
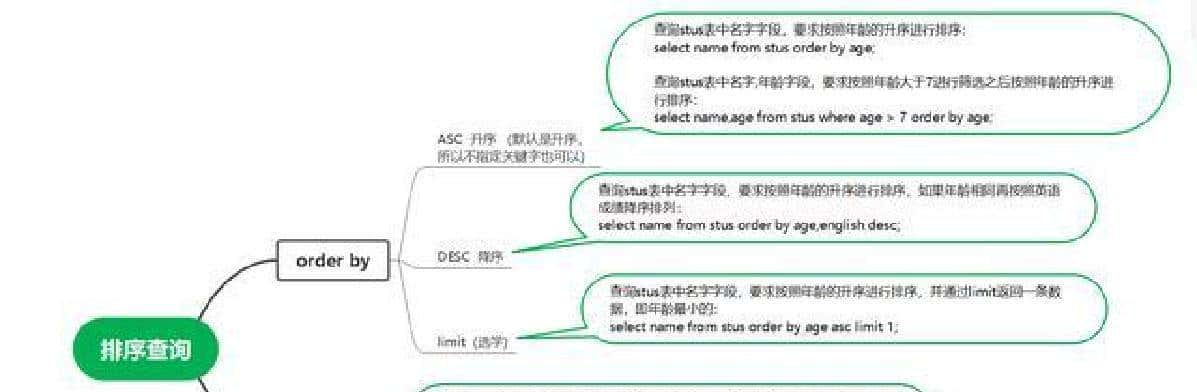
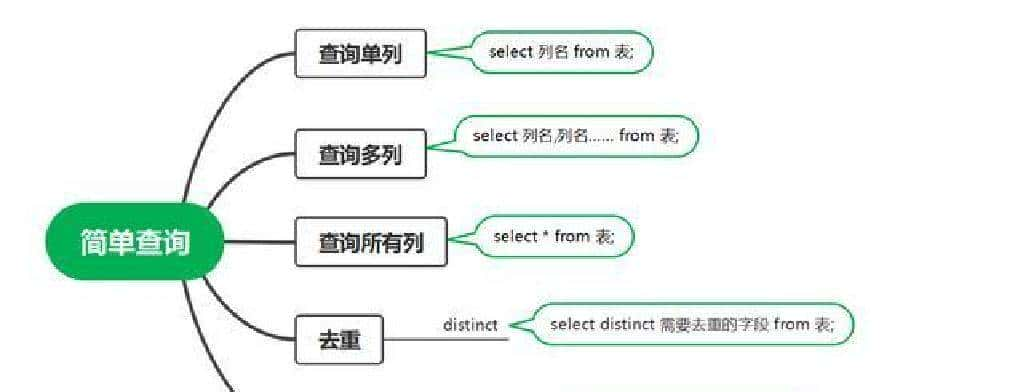
最终产出的是一张按学校和题目难度划分的“人均答题量”表格,SQL 在本地 MySQL 环境里跑通了,能按学校、按难度把用户的平均刷题数给算出来。想看山东大学在各难度下的数据也能单独拉出来,整套做法是先按用户统计,再按学校汇总。
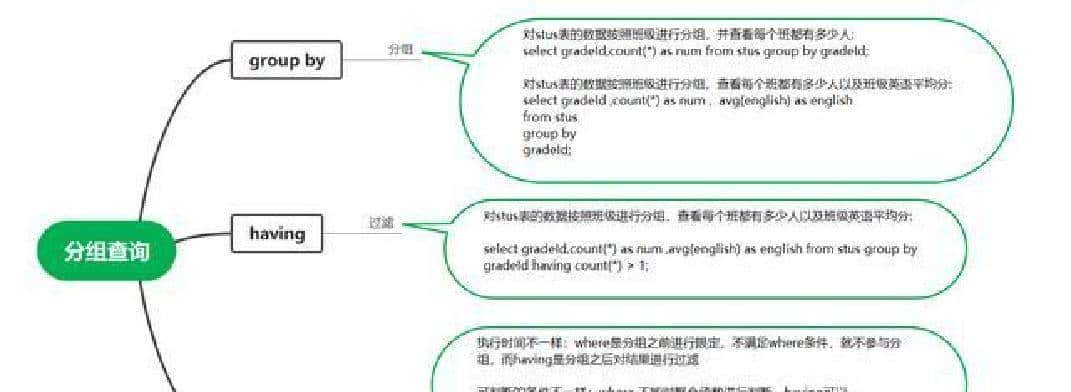
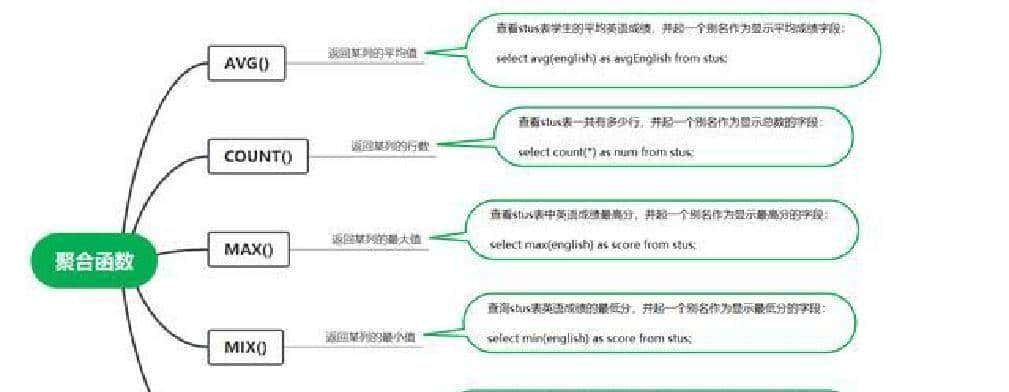
先说直接用到的几条 SQL 思路,方便马上复现。思路比较直:先把每个用户在每个难度上的答题次数算出来,得到“用户-难度-次数”的中间表;然后把这张表和用户档案表连起来,用学校分组算平均值。按山东大学单拉一份,或按所有学校一起分组都能做。下面是可以直接在 MySQL 里跑的 SQL 示例:
— 每个用户在每个难度下的答题次数(中间表)
SELECT user_id, difficulty, COUNT(*) AS cnt
FROM question_practice_detail
GROUP BY user_id, difficulty;
— 按学校和难度计算人均答题数
SELECT up.school, t.difficulty, AVG(t.cnt) AS avg_answers
FROM (
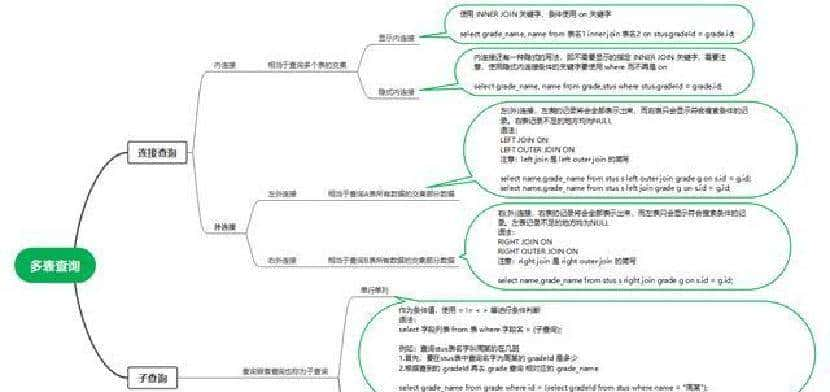
SELECT user_id, difficulty, COUNT(*) AS cnt
FROM question_practice_detail
GROUP BY user_id, difficulty
) t
JOIN user_profile up ON t.user_id = up.id
GROUP BY up.school, t.difficulty;
— 只看山东大学在各难度下的平均答题数
SELECT t.difficulty, AVG(t.cnt) AS avg_answers
FROM (
SELECT user_id, difficulty, COUNT(*) AS cnt

FROM question_practice_detail
GROUP BY user_id, difficulty
) t
JOIN user_profile up ON t.user_id = up.id
WHERE up.school = '山东大学'
GROUP BY t.difficulty;

另外,想把每个用户自己在不同难度上的平均值也展示出来(列如用户在不同难度上的平均刷题数)可以这样写:
SELECT user_id, AVG(cnt) AS avg_per_user
FROM (
SELECT user_id, difficulty, COUNT(*) AS cnt
FROM question_practice_detail
GROUP BY user_id, difficulty
) x
GROUP BY user_id;
执行细节上有几点补充,避免跑出假象数据。第一,某些用户可能完全没做题,question_practice_detail 没有记录,这类用户会在中间表缺失;如果要把“未参与用户也计入学校平均”的话,得用 LEFT JOIN 并把 NULL 视为 0 去计算。第二,难度字段的取值要确认一致,有些场景是数字、有人是枚举文字,要统一后再分组。第三,数据量大的时候,中间表那步最好用索引支撑:对 question_practice_detail 的 user_id 和 difficulty 建复合索引,GROUP BY 会快不少。还有注意 MySQL 的 AVG 是对非 NULL 值的平均,如果做了 LEFT JOIN、空值要处理成 0。
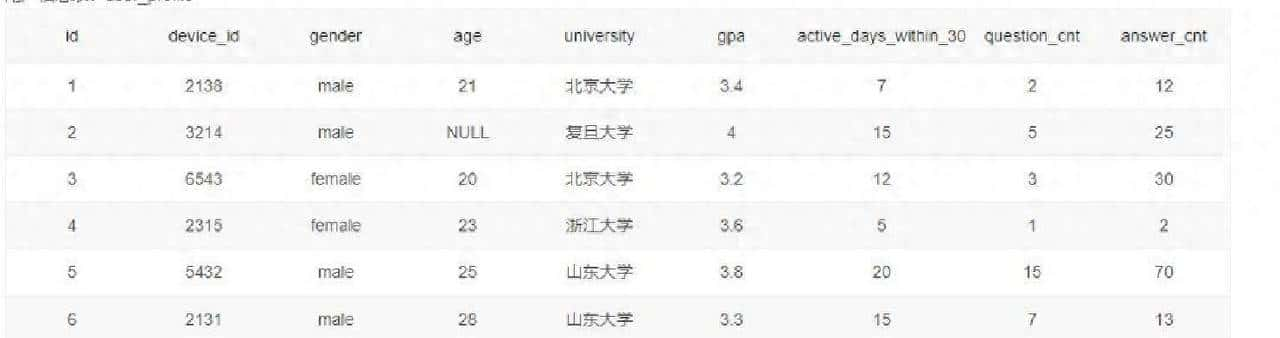
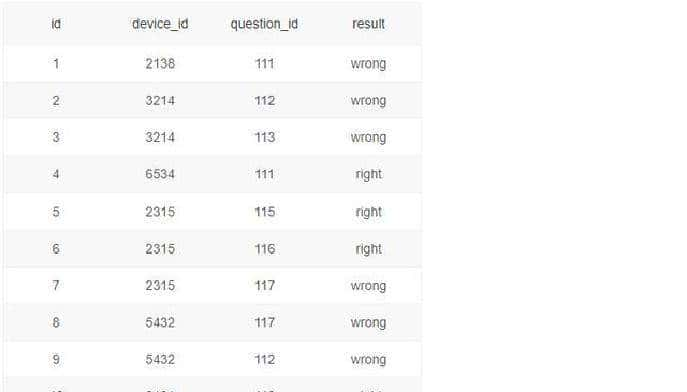
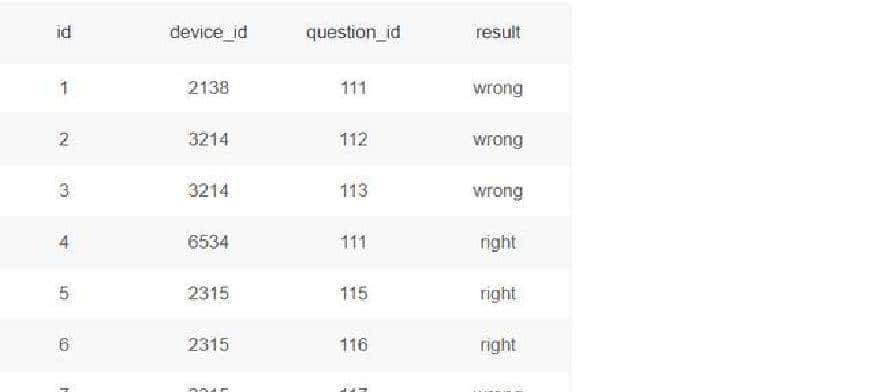
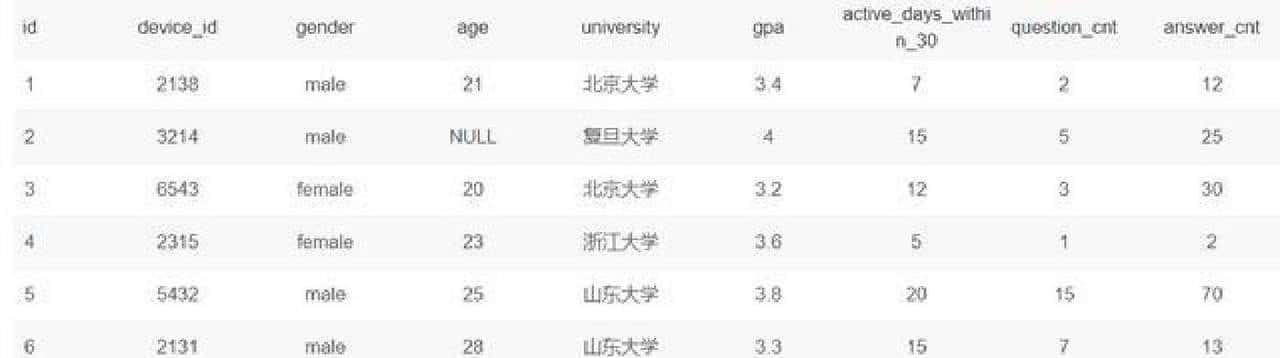
把表的结构和字段说明也交代清楚,避免误用。用到两个表:user_profile 和 question_practice_detail。user_profile 是用户档案,最常用的字段包括 id、device_id、gender、age、school、gpa、last30_active_days、post_count、answer_count 等。举个例子,表里有一行这样的用户记录:id = 1,device_id = 2138,gender = 男,age = 21,school = 北京大学,gpa = 3.4,过去 30 天活跃天数 = 7,发帖数 = 2,回答数 = 12。question_practice_detail 则记录了每一次题库练习明细,关键字段有 user_id、question_id、difficulty、timestamp 等,用来统计次数和时间分布。
整个方案的处理顺序实则很简单:先把明细按用户和难度聚合,再把聚合结果按学校汇总平均。之所以不直接在明细上按学校和难度做 AVG,是由于要把“每个用户的答题行为”先标准化,避免大户(刷题特别多的少数人)把学校的平均值拉偏。中间表那一步等于是把每个用户在每个难度上的贡献先缩成一个数字,再对这些数字求平均,这样能更好反映“典型用户”的行为,而不是总题量。
过程中还碰到几类常见情况:一是同一个用户在同一难度但跨多天做题,数据里可能带时间戳,如果要按天去重或按时间窗口(列如最近 30 天)计算,SQL 需要加 WHERE timestamp >= DATE_SUB(NOW(), INTERVAL 30 DAY) 或者在中间表里再按 date(timestamp) 做聚合;二是有些题目的难度字段缺失或标错,需要先做清洗,列如把 NULL 标成 unknown,或者把写法不统一的标签统一成标准值;三是用户的学校信息可能为空或写法不一致(“山东大学”写成“山东大”“山大”等),这类需要先做映射或人工清理,影响分组结果。
我当时整理成了一个思维导图,按“目标 → 中间表 → 汇总表 → 常见问题与处理”四块来记。实际落地跑数据时,先在开发库里跑一遍小样本,确认逻辑再全量跑。MySQL 环境下常用的调优手段有索引、分批处理、临时表保存中间结果,或者把 COUNT 换成 SUM(1) 来避免某些版本的性能坑。
执行过程中有一件小事值得注意:如果你要对单个学校(列如山东大学)做深挖,提议先把该校的用户列表单独提取出来,再和练习明细做联查,这样能减少中间 JOIN 的扫描量。实际工作里我就是先把 up.id 抽出来放进一个临时表,然後对 question_practice_detail 做分组统计,最后再回连拿学校信息,速度更稳。
以上就是在 MySQL 环境下,把“按学校和难度统计人均答题量”这件事从思路到 SQL 到落地时遇到的问题和应对办法的完整记录。想要的话,我还可以把那些边界情况的 SQL 例子贴全,或者把思维导图的要点按步骤拆成脚本,一步步在你自己的数据上跑通。




![在苹果iPhone手机上编写ios越狱插件deb[超简单] - 鹿快](https://img.lukuai.com/blogimg/20251123/23f740f048644a198a64e73eeaa43e60.jpg)
















暂无评论内容