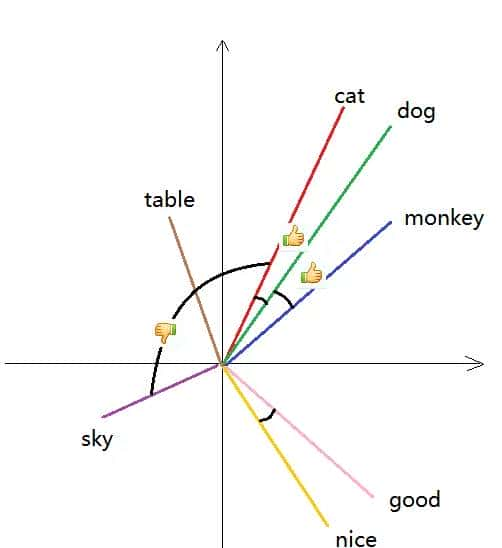
- 词性一样且意思相近的词embedding很接近。这个接近不仅体目前cosine类似度上,也体目前欧氏距离上。例如,v(猫咪)与v(狗狗)类似,而v(萨摩耶)与v(柴犬)类似。
-
类比性质:这是一个超级神奇的,更加能体现语义的性质。如v(中国)-v(北京)≈v(法国)-v(巴黎),国家的embedding和首都的embedding之差能得到类似的向量。又如v(国王)-v(王后)≈v(男人)-v(女人)。人类在婴儿时期学习语言很大程度上都是依靠类比的能力;本文在解释Word2vec的原理也大量使用了类比的方法。类比是人类学习的一把不可或缺的斧子。而word2vec模型居然有类比的能力,太神奇了!但是本文对word2vec的原理探究中,为何它能有类比性质依然没有很清晰地说明。下图是embedding向量的降维可视化:


















暂无评论内容