
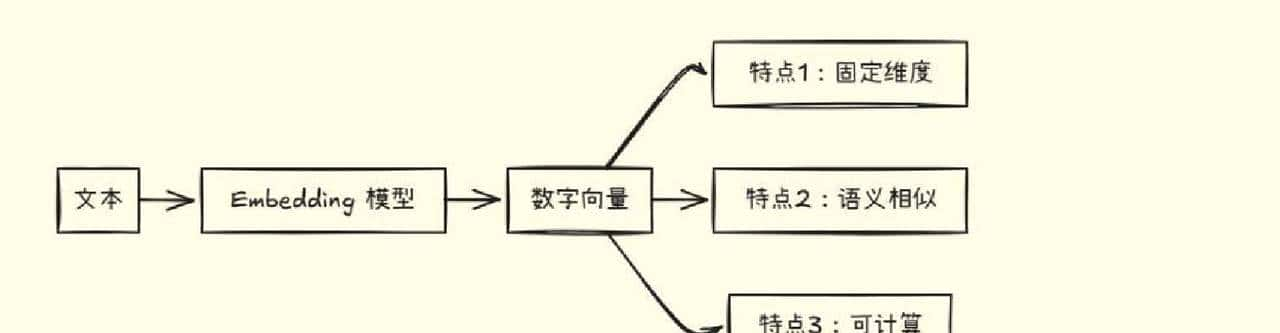
目前大多数语义检索场景里,直接把文字变成向量去比对,准确率和用户体验都上去了。把一句话变成一串数字,然后按距离去找最近的那几条,这套做法比靠关键字匹配强不少。
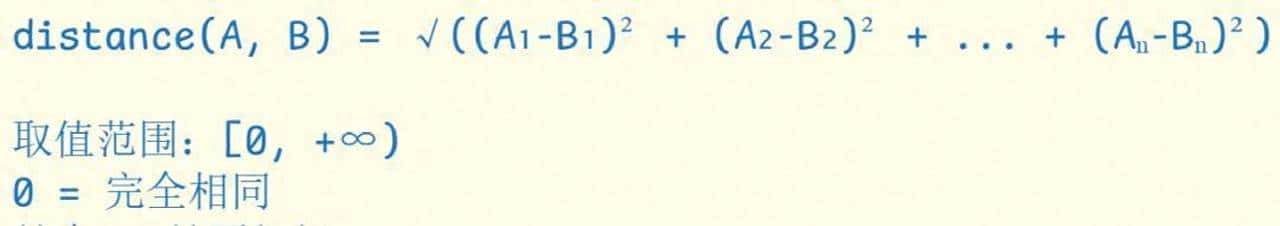
先说个直观的比喻:想象给每个人都建一份档案,传统档案是文字描述,机器找起来得靠关键词;embedding 则是把档案转成一组坐标,把类似的人放得更近。这样一来,两个意思相近但字面不同的句子,也能被认作类似。举个常见例子:用户问“如何重置密码?”,知识库里有一篇没写“重置”但讲了“找回密码”的文档,关键词搜可能漏掉,但向量检索会把这两条拉近,检索到相关结果。
再说底层是怎么判断类似的。老办法就是字符串匹配,问题很明显:容易被同义替换、顺序变化、停用词干扰。目前主流的做法是先把文本用模型编码成固定维度的向量(列如 768 或 1536 维),然后用向量类似度算相近程度。常用的类似度有几种:余弦类似度更适合做排名和语义匹配,欧氏距离常用于聚类或检测异常,点积在需要快速筛选时能省计算资源。用一句话概括就是:embedding + 向量类似度取代了单纯的字符串匹配。
关于向量维度,为什么会有 768 或 1536 这些数字?没什么神秘的,主要是模型容量和计算资源的折中。每一维并不是某个具体词的开关,而是对某类语义特征的响应强度。把维度想象成许多把小铲子,每把铲子挖的是某种语义“坑”,叠加起来就能比较全面地描述一段话。维度越高,理论上能捕捉越细的差别,但计算和存储代价也随之上升。
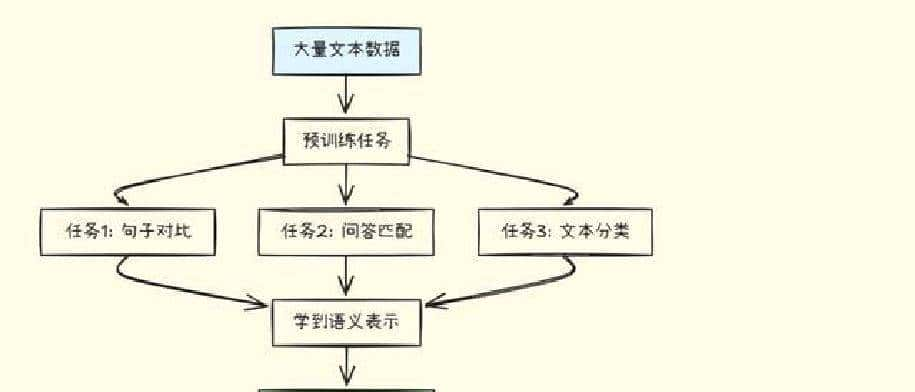
训练方式也有几条路可走。可以用对比学习,把正样本和负样本配对训练,让模型把类似语句拉近,不类似的推远;可以用监督学习,直接在下游任务上微调;也可以用无监督的方法,列如掩码语言模型预训练,再做微调。不同的训练策略,会影响向量里到底学到了哪些语义信息。

把技术放到工程里,遇到的另一个现实问题是规模。假设有一百万条文档的 embedding,直接暴力比对一条查询会很慢。解决办法是用向量数据库和近似最近邻搜索算法,列如 HNSW、IVF 之类的索引结构,甚至量化存储来节省空间和提高吞吐。向量数据库的核心概念包括索引构建、向量压缩、分片与并行检索,这些决定了系统在大规模场景下的速度和成本。
功能层面,embedding 带来的变化挺明显的。检索和排序的相关性提升了,推荐系统能更好理解用户意图,文档聚类也更贴合语义。应用场景很广:聊天机器人、知识库问答、内容召回、个性化推荐,许多地方都在用这套思路。至于在中文检索上的表现,各类基准测试显示语义检索能提高召回率和排序质量,不过效果受训练数据、模型规模和索引策略影响明显。
具体到类似度的计算,这里简单说下常用公式:余弦类似度是把两个向量的点积除以模长乘积,值越接近 1 表明方向越一致;欧氏距离直接量两个向量之间的直线距离,适合测量“位移”量;点积则是快速估算相关度,在一些向量已经被归一化或经过特定调整的场景下很有用。工程上常用余弦做排序,用点积或其他手段做初筛,再用更精细的类似度校验。
回到实践,构建一套可用的 embedding 检索系统,一般要经历这些环节:数据清洗与正负样本构造、选择编码模型并训练或微调、把文本编码成向量并入库、选择合适的索引和类似度计算方式、在线上做 A/B 测试不断迭代。每一步都有陷阱:列如负样本选不好会导致模型无法区分细粒度差别;索引参数调得不合适会牺牲召回或延迟。

技术层面以外,还有一些工程取舍必须做。向量维度、索引类型、是否做量化、在线检索延迟预算、批量更新频率,这些都会影响系统成本和效果。举个常见权衡:要么用更大模型提高向量质量但算力和延迟增加;要么用较小模型配合更好的索引策略和在线重排,达到相对平衡。
最后贴个小提示:在从关键词检索迁移到语义检索的过程中,往往需要保留一套混合策略。把传统关键词得分和向量类似度混在一起做融合检索,既能保底也能充分利用语义匹配的优势。说到底,这套东西挺灵活,也的确 解决了许多实际问题。





![Vue – 路由传一个Object参数,刷新页面后数据变成“[Object Object]“ 解决方案 - 鹿快](https://img.lukuai.com/blogimg/20251203/cced8eb09e2f4e29b599273ea9f71b5e.jpg)












- 最新
- 最热
只看作者