
就在本月21号,DeepSeek刚发了个新模型,叫DeepSeek-OCR。
一开始我以为就是个普通的文字识别工具,没太当回事,结果翻了翻论文和开发者反馈,发现这东西还真有点东西。
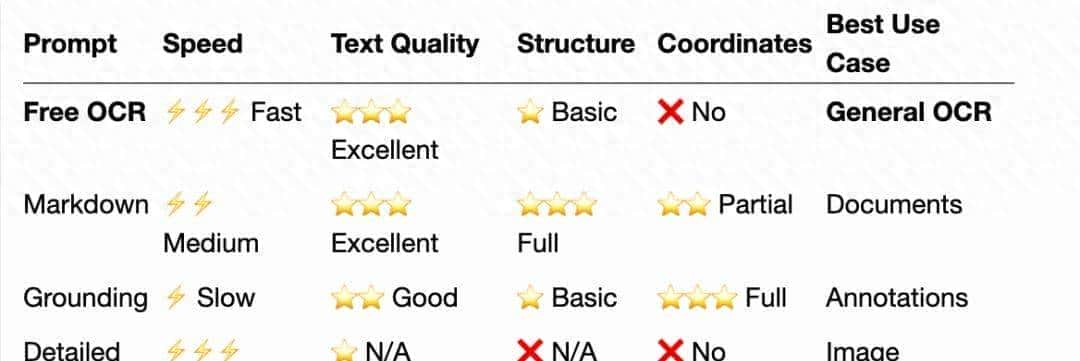
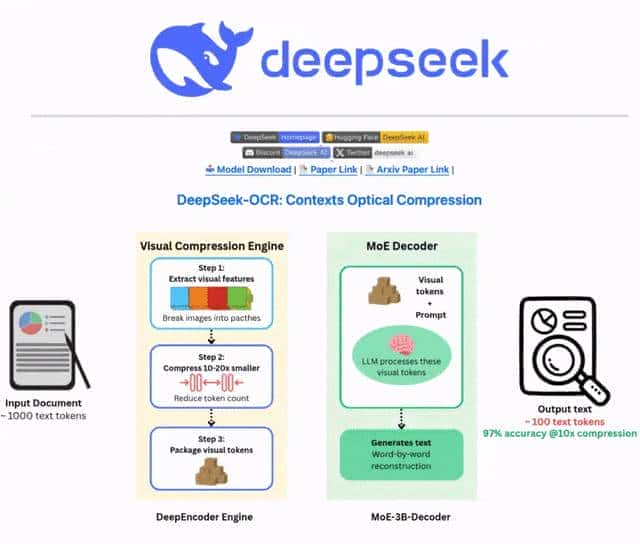
它是个专门调过OCR的模型,大小6.6GB。
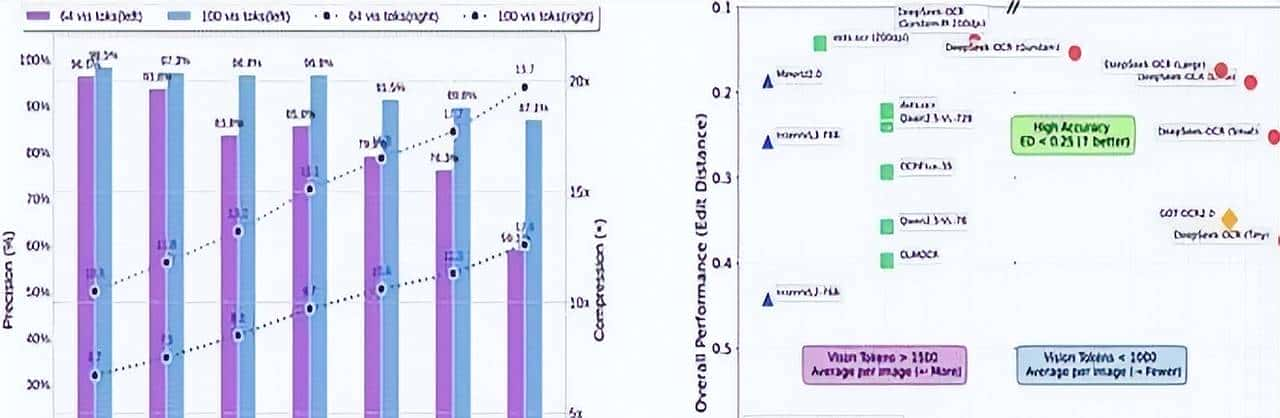
最核心的亮点,是第一次把“视觉-文本token压缩比”给量化了10倍压缩的时候,精度几乎没损失;就算压到20倍,精度还能保住60%。
本来想忽略这个压缩比的细节,但后来发现,这对要处理大量文档的人来说,简直是救星。
之前帮朋友处理扫描件,大模型总由于token不够报错,目前这压缩能力,相当于给文档“瘦身”还不丢内容。
还有个叫DeepEncoder的设计,也挺有意思。
之前的编码器总陷在“要高清就占内存,要省token就糊”的死循环里,这个DeepEncoder居然把这三个需求给平衡了。
Karpathy都直接说“我很喜爱这篇论文”,能让这位AI圈的大佬这么夸,可见这技术的确 有点东西。
不过最让我在意的,不是它识别多准,而是它抛出的一个问题:对大模型来说,像素是不是比文本更好的输入?简单说,就是咱们一直用的文本token,会不会实则是种“浪费又麻烦”的方式?

Tokenizer要被淘汰?视觉输入可能改写AI规则
本来想反驳这个观点,毕竟文本token用了这么久,突然说要换,总觉得不踏实。
但后来仔细想了想,视觉输入还真有不少优势。
第一是信息压缩更高效,论文里也提了,同样的上下文窗口,图像能塞更多内容,推理速度自然快。
之前我用模型处理长文档,光等token加载就半天,要是换成图像输入,这时间能省不少。
然后是信息更全,文本只能看字,可文档里的加粗、颜色、插图这些,文本token根本处理不了。
列如我之前做PPT解析,模型总把红色的重点当成普通文字,要是用图像输入,这些视觉信息就能自然带进去,不用额外做标注。

最关键的是,它能摆脱Tokenizer,我对Tokenizer早就有点烦了。
它把模型弄得不是端到端的流程,还带着Unicode、字节编码这些老包袱,甚至会让两个看着一样的字符,在模型里变成完全不同的token。
更麻烦的是安全问题,列如续字节攻击,之前圈内就有人踩过坑。
目前这模型用视觉输入,等于直接绕开了这些麻烦,说真的,这步走得挺妙。
Pleiasfr的联合创始人AlexanderDoria说得更直接,他说这模型是“里程碑式的工程成就”,可能是未来OCR系统的起点。
不过他也没吹得太满,说模型训练用了不少合成数据,真实场景的数据还不够多样,要落地到具体行业,还得做定制。
这点我挺认同,毕竟实验室里的好成绩,到了真实的金融票据、医疗报告里,未必能直接用。

从40分钟跑通模型看落地:ClaudeCode成了神助攻
模型再好,不能落地也是白搭。
好在已经有开发者试过水了,列如资深开发者SimonWillison,他花了40分钟就把这模型跑在了NVIDIASpark上,而且靠的还是ClaudeCode。
这事说起来还挺有意思,Simon一开始就知道,在Spark这种ARM平台上跑PyTorchCUDA模型,肯定会折腾。
无奈之下,他干脆把整个流程交给ClaudeCode,还给了它Docker沙箱的root权限。
本来想看看AI能不能搞定,结果它还真没让人失望1次长指令加3次短补充,就把环境搭好了。
中间还出了个小插曲,PyTorch2.5.1不支持新GPU,ClaudeCode愣是自己爬官网,找到了支持ARM的PyTorch2.9.0版本。

换我自己找,可能得花一两个小时,AI这效率的确 没话说。
不过最后生成的结果文件是空的,Simon提醒了一句,ClaudeCode又去翻README,试了好几个提示词模式,还总结了个PROMPTS_GUIDE.md,最后把所有东西打包好给了Simon。
从15点31分到16点10分,不到40分钟,Simon说自己只参与了10分钟,剩下的都是AI在弄。

作为一个之前搭PyTorch环境总失败的人,我特别能理解他说的“大胜利”。
这不仅说明模型好搭,更说明AI辅助开发已经到了能解决实际问题的程度,后来开发者可能真能省不少事。
目前这模型已经在不少场景试了水,列如金融里的财报图表转Markdown,科研里的化学分子式识别,政务里的医疗票据处理。
尤其是医疗票据,错误率能压到很低,之前人工审一张要好几分钟,目前模型处理快多了。
不过话说回来,不同行业的需求不一样,列如法律合同里的特殊格式,可能还得再调参数,不能指望一个模型包打天下。
Alexander还提到,OCR本质是“模式识别”,不用太多推理或长记忆,所以模型不用做太大。

DeepSeek-OCR只用了12层架构,每次推理只激活5亿参数,既能处理大量数据,又不占太多资源。
这倒是给行业提了个醒,不必定参数越大越好,对症下“模”才是关键。
总的来说,DeepSeek-OCR不光是个好用的OCR工具,更可能是AI输入方式的一个转折点。

后来用户输入可能都是图像,模型输出还是文本,既保留了文本的便捷,又利用了图像的高效。
虽然目前离全视觉输入的AI应用还有距离,但至少已经有了方向,说不定明年,我们就能用上“只认图片”的聊天机器人了,想想还挺期待的。



![[C++探索之旅] 第一部分第十一课:小练习,猜单词 - 鹿快](https://img.lukuai.com/blogimg/20251015/da217e2245754101b3d2ef80869e9de2.jpg)













暂无评论内容