
朋友们,是否常常遇到对一个数据量很大的表添加索引的场景?白天不敢动需要等到凌晨使用量很小的时候加?操作完后很焦虑地等待未知的结果。到底会不会影响正常业务数据的增删?是否锁表?我也是这样过来的,痛定思痛,对MySQL进行了深入学习,对这块知识进行了整理,和大家分享。
前提
先明确一下MySQL中的几个名词。
DML:是指 查、插、删、改 这种对数据的基本操作(不动表结构)。
DDL:是指 增删字段、加索引、改字段类型 这种对表结构的操作。
MDL:Meta Data Lock,即元数据锁,分元数据写锁(X锁) 和 元数据读锁(S锁),元数据写锁阻塞DDL和DML,元数据读锁阻塞DDL但不阻塞DML(由于DML不修改表结构啊)。
对同一个表,DDL肯定会阻塞DDL,当然这种场景我们完全可以避免。下面主要说加索引这个DDL对DML的影响,此时是否会阻塞。
结论
MySQL5.6之前,锁表。
MySQL5.6之后,引入了OnlineDDL,技术上不锁表,实际上有短时间锁表,根源在MDL锁。
注:这里说的 ‘锁表’ 并不是加表锁,而且由于 MDL 锁引起的对DML的阻塞。
Online DDL加索引的三阶段

说明:
- 准备阶段;申请MDL写锁。
- 执行阶段;真正执行DDL的阶段;此时降级为MDL读锁,由于MDL读锁也能阻塞其他DDL,但它不会阻塞DML,效能更好;这个阶段耗时比较长(有的版本此阶段也会处理alter_log)。
- 提交阶段;升级为MDL写锁(为了阻塞其他DML),快速把alter_log里的记录处理一下,然后把索引生效。
由于只有准备和提交才有MDL写锁,故得出结论:加索引过程中 只有准备阶段和提交阶段会阻塞 DML。
Online DDL加索引的过程
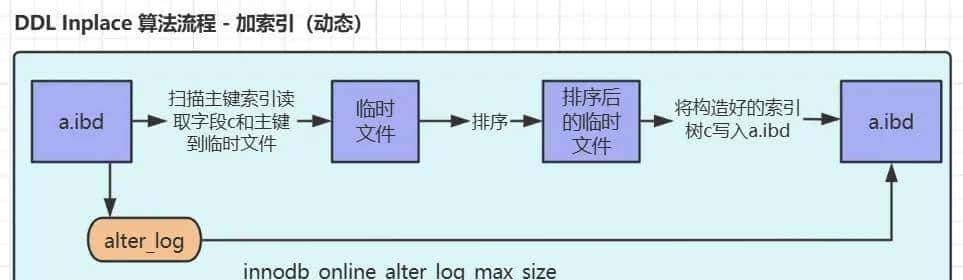
说明:这个过程都是在引擎层处理的(并没有读取到Server层), 很好地体现了 Inplace 算法的思想;再有这个过程实则并非完全实现online ddl,也有必定时间的阻塞,步骤如下:
A、对于已经存在的数据,走主线,扫描出来放临时文件排序后插入 ibd 文件。
B、在A过程中又新增的数据呢,就需要alter_log记录,把这些数据插入 ibd时是需要锁表(锁更新)的,所以有一段的锁表,并非完全online ddl。
C、alter_log越大锁表时间就越长,可以通过参数 innodb_online_alter_log_max_size 限制,(默认128M),但是一旦超出这个阈值则加索引的这个动作就失败回滚。所以,这个参数不能太小了,最好还是在低峰时操作。
D、MySQL8.0引入了 instant DDL,但主要用于 修改索引类型等少数操作,而常规的 加/删二级索引依然是 inplace DDL,故 MDL 阻塞风险依然存在。
怎样添加索引
了解了上面的知识,那么我们应该怎么对大表添加索引呢?我总结了如下几点:
- 第一检查现有的索引是否可复用。加了索引就会多占用一部分磁盘(特别是大表,许多时候索引占用空间比数据都多),可以采用如下SQL查询磁盘占用情况;加了索引还会影响插删改的效能;以目前的硬件性能一个表建七八个索引问题不大,但不提议再多了。
select table_name,
round(data_length / 1024 / 1024, 2) as 'data_size', -- 数据大小(实则就是主键索引的大小)
round(index_length / 1024 / 1024, 2) as 'index_size', -- 其他所有二级索引大小
round(data_free / 1024 / 1024, 2) as 'free_size' -- 碎片大小
from information_schema.tables
where table_schema = 'bee' -- 指定数据库,这样就是查询数据库 bee 里所有表的磁盘占用情况- 查询有没有 无用索引 和 冗余索引,确定没用的可以删除
-- 查询无用索引
select *
from sys.schema_unused_indexes s
where s.object_schema = 'bee'
说明:object_schema:数据库名,object_name:表名,index:索引名
-- 查询冗余索引
select s.*
from sys.schema_redundant_indexes s
where table_schema='bee' and table_name='student';- 低峰期进行(最最最重大)。
- 检查是否有长事务和MDL锁。
-- 查询长事务
select trx_mysql_thread_id thread_id, trx_state, if(length(trx_query) <= 800, trx_query, concat(substring(trx_query, 1, 800), '...')) as trx_query, trx_rows_locked, trx_tables_locked, trx_isolation_level, timestampdiff(second, trx_started, now()) AS trx_duration
from information_schema.innodb_trx trx
where timestampdiff(second, trx_started, now()) > 5
limit 20
-- 查询锁(MySQL8)
select lw.waiting_pid req_thread_id,
lw.waiting_query req_query,
lw.locked_table req_lock_table, lw.locked_type req_lock_type, lw.waiting_lock_mode req_lock_mode, lw.locked_index req_lock_index, lw.wait_age_secs req_duration,
lw.blocking_pid blk_thread_id,
lw.blocking_query blk_query,
lw.locked_table blk_lock_table, lw.locked_type blk_lock_type, lw.blocking_lock_mode blk_lock_mode, lw.locked_index blk_lock_index, TIMESTAMPDIFF(SECOND, lw.blocking_trx_started, NOW()) AS blk_duration
from sys.innodb_lock_waits lw
order by blk_duration desc
limit 20
- 设置锁等待超时时间,避免无限期 等待。 set lock_wait_timeout = 60;
- 指定算法和锁。
ALGORITHM=INPLACE;避免复制整张表,减少锁表时间。
LOCK=NONE;允许并发读写(MySQL 5.6+ 支持)。
注意:
MySQL是比较智能的,它会自己选择最合适的方式,许多时候默认就指定了。
某些情况下(如全文索引、空间索引)不支持 INPLACE,会退化为 COPY;- 修改索引(实则不存在修改,只是先删再增)时,为避免‘无索引’ 的空档,可以把删索引和加索引放到一个SQL语句里,如下:
ALTER TABLE your_table
DROP INDEX idx_old,
ADD INDEX idx_new(a,b,c),
ALGORITHM=INPLACE, LOCK=NONE;- 使用三方工具 pt-online-schema-change。















- 最新
- 最热
只看作者