
引言
随着AI技术的不断突破,大模型的计算需求变得越来越庞大,而硬件性能的提升也在不断推高AI应用的边界。对于AI开发者和研究人员来说,选择合适的硬件和平台对提升工作效率至关重大。今天,我们将聚焦于Mac Studio M3 Ultra 512GB这台服务器,测试LM Studio和Ollama在其上的表现。
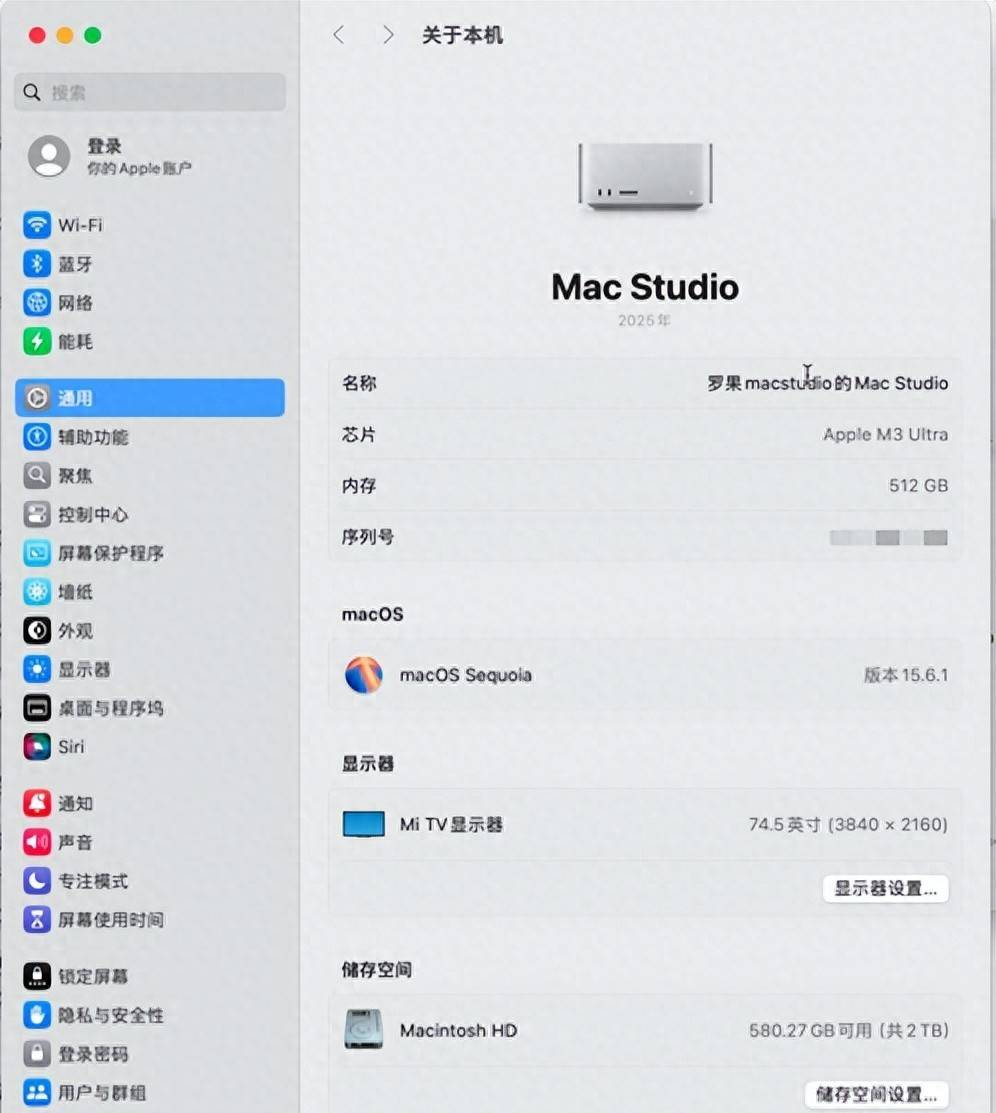
机器配置
本次对比测试的模型包括:qwen3 14b fp16、qwen3 32b fp16、gemma3:27b-it-fp16、deepseek-v3.1:671b、gpt-oss:20b、gpt-oss:120b。我们选择了几个任务来考察它们的综合能力,任务包括:数值比较、字母统计、经典诗词背诵以及高难度的作文生成。与此同时,我们还将对比两个平台在首字响应时间和Tokens每秒等性能指标上的差异。
评测模型与任务
此次测试我们使用了多种大型语言模型,并设置了以下几个具有挑战性的任务:
- “2.11 和 2.2 哪个大?”
一个简单的数值比较任务,主要考察模型的基础数学处理能力。 - “deepseek vs qwen 里面有几个字母 e?”
这道任务旨在测试模型的字母统计能力,考察它们对细节的关注和理解。 - “背诵毛主席的《沁园春·雪》”
经典诗词的背诵任务,测试模型的记忆和语言表达能力,考察其在长文本理解和回忆方面的准确性。 - “写800字的《沁园春·雪》读后感议论文,题目自拟”
这一任务考察模型的创意生成能力,要求模型根据《沁园春·雪》这首诗,生成一篇符合高考满分作文标准的议论文。
评测指标
本次评测主要从以下几个维度进行对比:
- 答案准确性:对于实际性问题,模型是否能够给出正确的答案。
- 背诵准确性:模型是否能够准确背诵经典诗词《沁园春·雪》。
- 作文评分:生成的议论文是否符合高考满分作文标准。我们将利用ChatGPT的自动评分系统,来比较两个平台生成文章的质量。
- 性能指标:
- 首字时间:模型首次输出的响应时间。
- Tokens每秒:模型处理文本的吞吐量,即每秒处理多少个tokens。
测试结果与分析
Ollama测试数据

Ollama测试
|
测试模型 |
qwen3 14b fp16 |
qwen3 32b fp16 |
gemma3:27b-it-fp16 |
deepseek-v3.1:671b |
gpt-oss:20b |
gpt-oss:120b |
|
任务1:数值比较 |
答案:正确,首字时间:0.86s,20.73 tokens/s |
答案:正确,首字时间:2s,9.56 tokens/s |
答案:正确,首字时间:2.33s,11.31 tokens/s |
答案:正确,首字时间0.5,21.07 tokens/s |
答案:正确,首字时间:0.17s,97.35 tokens/s |
答案:正确,首字时间:1.57s,66.74 tokens/s |
|
任务2:字母统计 |
答案:正确,首字时间:1.06s,20.66 tokens/s |
答案:正确,首字时间:0.87s,10.06 tokens/s |
答案:错误,首字时间:2.27s,11.29 tokens/s |
答案:正确,首字时间:10.54s,20.25 tokens/s |
答案:正确,首字时间:0.42s,98.09 tokens/s |
答案:正确,首字时间:1.8s,65.94 tokens/s |
|
任务3:背诵《沁园春·雪》 |
答案:正确,首字时间:0.987s,20.28 tokens/s |
答案:正确,首字时间:0.86s,10.05 tokens/s |
答案:正确,首字时间:2.27,11.06 tokens/s |
答案:正确,首字时间:1.03s,19.58 tokens/s |
答案:错误,首字时间:0.49s,92.52 tokens/s |
答案:错误,首字时间:1.74s,66.33 tokens/s |
|
任务4:800字议论文 |
答案:90分,首字时间:1.18s,19.73 tokens/s |
答案:92分,首字时间:1.07s,10.01 tokens/s |
答案:88分,首字时间:2.26s,10.81 tokens/s |
答案:95分,首字时间:14.74s,18.14 tokens/s |
答案:72分,首字时间:1.14s,92.94 tokens/s |
答案:76分,首字时间:2.03s,65.22 tokens/s |
|
综合表现 |
全部正确 |
全部正确 |
错1题 |
全部正确 |
对中文语料支持不好 |
对中文语料支持不好 |
LM Studio测试数据
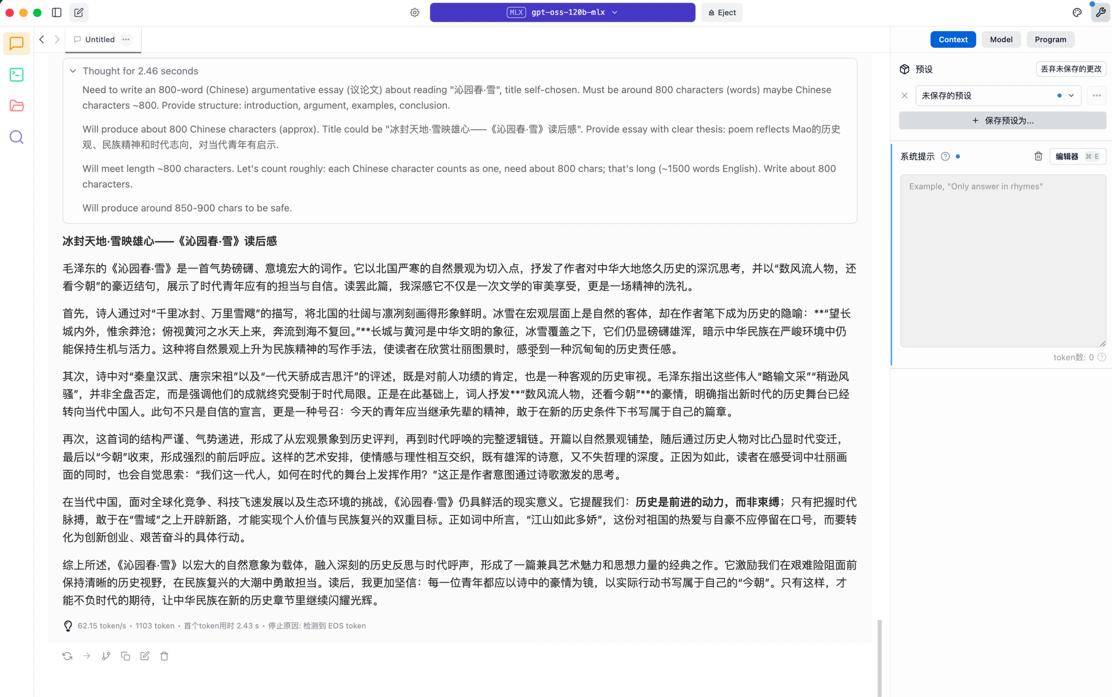
LM Studio运行
测试项目
|
测试模型 |
qwen3 14b fp16 |
qwen3 32b fp16 |
gemma3:27b-it-fp16 |
deepseek-v3.1:671b |
gpt-oss:20b |
gpt-oss:120b |
|
任务1:数值比较 |
答案:正确,首字时间:0.21s,22.62 tokens/s |
答案:正确,首字时间:0.45s,10.05tokens/s |
答案:正确,首字时间:2.33s,10.08 tokens/s |
答案:正确,首字时间:10.26s,15.59 tokens/s |
答案:正确,首字时间:0.932s,93.98 tokens/s |
答案:正确,首字时间:0.17,66.45 tokens/s |
|
任务2:字母统计 |
答案:正确,首字时间:0.46s,22.55 tokens/s |
答案:正确,首字时间:2.68s,9.40 tokens/s |
答案:错误,首字时间:0.41s,11.61 tokens/s |
答案:正确,首字时间:13.1s,14.14 tokens/s |
答案:正确,首字时间:1.26s,94.17 tokens/s |
答案:正确,首字时间:0.21s,65.94 tokens/s |
|
任务3:背诵《沁园春·雪》 |
答案:正确,首字时间:0.49s,22.5 tokens/s |
答案:正确,首字时间:2.63s,9.26 tokens/s |
答案:错误,首字时间:0.41,11.41 tokens/s |
答案:正确,首字时间:11.88s,14.36 tokens/s |
答案:错误,首字时间:0.47s,92.57 tokens/s |
答案:错误,首字时间:0.934s,62.78 tokens/s |
|
任务4:800字议论文 |
答案:93分,首字时间:0.48s,22.24 tokens/s |
答案:92分,首字时间:2.87s,9.04 tokens/s |
答案:83分,首字时间:0.41s,11.29 tokens/s |
答案:89分,首字时间:13.27s,13.22 tokens/s |
答案:88分,首字时间:2.59s,92.3 tokens/s |
答案:93分,首字时间:2.43s,62.15 tokens/s |
|
综合表现 |
全部正确 |
全部正确 |
错1题 |
全部正确 |
对中文语料支持不好 |
对中文语料支持不好 |
总结与提议
通过对比测试,Mac Studio M3 Ultra 512GB版在LM Studio和Ollama两大平台上展现了不错的性能。相对来说LM Studio在首字输出时间、tokens每秒和作文评分方面占据了必定优势。Ollama则在小模型的响应速度和吞吐量方面展现了必定的优势,但是对于大一些的高精度的模型速度会慢一些,尤其是首字输出时间。
通过对qwen3 14b fp16、qwen3 32b fp16、gemma3:27b-it-fp16、deepseek-v3.1:671b、gpt-oss:20b、gpt-oss:120b等几个模型的对比,发目前上述的几个场景中,国产模型有相当的优势,列如gemma3在数字符方面不太准确,gpt-oss的两个模型在中文语料方面支持不太好,而且幻觉严重。因此处理中文信息提议还是采用国产模型。当然,gpt-oss的相应速度是超级不错的。总体测试下来,4bit量化的速度比fp16的速度提升明显,即使是deepseek V3.1的4位量化模型,每秒的tokens也能有20左右。
今天的测试就到这里,希望这些信息对您的选择有参考意义。



![[C++探索之旅] 第一部分第十一课:小练习,猜单词 - 鹿快](https://img.lukuai.com/blogimg/20251015/da217e2245754101b3d2ef80869e9de2.jpg)













- 最新
- 最热
只看作者