
《人工智能AI之计算机视觉:从像素到智能》· 模块一:视觉之门——从经典特征到CNN革命
在上一篇,我们见证了2012年AlexNet带来的“创世爆炸”。它就像一把开天辟地的巨斧,劈开了“手工特征”时代的混沌,证明了“深度”CNN是一条可行且强大的道路。
但AlexNet毕竟只是一个开始,它更像是一个“原型机”,虽然惊艳,但结构略显粗糙。它留给全世界一个巨大的悬念:
如果8层网络能做到这样,那18层、50层、甚至100层呢?网络是不是越深越好?
这个问题,在随后的三年里(2014-2015),引发了一场疯狂的“军备竞赛”。全球最顶尖的头脑都在思考同一个问题:如何把网络做得更深、更强?
在这场竞赛中,诞生了三个名字,它们不仅是ImageNet赛场上的冠军,更成为了定义现代计算机视觉的“三大基石架构”。它们是:
VGG:极简主义的丰碑。GoogLeNet (Inception):复杂精妙的“盗梦空间”。ResNet:打破“深度诅咒”的天才之作。
今天,我们就来一场深度穿越,去看看这三位“巨人”是如何用截然不同的哲学,搭建起现代AI之眼的“骨架”的。
一、 VGG:极简主义的胜利——“又深又小”的哲学
2014年,来自牛津大学视觉几何组(Visual Geometry Group)的VGG模型登场了。
第一眼看去,VGG简直“土”得掉渣。
熟悉元素:它没有花哨的结构。它就像用同一种乐高积木——3×3的小卷积核——反复堆叠而成。意外创新(洞察):在VGG之前,大家喜欢用大的卷积核(比如AlexNet用了11×11和5×5),认为大的能看得更“广”。VGG的反直觉:它用两个3×3的卷积核堆叠,来替代一个5×5的;用三个3×3的堆叠,来替代一个7×7的。
为什么要这么做?
视野一样大:两个3×3叠加,其“感受野”(能看到的区域)和一个5×5是一样的。参数更少:两个3×3的参数量是 2 * (3*3) = 18;一个5×5是 5*5 = 25。小卷积核反而更省参数!“非线性”更多:每堆叠一层,就多用了一次激活函数(ReLU),网络的表达能力就更强了。
思考小札
VGG的设计哲学极其深刻:大道至简。它证明了,你不需要设计复杂的结构,只要把最简单的“积木”(3×3卷积)堆得足够深(它做到了16层和19层),效果就能惊人。
VGG是模块化设计的典范。直到今天,当我们想快速搭建一个CV模型时,VGG依然是最好用的“万能骨架”。
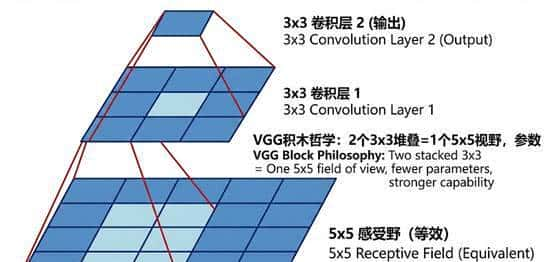
VGG的积木哲学
二、 GoogLeNet (Inception):精妙的“盗梦空间”——“既要又要”
同年(2014),Google团队带来了GoogLeNet。如果说VGG是“极简主义”,那GoogLeNet就是“复杂精妙”的代名词。
它的核心组件叫 Inception 模块(名字致敬电影《盗梦空间》)。
痛点:设计网络时,我们总是很纠结。用3×3卷积核,看得细但视野小;用5×5,视野大但看得粗。到底该用哪个?Inception的回答:小孩子才做选择,我全都要!
一个Inception模块,不再是一条单行道。它在内部并行地分出了四条路:
一条路用 1×1 卷积。一条路用 3×3 卷积。一条路用 5×5 卷积。一条路用 3×3 池化。
然后,再把这四条路的结果拼接(Concat)在一起,传给下一层。
洞察:这意味着网络在同一层里,既能看到细节(3×3),又能看到大局(5×5),还能做降维(1×1和池化)。它让网络自己去“决定”哪种特征更重要。
思考小札
GoogLeNet把网络深度推到了22层,但参数量却比AlexNet还少!它证明了,通过精巧的结构设计(拓扑结构),可以在不增加计算负担的情况下,极大地提升网络的“智商”。
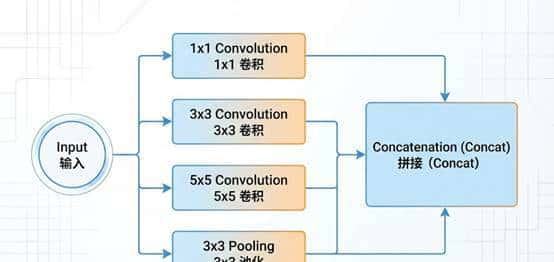
Inception模块的“并行”智慧
三、 ResNet:打破“深度诅咒”的天才之作
2015年,微软亚洲研究院的何恺明(Kaiming He)团队带来了 ResNet (残差网络)。它的出现,是深度学习历史上真正的“奇点”时刻。
在ResNet之前,VGG和GoogLeNet虽然把网络做深了,但它们都撞上了一堵看似不可逾越的墙——“退化问题”(Degradation Problem)。
3.1 “深度诅咒”:越深竟然越笨?
大家发现一个诡异的现象:当网络层数增加到一定程度(比如从20层增加到56层)时,网络的性能不仅没有提升,反而急剧下降了!
(直觉):这不合常理啊!理论上,深层网络至少应该不比浅层网络差。因为深层网络完全可以把后面多出来的层都学成“恒等映射”(Identity Mapping,即输出=输入),这样它就退化成了浅层网络。(洞察):事实证明,让一个包含无数非线性变换的网络去“学习”一个简单的“恒等映射”,竟然比登天还难!网络在层层传递中“迷失”了,学歪了。
这就是“深度诅咒”。它锁死了网络继续变深的可能。
3.2 天才的“短路”:残差连接 (Residual Connection)
何恺明团队的解决方案,简直是神来之笔。他们没有去设计更复杂的卷积核,而是在网络结构上加了一个“短路连接” (Shortcut Connection)。
传统网络:试图学习一个映射 H(x)。ResNet:
它增加了一条直接把输入 x 传到输出的“快速通道”。它让网络的主体部分去学习一个“残差函数” F(x) = H(x) – x。最终的输出是 H(x) = F(x) + x。
通俗比喻:
想象你要临摹一幅画。传统方法是给你一张白纸,让你从零开始画得和原画一模一样。这很难。ResNet的方法是:给你一张半透明的纸,盖在原画上。你只需要把原画和你画的画之间的“差异部分”(残差)描出来就行了。如果网络那一层什么都不需要学,它只要把残差 F(x) 学成 0,那么输出就自动等于输入 x(恒等映射)。这比从零学习要容易得多!
结果:这条“短路”,就像一条高速公路,让信息和梯度可以畅通无阻地在百层网络间传递。
ResNet一口气把网络深度推到了152层!ImageNet错误率直接跌破了人眼识别的极限(3.57%)。
“深度诅咒”被彻底打破。
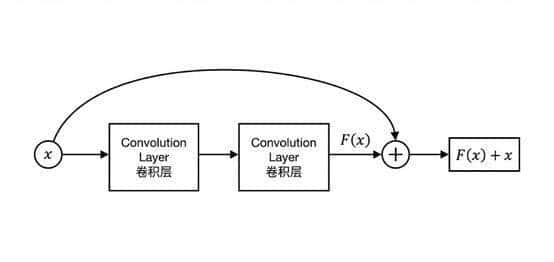
ResNet的“短路”智慧
四、 总结:三大骨架的遗产与未来
从VGG的“极简”,到GoogLeNet的“精妙”,再到ResNet的“天才短路”,这三位巨人在短短两年内,把计算机视觉的“地基”打得无比坚实。
VGG:留下了模块化设计的思想,成为了后续无数模型的“标准积木”。GoogLeNet:启发了人们对网络拓扑结构的探索,证明了“结构大于参数”。ResNet:彻底解锁了深度,成为了今天几乎所有SOTA(最先进)大模型(包括Transformer)的标配组件。没有ResNet,就没有今天的GPT。
在接下来的专栏中,我们将离开这片“纯粹模型”的赛场,带着这些强大的“骨架”,深入到更广阔的、更具挑战性的视觉任务中去。
下一篇,我们将进入专栏的第6篇:《核心感知(上)——2D世界的精细化理解:目标检测与分割》。我们将看看这些强大的骨架网络,是如何装上“瞄准镜”和“画笔”,去完成“在哪里”和“是什么形状”的复杂任务的。
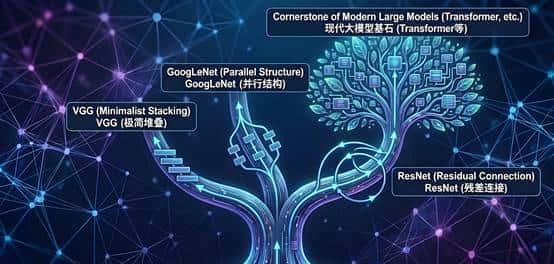
视觉骨架的进化树

















暂无评论内容