
一、DeepSeek R1低成本本地部署方案介绍
1. KTransformer与Unsloth动态量化方案介绍
截至目前,DeepSeek R1模型本地部署最具性价比的方案就是清华大学团队提出的KTransformer方案和Unsloth动态量化方案,两套方案都是借助CPU+GPU混合推理,来降低GPU购买的硬件成本,并且底层CPU推理实现也都是基于llama.cpp。
- ktransformers:https://github.com/kvcache-ai/ktransformers

- Unsloth:https://github.com/unslothai/unsloth

- llama.cpp:https://github.com/ggml-org/llama.cpp

所不同的是,KTransformer采用了一种全新的计算流程,使得MLA/KV-Cache可以在GPU上运行,而其他模型参数则在CPU上完成计算,从而大幅加快CPU的计算速度。
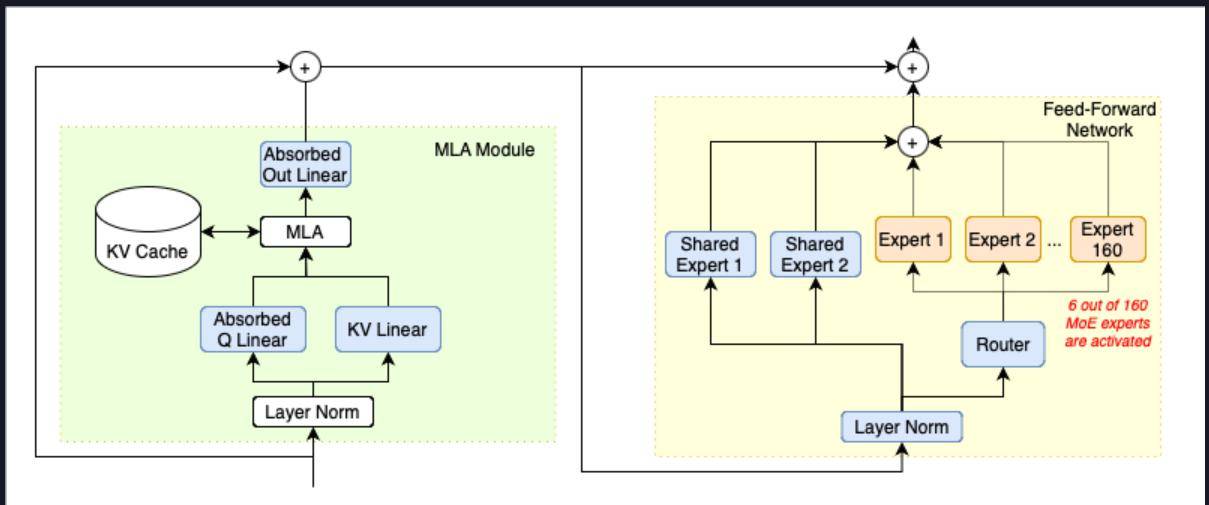
这种计算流程能够大幅加快DeepSeek MoE架构算法的计算速度,根据官方给出的数据,最高能得到14tokens/s,是llama.cpp推理速度的两倍。
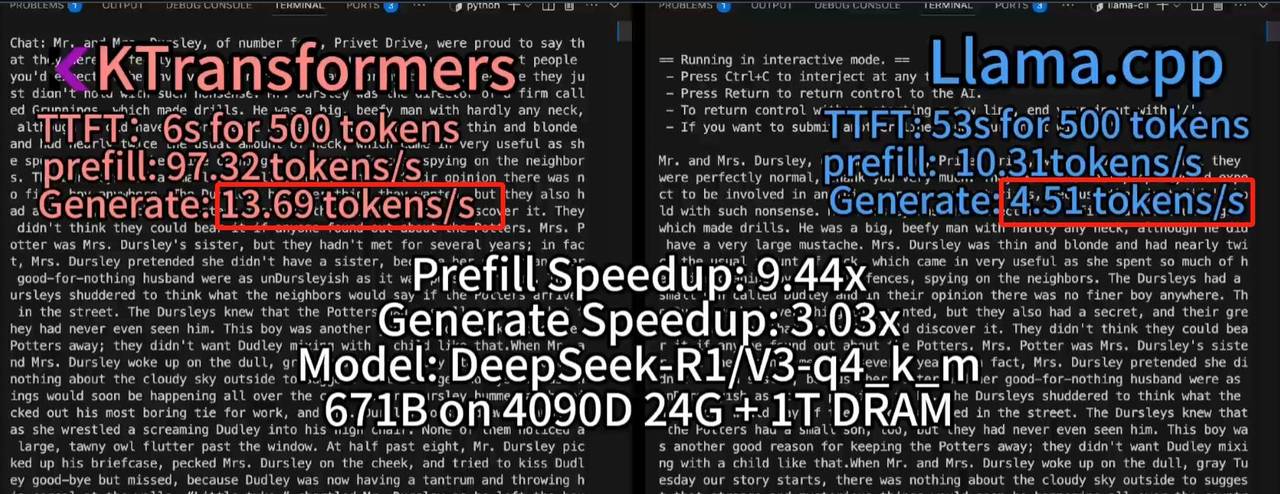
但这套方案存在的问题,则主要有以下两个:
- 其一是模型并发较弱,由于采用了超级特殊的计算结构,导致无法通过增加GPU数量来增加并发;
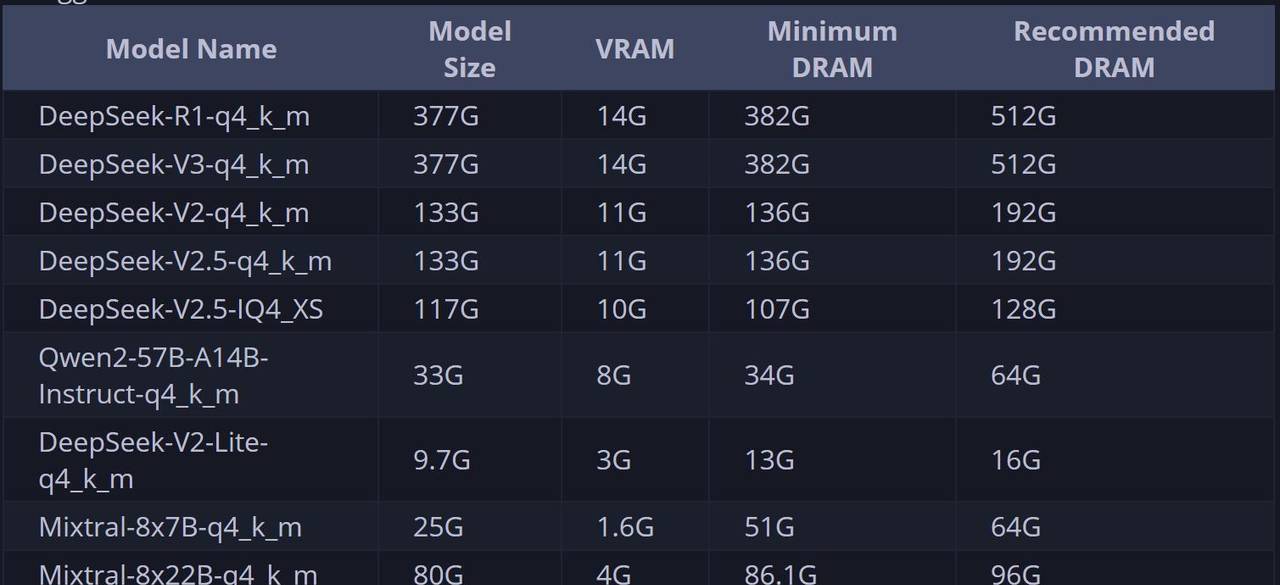
- 其二是需要较大内存才能运行,官方给出的不同模型推理所需内存占用如下:
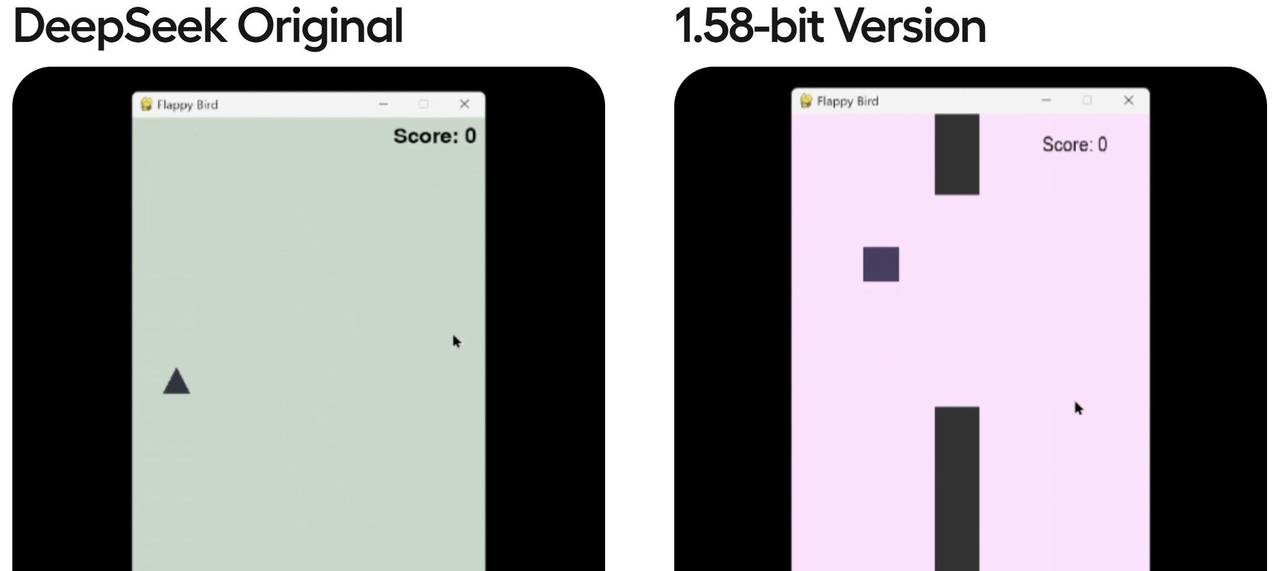
Unsloth提出的动态量化方案会更加综合一些,所谓动态量化的技术,指的是可以围绕模型的不同层,进行不同程度的量化,关键层呢,就量化的少一些,非关键层量化的多一些,最终得到了一组比Q2量化程度更深的模型组,分别是1.58-bit、1.73-bit和2.22-bit模型组。尽管量化程度很深,但实际性能实则并不弱。根据测试结果,1.58-bit动态量化几乎能达到90%以上Q4_K_M性能,远比Q2_K_M性能强得多。

此外,Unsloth提供了一套可以把模型权重分别加载到CPU和GPU上的方法,用户可以根据自己实际硬件情况,选择加载若干层模型权重到GPU上,然后剩下的模型权重加载到CPU内存上进行计算。
在实际部署的过程中,我们可以根据硬件情况,有选择的将一部分模型的层放到GPU上运行,其他层放在CPU上运行,从而降低GPU负载。最低显存+内存>=200G,即可运行1.58bit模型。

单卡4090(24G)时可加载7层权重在GPU上运行,40并发达到3.5tokens/s,双卡A100服务器能加载全部0到61层模型权重到GPU上,吞吐量达到140tokens/s,100并发时单人能达到14 tokens/s:

简而言之,Unsloth方案优势如下:
- 和llama.cpp深度融合,直接通过参数设置即可自由调度CPU和GPU计算资源,灵活高效,且能够直接和ollama、vLLM、Open-WebUI等框架兼容。
- 深度挖掘GPU性能,并发量有保障。
2. 最高性价比方案:KTransformers+Unsloth结合部署方案
而自从这两套方案诞生以来,就有许多小伙伴畅想,能不能将这两个方案结合起来部署呢?一方面,借助Unsloth 1.58bit动态模型的高性能特性,一方面借助KTransformers的高性能计算特性,就能进一步压缩硬件成本、获得更好的计算性能,同时由于1.58bit动态量化模型本身占用存储空间更少,推理并发数量也能有所提升。
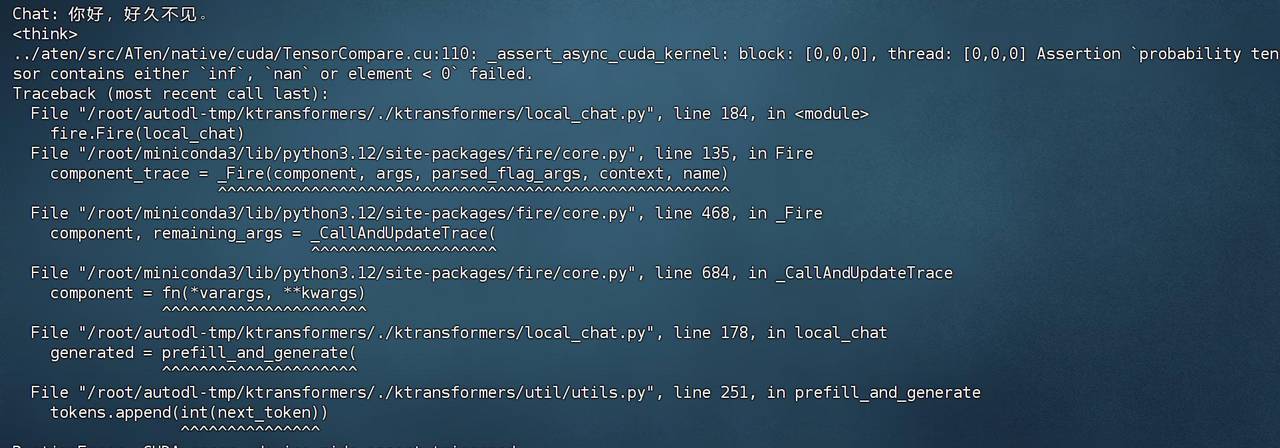
这的确 是超级不错的思路,并且由于动态量化本身并没有改变模型结构,因此理论上也是可行的。但很遗憾,截至目前,KTransformers的三个版本,V0.2、V0.21和V0.3暂时都不支持Unsloth动态量化模型的推理。目前官方稳定版在运行Unsloth动态量化模型时会出现如下报错:
因此,我们团队在深入研究KTransformers源码后,对V0.2版本的部分代码进行了修改,并最终适配1.58bit Unsloth动态量化模型,使得最低可以在60G内存、14G显存下顺利运行,至强3代CPU+DDR4+虚拟GPU运行时效果如下:
实际内存使用约60G:

显存使用约10G:
需要注意的是,一样1.58bit模型,若使用Unsloth+llama.cpp运行方案,则需要至少4卡4090(分配35层在GPU上计算)才能达到一样的效果。
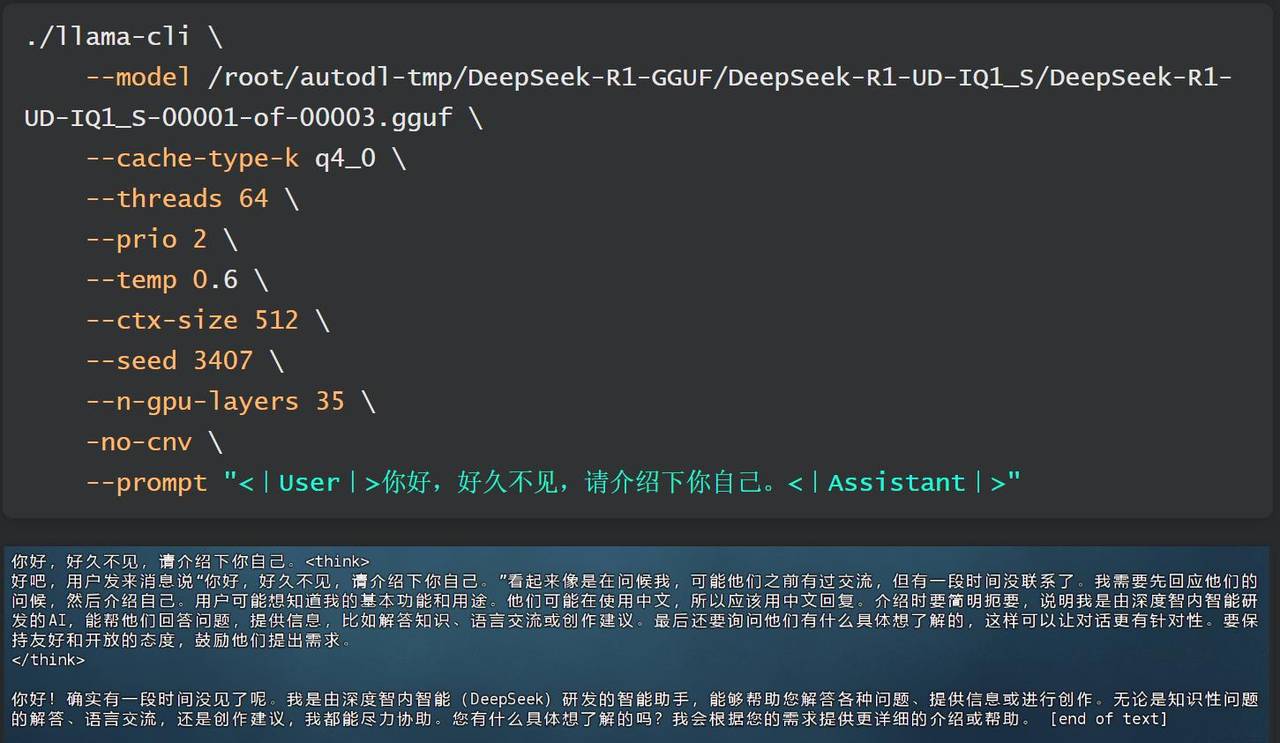
并且在硬件配置达标的情况下,如至强4代以上+DDR5,则能达到12 tokens/s,且在5个左右并发时,能达到6-8 tokens/s。本节公开课,我们就来详细介绍下如何实现KTransformers+Unsloth联合部署。
纯GPU推理时,1.58bit模型需要双卡A100服务器能加载全部0到61层模型权重到GPU上,吞吐量达到140tokens/s,100并发时单人能达到14 tokens/s:

但此时服务器成本接近60万,因此对比之下,本节公开课介绍的KT+Unsloth结合方案,是目前本地部署DeepSeek R1最佳性价比方案没有之一。
蒸馏模型 VS 量化模型
从实际使用性能来说,量化模型性能远好于蒸馏模型。可以这么理解,最强蒸馏模型约和o1-mini性能相当。
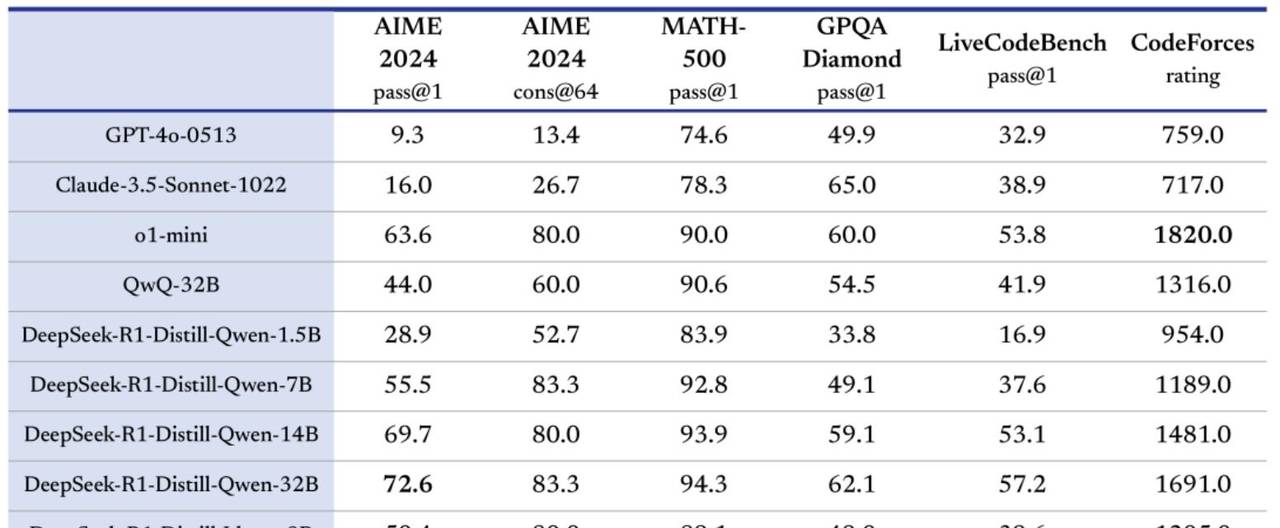
而DeepSeek的量化模型,哪怕是Q2量化,性能也要远强于o1-mini,约是原版模型的70%左右,而Q4量化模型和1.58bit模型性能相当,约是原版模型的75%-80%左右。
DeepSeek及量化模型部署条件
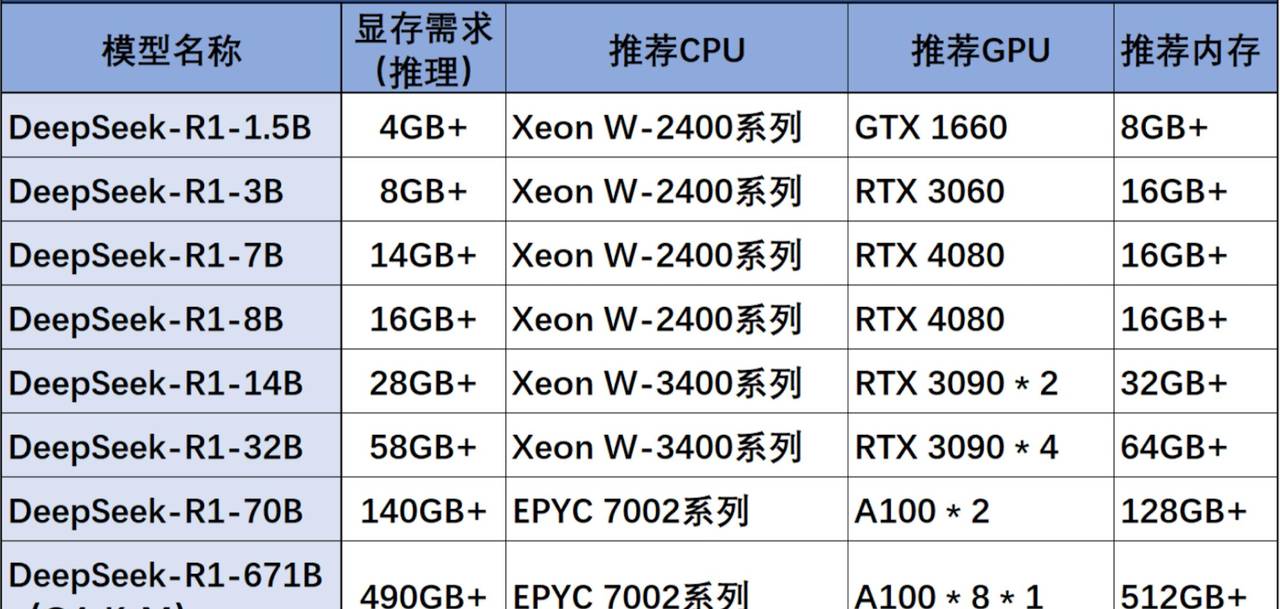
3.KTransformers本地部署硬件配置说明
这里需要说明的是,KTransformers项目本身运行效果极大程度依赖CPU和内存型号,一般来说至强4代或第四代霄龙+DDR5才能保证14tokens/s。
- 配置环境:
- PyTorch 2.5.1,Python 3.12(ubuntu22.04),Cuda 12.4
- 操作系统:Ubuntu 22.04
- GPU:vGPU-32GB(32GB) * 1升降配置
- CPU:16 vCPU Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10GHz
- 内存:90GB DDR4
- 若无相关软件环境,也可以思考在AutoDL上租赁显卡并配置Ubuntu服务器来完成操作。最小化实现微调效果,仅需单卡租赁最便宜的vGPU运行两小时即可得到结果,仅需不到5元即可完成实操:

- KTransformer项目部署硬件配置方面需要注意如下事项:
- GPU对实际运行效率提升不大,单卡3090、单卡4090、或者是多卡GPU服务器都没有太大影响,只需要留足14G以上显存即可;
- 若是多卡服务器,则可以进一步尝试手动编写模型权重卸载规则,使用更多的GPU进行推理,可以必定程度减少内存需求,但对于实际运行效率提升不大。最省钱的方案依旧是单卡GPU+大内存配置;
- KTransformer目前开放了V2.0、V2.1和V3.0三个版本(V3.0目前只有预览版,只支持二进制文件下载和安装),其中V2.0和V2.1支持各类CPU,但从V3.0开始,只支持AMX CPU,也就是最新几代的Intel CPU。这几个版本实际部署流程和调用指令没有任何区别,公开课以适配性最广泛的V2.0版本进行演示,若当前CPU支持AMX,则可以思考使用V3.0进行实验,推理速度会大幅加快。
- CPU AMX(Advanced Matrix Extensions)是Intel在其Sapphire Rapids系列处理器中推出的一种新型硬件加速指令集,旨在提升矩阵运算的性能,尤其是针对深度学习和人工智能应用。
- 服务器物理机成本(比课程演示性能降低30%左右)
- KTransformers+Unsloth方案极限配置下,最低仅需4500左右,具体配置如下:
|
硬件 |
详细型号 |
价格 |
|
主板 |
华南 X99-TF+ E5 板 U 套装(2696V3)+ A700 风扇 |
800元 |
|
CPU |
英特尔至强 E5-2696V3(18 核 36 线程) |
(包含在主板套装) |
|
内存 |
三星二手服务器拆机内存 DDR4 ECC 64GB |
270 |
|
固态硬盘 |
光威(Gloway)M.2 1TB PCIe 4.0 读取速度 7000MB/s |
400 元 |
|
电源 |
长城 1000DA 金牌巨龙 1000W 电竞版 |
600 元 |
|
机箱 |
爱国者 黑曼巴 F2 黑色 E-ATX 机箱 |
180 元 |
|
显卡 |
NVIDIA RTX 2080 Ti 22GB |
2500 元 |
|
合计 |
4750 元 |
- 实际性能
- 推理性能:约在3-5tokens/s;
- 并发性能:在5个用户,平均每隔1秒发送一个请求时,处理了50-100请求时,响应速度约为2个token/s。
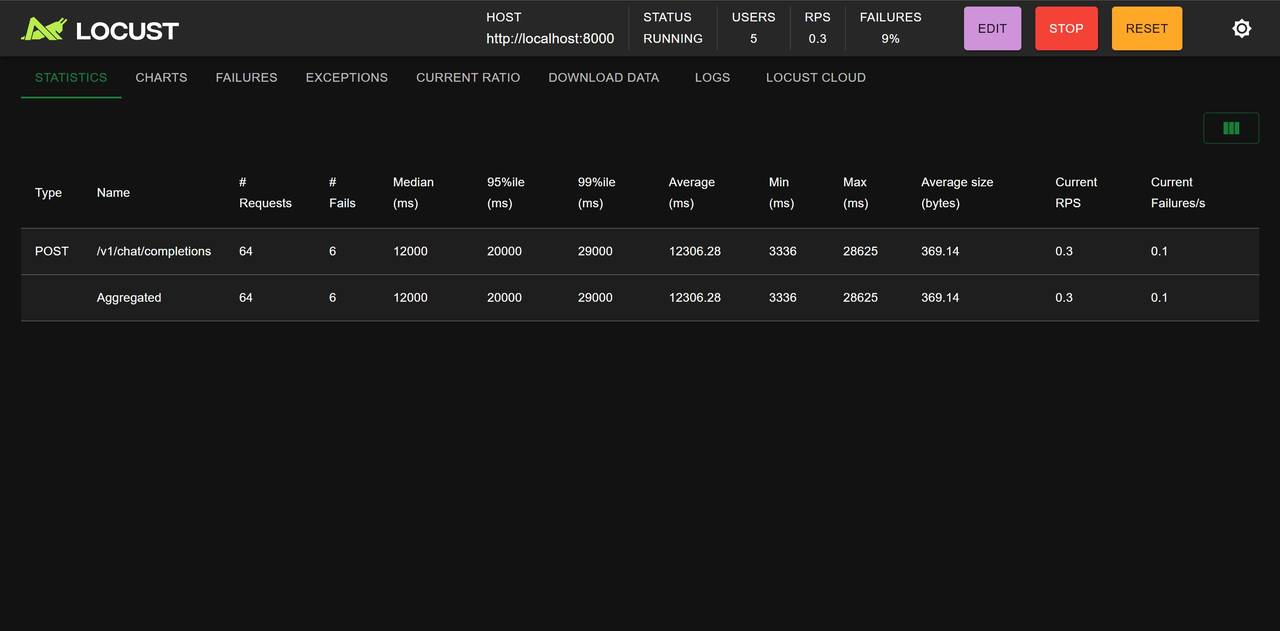
至此部署方案介绍完成,下次实操一下。
#Manus火爆程度堪比DeepSeek##Manus和DeepSeek的差别是什么##女生按DeepSeek提示找到丢失金项链##
















- 最新
- 最热
只看作者