
【AI学习-comfyUI学习-Segment Anything分割+实时图像裁剪-各个部分学习-第九节2】
1,前言2,说明1:第九节3-Segment Anything分割工作流🧠 一、视觉层面的本质:**图像中的“潜在边界理解”**SAM 是怎么工作的?
💬 二、语言层面的本质:**文本驱动的目标定位**它做了什么?
🔄 三、融合机制的本质:**语义 → 几何 → 像素级边界**🧩 四、底层逻辑用一句话总结:⚙️ 五、为什么这套机制强?🔬 六、类比理解
3,流程1-第九节3-Segment Anything分割工作流(1)调用模块整个模块部分
(2)输出 提示词(3)模型加载(4)生成图片(5)模块介绍参数说明🧩 一、总体思路🧱 二、节点解析① 加载图像(左上)② SAM 模型加载器(#2 comfyui_segment_anything)③ G-DINO 模型加载器(#3 comfyui_segment_anything)④ G-DINO + SAM 组合分割(#4 comfyui_segment_anything)⑤ 显示图像⑥ 保存图像⑦ LayerStyle(图层样式)
🎯 三、最终输出内容
4,细节部分5,使用的工作流6,总结
1,前言
最近,学习comfyUI,这也是AI的一部分,想将相关学习到的东西尽可能记录下来。
2,说明
1:第九节3-Segment Anything分割工作流
🧠 一、视觉层面的本质:图像中的“潜在边界理解”
Segment Anything(SAM)的核心,是一个通用的图像分割模型。
它本质上不会理解语义,但非常擅长“找出像素之间的分界”。
SAM 是怎么工作的?
它先用一个 Vision Transformer (ViT) 把整张图像切成小块(Patch)。模型学习这些块之间的关系,得到一个“图像 embedding”,即图像的潜在语义表征。当你给出一个提示(点、框、mask),SAM 就会激活对应区域的向量,从而预测出那部分区域的精确边界。
👉 换句话说:
SAM 就像一个“只看像素、不懂语义”的超级抠图器。
它知道“这里有个东西的边缘”,但不知道“那是头发还是背景”。
💬 二、语言层面的本质:文本驱动的目标定位
Grounding DINO 的本质是一个视觉-语言对齐模型。
它做了什么?
它将图片通过图像编码器变成一堆视觉特征(特征图)。它将文字提示(如 “hair”) 通过文本编码器变成语义特征向量。模型学习“哪些区域与文字描述最相关”,从而生成一个目标框 (bounding box)。
👉 简单讲:
Grounding DINO 会告诉系统:“图片中这里就是‘hair’所在的区域”。
🔄 三、融合机制的本质:语义 → 几何 → 像素级边界
当两者结合时,就产生了你看到的「G-DINO + SAM」分割机制:
| 阶段 | 模块 | 本质作用 |
|---|---|---|
| 1️⃣ 文本提示 | “hair” | 给出语义目标 |
| 2️⃣ Grounding DINO | 从语义找到目标大致位置(框) | |
| 3️⃣ SAM | 在这个框里找到像素级边界 | |
| ✅ 输出 | 精确的“头发”遮罩 |
本质上是一个 “语义定位 → 几何边界 → 像素掩膜” 的流水线机制。
🧩 四、底层逻辑用一句话总结:
Grounding DINO 让机器“理解你在说什么”,SAM 让机器“精确抠出那部分”。
或者更大白话一点讲:
你告诉机器“找头发”,
Grounding DINO 会说:“头发大概在这里”,
SAM 会说:“好,我把这块区域的边界精确勾出来给你看”。
⚙️ 五、为什么这套机制强?
泛化性极强:SAM 不需要针对每类物体训练,只要知道“哪里是边界”即可。语言可控:Grounding DINO 让人类能用“文字”去驱动图像理解。组合自由:你可以在 ComfyUI 中接上任意下游任务,比如替换背景、LoRA 生成、mask 扩散等。
🔬 六、类比理解
这套机制就像一个“双人小组”:
🕵️ Grounding DINO 是“指挥官”,理解命令、指方向;✂️ SAM 是“工兵”,精确地执行“抠图”任务;🧩 ComfyUI 则是“调度中心”,负责把两者串起来工作。
3,流程
1-第九节3-Segment Anything分割工作流
(1)调用模块
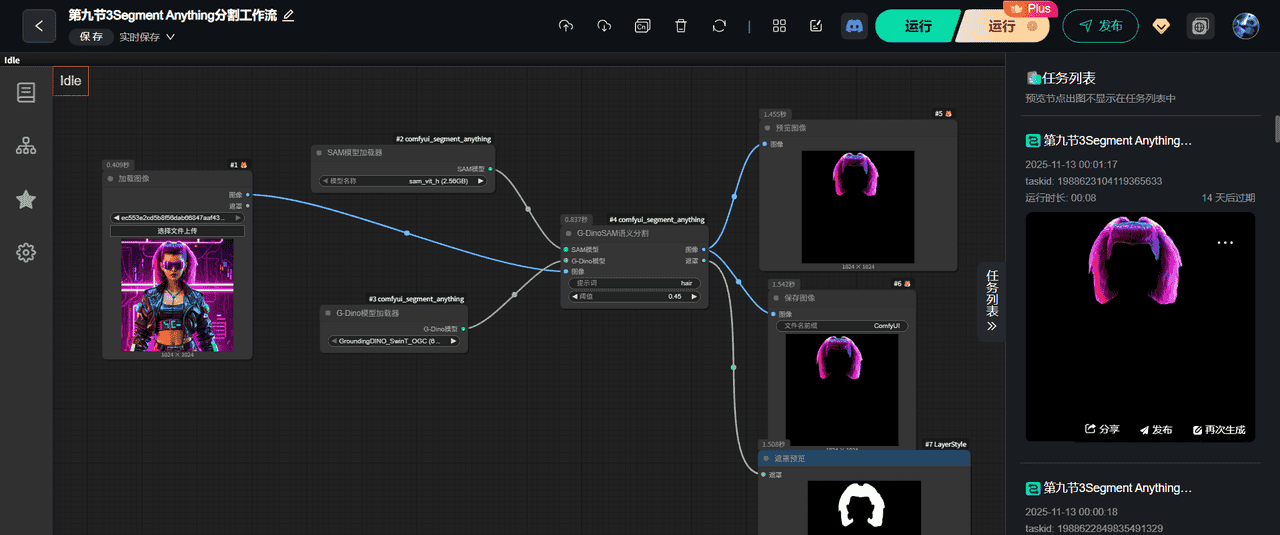
整个模块部分
这回整个模块都可以截截图下了
(2)输出 提示词
无
(3)模型加载
无
(4)生成图片
(1)原图片

(2)抠出的图

(5)模块介绍参数说明
| 阶段 | 输入 | 输出 | 解释 |
|---|---|---|---|
| 1️⃣ 加载图像 | 上传的原始人物图片 | 图像数据 | 给后面模型使用 |
| 2️⃣ 载入模型 | SAM + Grounding DINO | 模型权重对象 | 分割用的“大脑” |
| 3️⃣ 语义分割 | 图像 + 模型 + 提示词(“hair”) | 分割出的头发图像 | 自动抠出头发 |
| 4️⃣ 显示 + 保存 | 分割结果 | 黑背景头发图 + mask | 供后续编辑使用 |
🧩 一、总体思路
这套流程的作用是:
输入一张图像 → 使用 Grounding DINO 定位目标(如“hair”) → 由 SAM 模型精确分割出目标区域 → 输出并保存分割结果(含遮罩)。
这种组合在 ComfyUI 中非常常见,被称为 G-DINO + SAM 联合分割工作流,能够实现类似「输入文字 → 自动分割出对应物体」的语义分割效果。
🧱 二、节点解析
① 加载图像(左上)
节点名称:加载图像功能:输入原始图像(此处是一位穿霓虹夹克的女性角色)。输出:原图(RGB格式)传给后续节点。
输入输出:
输入:无(你上传的文件)输出:图像张量 → 传给 G-DINO 和 SAM
② SAM 模型加载器(#2 comfyui_segment_anything)
功能:加载 Segment Anything 模型(
sam_vit_h_0.9
③ G-DINO 模型加载器(#3 comfyui_segment_anything)
功能:加载 Grounding DINO 模型(
GroundingDINO_SwinT_OGC
④ G-DINO + SAM 组合分割(#4 comfyui_segment_anything)
功能:核心节点,执行“语义提示分割”。
参数说明:
提示词(Prompt):
hair
工作原理:
Grounding DINO 根据文本提示“hair”生成候选框;SAM 在这些候选框中进行像素级分割;输出结果即为带透明背景的头发区域。
输入输出:
输入:图像 + SAM模型 + G-DINO模型 + 提示词输出:遮罩图(mask)和分割图(segmented image)
⑤ 显示图像
功能:实时显示分割出的头发图像。结果:你在右上看到的彩色头发遮罩图(黑背景+保留头发)。
⑥ 保存图像
功能:将分割结果保存为文件,便于后续使用(如替换背景、上色等)。输出文件名:自动以“ComfyUI”命名保存。
⑦ LayerStyle(图层样式)
功能:生成纯遮罩图(白=目标区域,黑=背景),便于后续在 Photoshop 或 Fusion 中做图层操作。结果:右下显示的纯黑白 mask 图。
🎯 三、最终输出内容
| 输出文件 | 内容 | 用途 |
|---|---|---|
| 分割图(彩色) | 黑背景,仅保留头发区域 | 直接叠加或生成合成图 |
| 遮罩图(黑白) | 白=头发区域,黑=背景 | 供后期合成或 alpha 蒙版使用 |
4,细节部分
无
5,使用的工作流
https://download.csdn.net/download/qq_22146161/92297249
6,总结
这也算各一个开始吧,我也在学习摸索中。



![[C++探索之旅] 第一部分第十一课:小练习,猜单词 - 鹿快](https://img.lukuai.com/blogimg/20251015/da217e2245754101b3d2ef80869e9de2.jpg)













暂无评论内容