
前言
最近 Z-Image-Turbo 在 AI 绘图圈子里可谓是“名声大噪”。原因无他,懂得都懂,在消费级16G显存的设备里可以完美适配。吃灰许久的、曾经首发加价的 RX 9070 XT,终于赢来了他的用武之地。
准备工作
显卡:AMD Radeon RX 9070 XT (16GB)显卡驱动版本 :25.20.01.17 graphics driver系统:Windows 11 25H2 26200.7171核心工具:
Visual Studio 2026 Build Tools(用于编译 C++ 依赖)Miniconda / Anaconda(Python 环境管理)Git
第一步:基础环境搭建
1. 安装 VS Build Tools
下载并安装 Visual Studio Build Tools
必选组件:勾选左上角的 “使用 C++ 的桌面开发” (Desktop development with C++)。目的:防止安装 flash-attention 等插件时报错。
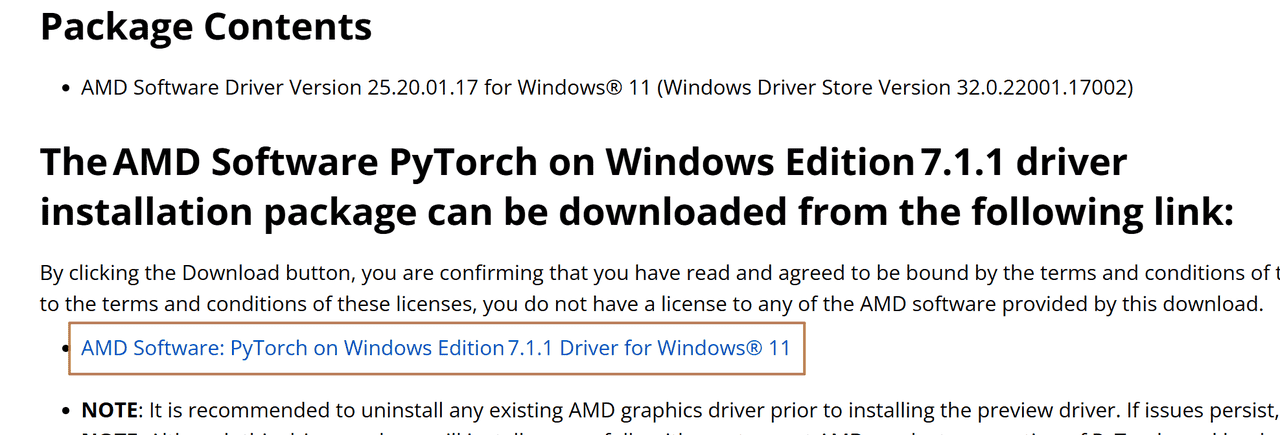
2.更新显卡驱动
按照官方建议,下载25.20.01.17 graphics driver 版本,在网页里找到下方链接安装,当然比这个版本高也可以。
3. 配置 Conda 环境
下载并安装Anaconda,安装完成以后,打开 Anaconda PowerShell Prompt,创建专属环境(注意:ROCm 7.1 推荐 Python 3.12):
# 创建环境
conda create -n z-image-win python=3.12 -y
# 激活环境
conda activate z-image-win
第二步:安装 ROCm 7.1.1 (Windows版)
需要从 AMD 官方仓库拉取最新的 ROCm 7.1 Python Wheels。
在 Conda 环境中,配置ROCm环境
# 安装 ROCm SDK 核心组件
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/rocm_sdk_core-0.1.dev0-py3-none-win_amd64.whl
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/rocm_sdk_devel-0.1.dev0-py3-none-win_amd64.whl
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/rocm_sdk_libraries_custom-0.1.dev0-py3-none-win_amd64.whl
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/rocm-0.1.dev0.tar.gz
安装支持 ROCm AMD GPU的 torch、torchvision 和 torchaudio
# 安装 ROCm SDK 核心组件
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/torch-2.9.0+rocmsdk20251116-cp312-cp312-win_amd64.whl
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/torchaudio-2.9.0+rocmsdk20251116-cp312-cp312-win_amd64.whl
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-7.1.1/torchvision-0.24.0+rocmsdk20251116-cp312-cp312-win_amd64.whl
确认是否安装了Pytorch并检测到GPU计算设备
(z-image-win) C:Userssflood>python -c "import torch" 2>nul && echo Success || echo Failure
Success
测试GPU是否可用和安装的GPU设备
(z-image-win) C:Userssflood>python -c "import torch; print(torch.cuda.is_available())"
True
(z-image-win) C:Userssflood>python -c "import torch; print(f'device name [0]:', torch.cuda.get_device_name(0))"
device name [0]: AMD Radeon RX 9070 XT
预期是成功和现实自己的显卡名称,进入下一步
第三步:部署 ComfyUI
comfyUI官方傻瓜式安装包针对N卡,因此我这里采用的是拉取源码部署
克隆项目:
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
安装依赖:
pip install -r requirements.txt
运行项目:
python main.py --use-split-cross-attention
--use-split-cross-attention
对大图、Turbo/SDXL、显存紧张的卡特别有用,原理是把自注意力计算按块拆开,降低单次显存峰值,用时间换稳定性
(z-image-win) F:comfyuiComfyUI>python main.py --use-split-cross-attention
Checkpoint files will always be loaded safely.
Total VRAM 16304 MB, total RAM 32417 MB
pytorch version: 2.9.0+rocmsdk20251116
Set: torch.backends.cudnn.enabled = False for better AMD performance.
AMD arch: gfx1201
ROCm version: (7, 1)
Set vram state to: NORMAL_VRAM
Device: cuda:0 AMD Radeon RX 9070 XT : native
Enabled pinned memory 14587.0
Using split optimization for attention
Python version: 3.12.12 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 20:05:38) [MSC v.1929 64 bit (AMD64)]
ComfyUI version: 0.3.75
ComfyUI frontend version: 1.32.9
[Prompt Server] web root: C:Userssflood.condaenvsz-image-winLibsite-packagescomfyui_frontend_packagestatic
Total VRAM 16304 MB, total RAM 32417 MB
pytorch version: 2.9.0+rocmsdk20251116
Set: torch.backends.cudnn.enabled = False for better AMD performance.
AMD arch: gfx1201
ROCm version: (7, 1)
Set vram state to: NORMAL_VRAM
Device: cuda:0 AMD Radeon RX 9070 XT : native
Enabled pinned memory 14587.0
Import times for custom nodes:
0.0 seconds: F:comfyuiComfyUIcustom_nodeswebsocket_image_save.py
Context impl SQLiteImpl.
Will assume non-transactional DDL.
No target revision found.
Starting server
To see the GUI go to: http://127.0.0.1:8188
看到
http://127.0.0.1:8188
Z-Image-Turbo实战
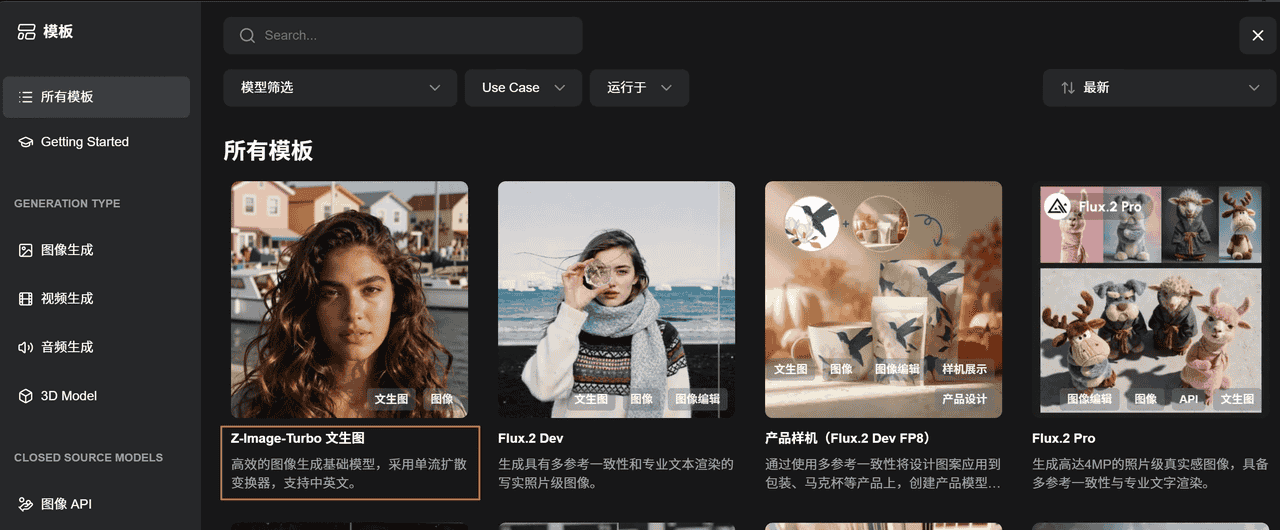
浏览器输入127.0.0.1:8188,进入页面就能看到模板,官方实例里已经给出来了模板
点击以后,如果没安装模型,会提示需要下载三个模型
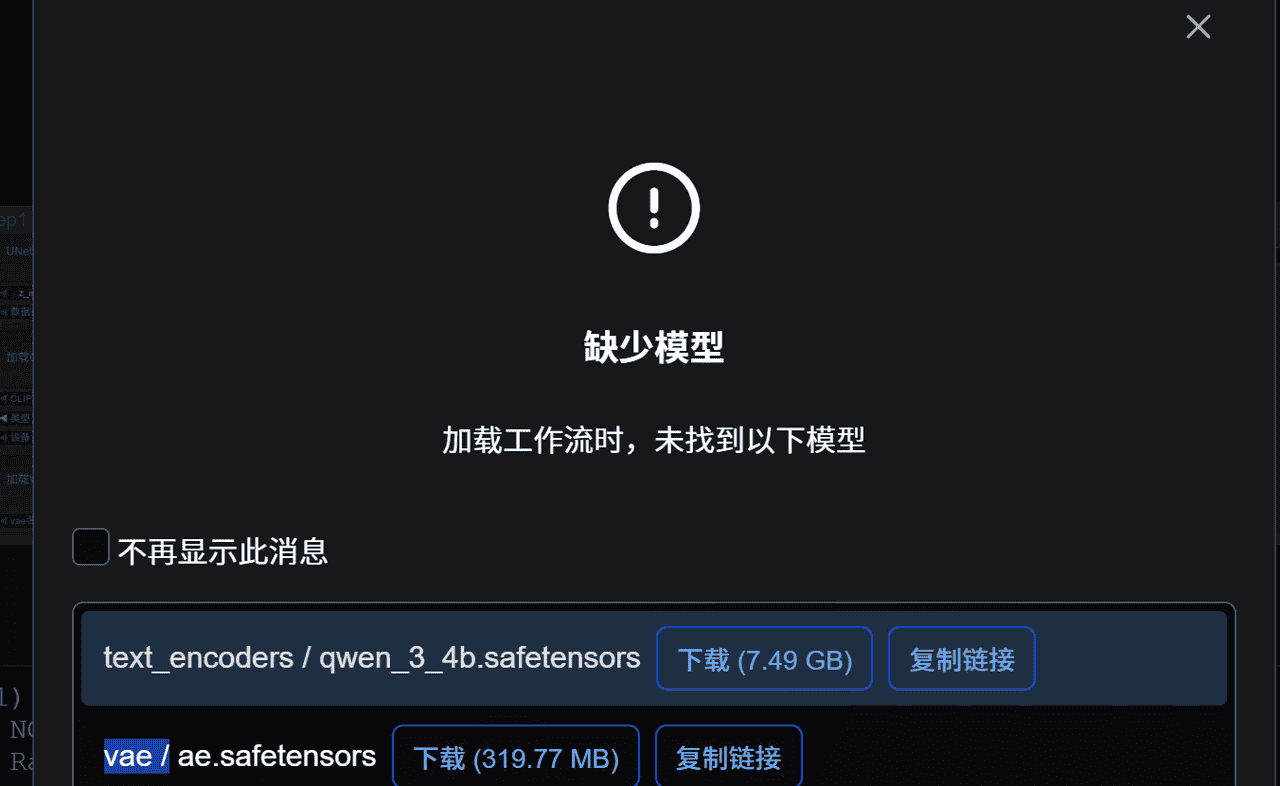
下载以后放到ComfyUI安装路径下的
# ComfyUI替换成你的ComfyUI安装路径
"ComfyUImodels ext_encodersqwen_3_4b.safetensors"
"ComfyUImodelsvaeae.safetensors"
"ComfyUImodelsdiffusion_modelsz_image_turbo_bf16.safetensors"
放置后再打开工作流,不弹出提示,代表模型正确
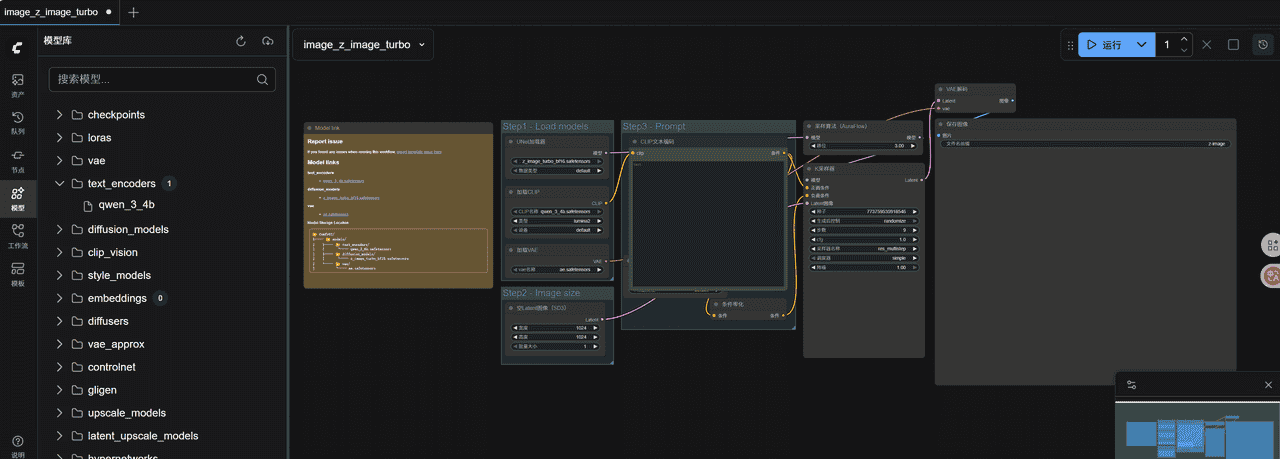
第三步这里输入提示词
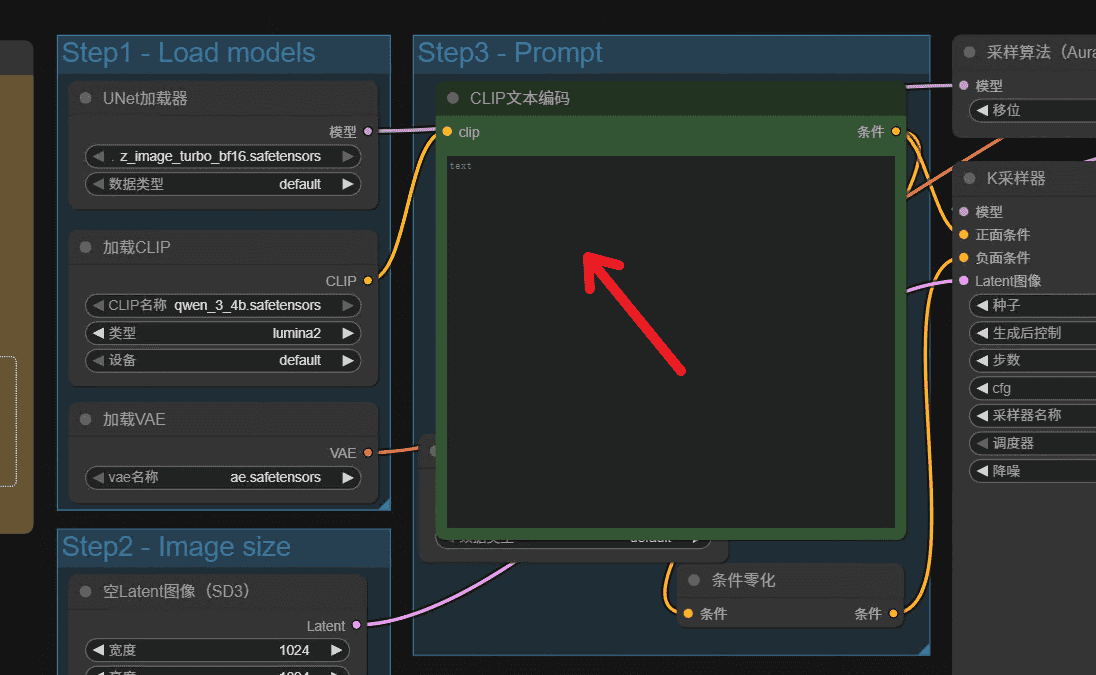
输入完成以后点击运行即可
# 运行日志
got prompt
Using split attention in VAE
Using split attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.bfloat16
Requested to load ZImageTEModel_
loaded completely; 95367431640625005117571072.00 MB usable, 7672.25 MB loaded, full load: True
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cuda:0, dtype: torch.float16
model weight dtype torch.bfloat16, manual cast: None
model_type FLOW
unet missing: ['norm_final.weight']
Requested to load Lumina2
loaded partially; 11125.02 MB usable, 11096.89 MB loaded, 642.66 MB offloaded, 28.12 MB buffer reserved, lowvram patches: 0
100%|| 9/9 [00:54<00:00, 6.07s/it]
Requested to load AutoencodingEngine
Unloaded partially: 8396.89 MB freed, 2700.00 MB remains loaded, 84.38 MB buffer reserved, lowvram patches: 0
loaded completely; 5277.18 MB usable, 159.87 MB loaded, full load: True
Prompt executed in 75.64 seconds
运行的时候资源占用
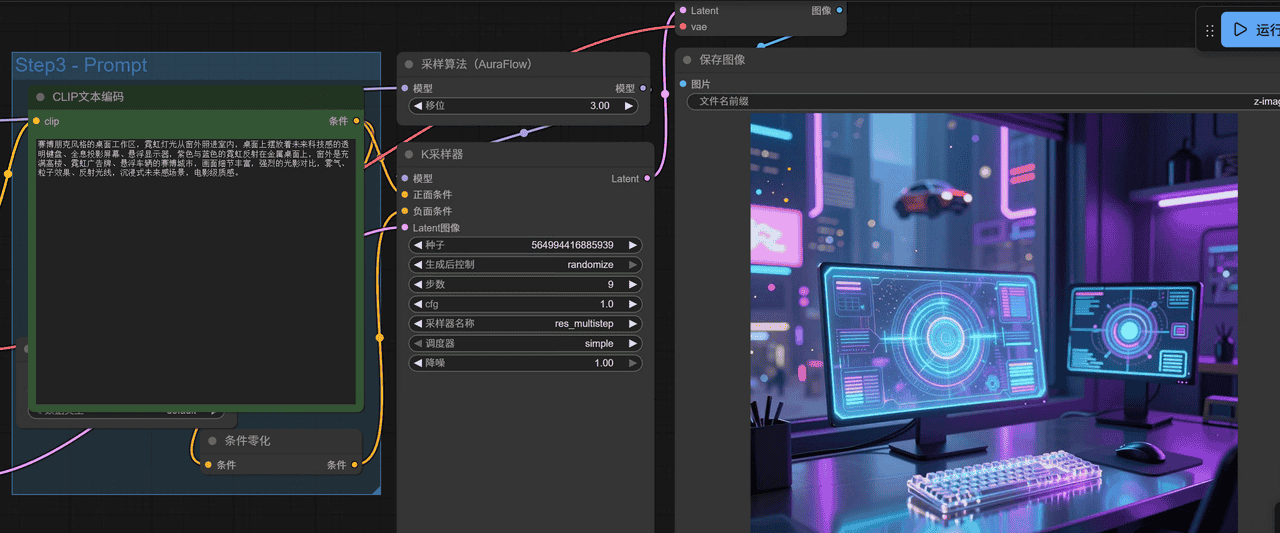
![图片[1] - 实战!在 AMD RX 9070 XT (16G) 上使用原生 Windows ROCm 7.1 部署 ComfyUI + Z-Image-Turbo - 鹿快](https://img.lukuai.com/blogimg/20251206/7d15612f257d4ea6a1730f37ac3cd467.png) 效果
效果
常见问题
掉驱动,崩溃
现象,跑着跑着就弹框错误
![图片[2] - 实战!在 AMD RX 9070 XT (16G) 上使用原生 Windows ROCm 7.1 部署 ComfyUI + Z-Image-Turbo - 鹿快](https://img.lukuai.com/blogimg/20251206/4fb14eee8cf245d0aa8d944bd25be4a1.png) 解决方案
解决方案
Windows 默认 GPU 超时阈值只有 2 秒,这里把超时阈值放宽到 32 秒
# 修改 Windows TDR 参数
reg add "HKLMSYSTEMCurrentControlSetControlGraphicsDrivers" /v TdrDelay /t REG_DWORD /d 32 /f
reg add "HKLMSYSTEMCurrentControlSetControlGraphicsDrivers" /v TdrDdiDelay /t REG_DWORD /d 32 /f
或者打开注册表编辑器
输入
计算机HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlGraphicsDrivers

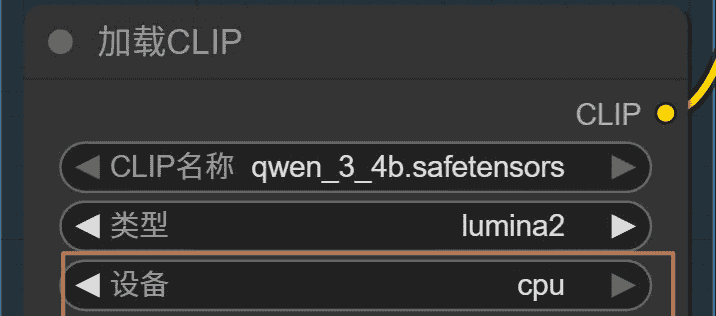
加载CLIP可以交给CPU,释放一点显存,不过缺点就是执行速度慢一点
是否可以在WSL里,而不用Windows
我试过,截至25年12月1日,我在写这篇文章的时候,官方的WSL里的Rocm只支持6.4.2.1,对9000系列优化较少,可以看官方文章Install Radeon software for WSL with ROCm — Use ROCm on Radeon and Ryzen
![图片[3] - 实战!在 AMD RX 9070 XT (16G) 上使用原生 Windows ROCm 7.1 部署 ComfyUI + Z-Image-Turbo - 鹿快](https://img.lukuai.com/blogimg/20251206/a10781a2b9f4445182a4b9fcf11e4fd9.png)
如果是纯Linux,可以试一试
















暂无评论内容