
目录
引言
数据集,训练的基石
数据集规模与训练策略
循环轮次与训练效果
图片质量对泛化能力的影响
算法与优化器
介绍
优化器的适用场景
参数调优
学习率
学习率数值表示与理解
学习率对训练效率的影响
学习率策略
U-Net学习率设置与影响
学习率预热策略
学习率周度器的应用
Network相关参数
Network Alpha
Network Rank
Alpha与Rank配合
精度选择策略
精度类型与适用场景
混合精度策略的优势
精度选择对训练效率的影响
最小信噪比伽马值
参数调整对模型性能的影响
作用与重要性
参数设置的实践建议
LOSS函数
模型收敛的定义与特征
模型发散的表现与原因
损失函数曲线的分析
模型效果检验
SD环境中测试生图质量
评估指标与方法
模型优化与改进
引言
其实这部分并不属于ComfyUI的部分,但是你也看到了Flux 下的LORA是非常重要的。你可能想训练一个自己的LORA,其实Lora的原理,在 https://blog.csdn.net/talentyiyy/article/details/154440949?spm=1011.2124.3001.6209 讲的比较清楚了,就是Matrix (M1*N1) * Matrix(N1*M2) 后,适当调小 N1, 可以降低 Matrix(M1M2)的训练量。从数学理解的角度,你要先把他拿下,我在这里就不在过多阐述了。今天主要讲下 训练自己的Lora 的核心概念和知识点。下一节开始实操。
数据集,训练的基石
巧妇难为无米之炊。数据集,作为训练的材料,肯定是最重要的。

数据集规模与训练策略
数据集规模直接影响模型的训练效果和训练时间。大规模数据集需要更长的训练时间和更高的算力支持,但通常能训练出性能更好的模型。例如,使用百万级数据集训练一个深度学习模型,可能需要数天甚至数周的时间,但模型的准确率和鲁棒性会更强,对于小数据集,除了增加循环轮次外,还可以采用数据增强等技术来扩充数据集,提高模型的泛化能力。数据增强通过旋转、裁剪、翻转等操作生成新的训练样本,使模型能够学习到更多的变化情况。
循环轮次与训练效果
在训练集较少的情况下,增加循环轮次(epoch)可以让模型有更多机会学习数据中的特征,从而提高模型的性能。例如,对于一个小型数据集,将循环轮次从10增加到50,模型的准确率可能会显著提升,因为模型有更多次的机会调整权重以更好地拟合数据。
但循环轮次并非越多越好,过高的轮次可能导致过拟合,即模型在训练数据上表现很好,但在新的数据上性能下降。因此,需要根据模型在验证集上的表现来调整循环轮次,找到最佳的平衡点。
图片质量对泛化能力的影响
高质量图片包含更丰富的细节和特征,能够使模型学习到更多元化的信息,从而提高模型对不同场景和风格的适应能力,增强泛化能力。例如,在训练一个图像分类模型时,使用高清且多样化的图片数据集,模型在面对新的、未见过的图片时,也能更准确地进行分类。图片种类的丰富性同样重要,不同种类的图片涵盖了各种场景、风格和对象,有助于模型学习到更广泛的特征分布,避免因数据单一导致的模型偏差,进一步提升模型的泛化性能。
算法与优化器
介绍
Adamw8bi优化器结合了动量优化和权重衰减等技术,能够有效加速模型收敛并提高训练稳定性。它通过自适应调整学习率,根据参数的梯度历史动态调整每个参数的学习率,使模型在训练初期能够快速收敛,同时在训练后期避免过拟合。
Lion优化器则在某些特定场景下表现出色,具有更好的优化性能和收敛速度。它通过引入动量项和自适应学习率调整机制,能够在复杂的优化问题中找到更优的解,尤其适合训练深度神经网络。
优化器的适用场景
Adamw8bi优化器适用于大多数深度学习任务,尤其是需要快速收敛和稳定训练的场景。它在图像分类、目标检测和自然语言处理等领域都有广泛的应用,能够有效提高模型的训练效率和性能。
Lion优化器则更适合于训练大规模的深度神经网络,尤其是在需要处理复杂数据和优化问题时。例如,在训练Transformer模型时,Lion优化器能够更好地处理模型中的高维度参数和复杂的优化问题,提高模明川练效果。
例如,在训练一个图像生成模型时,使用Adamw8bi优化器可能使模型在较短时间内达到较高的生成质量,而使用Lion优化器可能在更复杂的场景下表现更好。
优化器的选择还应根据具体的任务和模型结构进行调整。对于简单的线性模型,SGD(随机梯度下降)优化器可能已经足够:而对于复杂的深度学习模型Adamw8bi或Lion等优化器则更为适用。
参数调优
学习率
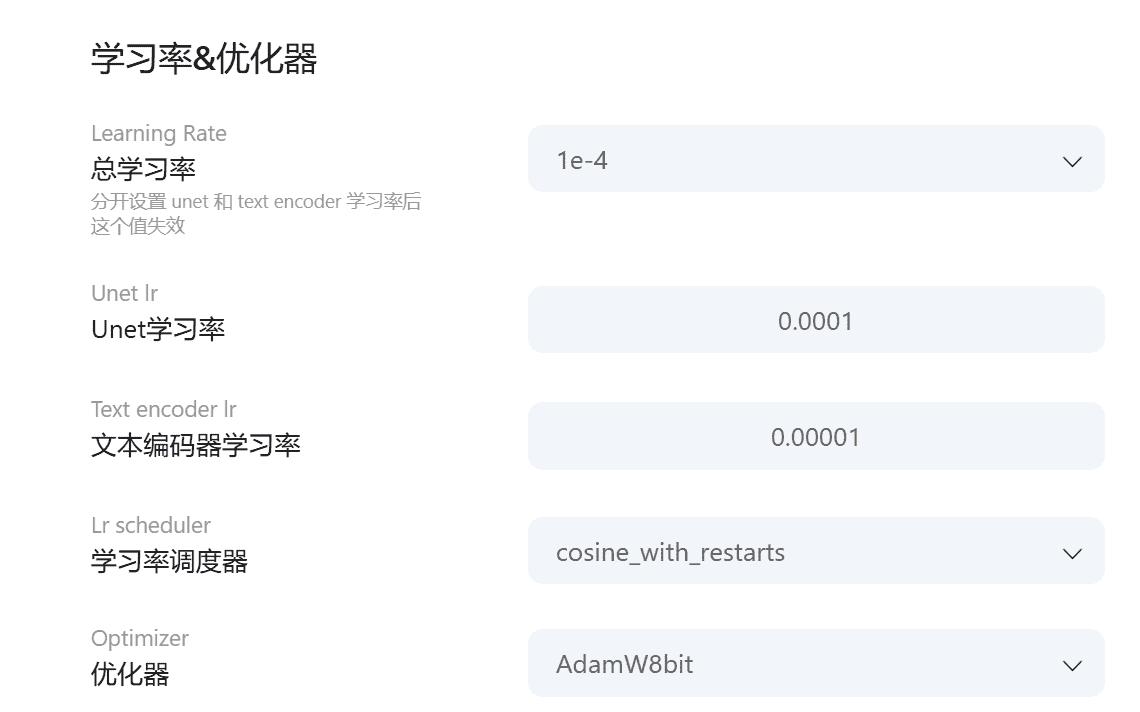
学习率是机器学习算法中的关键参数,用于控制模型在每次迭代更新时对于权重和位置的调整程度。学习率较大时,每一步更新的幅度会比较大,模型可能会更快地收敛得到最优解,但容易错过最优解附近的小波动,甚至发生震荡或无法收敛的情况。相反,如果学习率较小,每一步的变化会比较小,模型的调整过程会相对稳定,但可能需要更多的迭代次数才能收敛到最优解,训练速度可能会变慢。因此,合理设置学习率对于模型的训练效果至关重要。
学习率数值表示与理解
1e-4是一种程序里的数学表达,实际上就是1除以10的4次方,即1e-4=1110000=0.0001;1e-5=1100000=0.00001。这种科学计数法在设置学习率时常用,便于精确表示较小数值,方便调整模型训练过程中的权重更新幅度,以达到理想的训练效果。在实际应用中,学习率的设置需要根据具体的任务和模型结构进行调整。例如,在训练一个简单的线性回归模型时,学习率可以设置为0.01:而在训练一个复杂的深度学习模型时,学习率可能需要设置为1e-4或更小。
学习率对训练效率的影响
学习率的大小直接影响模型的训练效率。较大的学习率可以使模型在训练初期快速收敛,但可能导致模型在后期无法稳定收敛。甚至发散;较小的学习率可以使模型在训练过程中更加稳定,但会增加训练时间,降低训练效率。因此,在训练过程中,需要根据模型的表现动态调整学习率。例如,在训练初期可以使用较大的学习率,随着训练的进行逐渐降低学习率,以达到快速收敛和稳定训练的平衡。
学习率策略
U-Net学习率设置与影响
U-Net学习率(unetlr)控制U-Net部分权重的更新幅度,通常设置为1e-4。学习率过大无法稳致模型不收敛或发散,模型在训练过程中夫控。定地学习数据特征,参数更新方向和幅度优,学习率过小则收敛速度慢,可能陷入局部最优,无法有效优化模型性能。因此,在设置U-Net进习率时,需要根据具体的训练任务和模型行调整,以达到最佳训练效果。这个都是比较偏理论的知识,但是你需要知道。实际例子我们往后再看。
学习率预热策略
学习率预热是一种优化策略,通过在初始训练阶段逐步提高学习率,帮助模型稳定收敛并提升最终性能。小数据集(<10k样本)建议缩短预热步数(如总步数的5%),大数据集(如百万级)可长至总步数的10%-20%。
例如,在训练一个大规模的图像分割模型时,采用学习率预热策略可以使模型在训练初期避免因学习率过高而导致的不稳定,随着训练的进行逐新提高学习率,使模模型能够更好地学习数据特征,提高最终性能。
学习率周度器的应用
学习率调度器是动态调整学习率的工具,其作用范围覆盖整个训练期。通过学习率调度器,可以根据训练进度和朴型表现灵活调整学习率,以实现更好的认练效果和模型性能例如,在训练过程,可以设置学习率调度器在习率,中间阶段保持稳定训练初期快速提高,后期逐步降低学习率,使模型在不同阶段都能获得最佳的训练效果。
Network相关参数
Network Alpha
Network Alpha参数用来控制训练的LORA模型在使用时的“减弱权重”,该“减弱权重”通过Alpha和Rank的比值确定。Alpha一般不超过Rank,Alpha越接近Rank,LoRA模型权重影响越小,反之LORA对原模型的影响越大。例如,在训练一个图像生成模型时,如果希望LORA模型对原模型的影响较小,可以将Alpha设置为接近Rank的值;如果希望LORA模型对原模型有较大的影响,可以将Alpha设置为较小的值。
Network Rank
Rank数值表示从原始矩阵中抽取出的行列,抽取的就越多,微调的量就越多,从而控制LORA模型是否能容纳更复杂的概念。同时,较大的Rank值也会影响训练时占用显存的大小,如果电脑显存较低,在训练时需要留意此参数。
例如,在训练二次元风格的模型时,可以将Rank设置为32或16:而在训练复杂画风、三次元物品或形象时,Rank可以设置为128或64以容纳更复杂的概念。
Alpha与Rank配合
Alpha和Rank的配合对于模型的训练效果至关重要。合理的Alpha和Rank设置可以使LORA模型在保持原模型性能的基础上,有效地进行微调,提升模型的性能和适应性。
例如,在训练一个图像分类模型时,通过调整Alpha和Rank的值,可以使模型在训练过程中更好地平衡原模型的性能和微调的效果,提高模型的准确率和泛化能力。
记住一句话:Rank 是从原Matrix中取多少让 Lora 进行学习捕获。
Alpha 是Lora 对取出来这部分Matrix的影响到底有多大。
从这个表述中,你也应该看得出 为什么 LORA很小并且不能独立运行。因为他离不开原始的大模型 无论是SD1.5 还是 SDXL ,又或是 Flux。
所以其实你在Flux中使用LORA时,有一个参数叫强度。你不要认为他的最大值是1,其实可以更大。本质上他就是 alpha / rank。如果你想你的LORA起到很大作用时,不妨调大他的参数为1.5或是1.8,看看出图效果的变化。
精度选择策略
精度类型与适用场景
在精度选择方面,小模型或资源受限场景优先选择FP16,其显存节省显著且精度足够。大模型(参数量210B)则必须使用BF16,避免梯度爆炸或消失。这里引出了一个新概念,梯度爆炸或是消失。说直白点就是你一直在一个沟里来回震荡,始终找不到最优解。你可以简单这么理解。
FP16需搭配动态损失缩放(dynamiclossscaling)和梯度裁剪;BF16可直接与FP32权重混合使用,无需额外调整。例如,在训练一个小型的图像生成模型时,可以使用FP16精度,以节省显存并提高训练速度;而在训练一个大规模的自然语言处理模型时,则需要使用BF16精度,以避免梯度问题。
混合精度策略的优势
混合精度策略结合了不同精度类型的优势,可以在训练过程中根据需要动态调整精度,提高训练效率和模型性能。例如,在训练一个深度学习模型时,可以使用FP16进行前向传播和反向传播,以节省显存和加速训练。同时使用BF16进行权重更新以保持模型的精度和稳定性。也就是说保存的是高精度的,训练的时候用稍微低一点精度的。
精度选择对训练效率的影响
精度选择对训练效率有显著影响。较低的精度(如FP16)可以显著节省显存,加快训练速度,但可能会导致精度损失;较高的精度(如BF16)可以提高模型的精度和稳定性,但会增加显存占用和训练时间。因此,在选择精度时,需要根据具体的任务和模型结构进行权衡,以达到最佳的训练效率和模型性能。
你比如说,Flux 在 FP16 下,达到了22G,而在FP8下,只有11G。通过模型大小,你也能直观感受出来精度对model影响是很大的。当然如果你的显存与处理器能力足够,又比如你在云端使用,FP16的一定比FP8效果好,这是肯定的,当然好也可能好不了太多,但如果你还是和我一样,有细节决定成败的思维,那可能回选FP16,但是也请量力而行。云端同样的参数设置,你选择FP16 还是FP8,肯定消耗的算力也是不一样的。
最小信噪比伽马值
这玩意儿有点抽象,我平时也用的不多,基本训练用的是默认值。
参数调整对模型性能的影响
最小信噪比伽马值的调整对模型的性能有直接影响。如果该值设置过低,可能会导致模型生成的内容质量下降,出现噪声过多或细节丢失等问题;如果该值设置过高,可能会导致训练过程不稳定,出现梯度爆炸或消失等问题,因此,在训练过程中,需要根据模型的表现动态调整最小信噪比伽马值,以达到最佳的训练效果和模型性能。
作用与重要性
最小信噪比伽马值在模型训练中起着重要作用,其主要作用是平衡生成质量与训练稳定性。通过合理设置该参数,可以在保证模型生成内容质量的同时,确保训练过程的稳定进行,避免出现训练崩溃或生成质量下降等问题。
例如,在训练一个图像生成模型时,通过调整最小信噪比伽马值,可以使模型在生成高质量图像的同时,保持训练过程的稳定,避免因训练不稳定导致的图像质量下降或训练崩溃。
参数设置的实践建议
在实际应用中,最小信噪比伽马值的设置需要根据具体的任务和模型结构进行调整。
例如,在训练一个简单的图像生成模型时,可以将该值设置为一个较小的值。
而在训练一个复杂的深度学习模型时,可能需要将该值设置为一个较大的值同时,可以通过实验和验证来确定最佳的参数值,以确保模型在训练过程中能够达到最佳的性能和稳定性。
LOSS函数
搞AI训练的人,都离不开这个,就是评价一个训练值与目标值差异的部分,我们称之为loss。
模型收敛的定义与特征
模型收敛是指训练过程中模型的损失函数值逐渐稳定,参数更新幅度减小,最终达到一种稳定状态。此时模型能够准确预测新数据,且训练损失和验证损失的变化趋于平缓。例如,在训练一个图像分类模型时,随着训练的进行,损失函数值逐渐下降并趋于稳定,模型的准确率逐渐提高,这表明模型已经收敛,能够很好地预测新的图像数据。
模型发散的表现与原因
模型发散是训练失败的表现,特征为损失函数曲线呈上升趋势或剧烈波动。这可能是由于学习率过大、数据质量问题或模型结构不合理等原因导致的。
例如,如果学习率设置过大,模型在训练过程中可能会出现参数更新步幅过大,导致损失函数值上升或剧烈波动,无法稳定收敛。
损失函数曲线的分析
损失函数曲线是判断模型收敛和发散的重要依据。模型收敛时,损失的数曲线会先动态下降,随着训练的深入逐渐趋于平缓:而模型发散时,损失函数曲线会持续上升或剧烈震荡,甚至完全失效出现NaN值。通过分析损失函数曲线,可以及时发现模型训练过程中存在的问题,并采取相应的措施进行调整,以确保模型的稳定训练和良好性能。
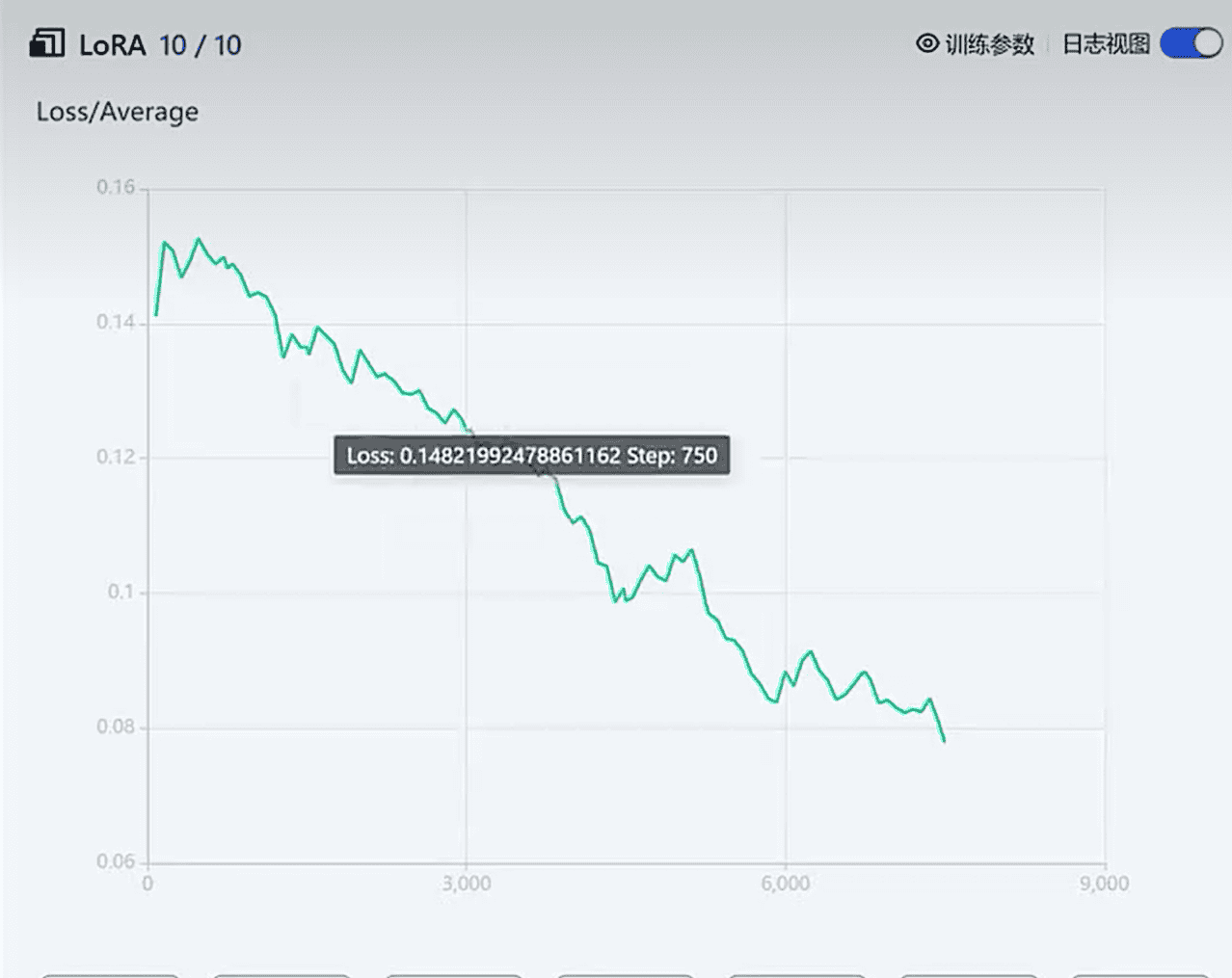
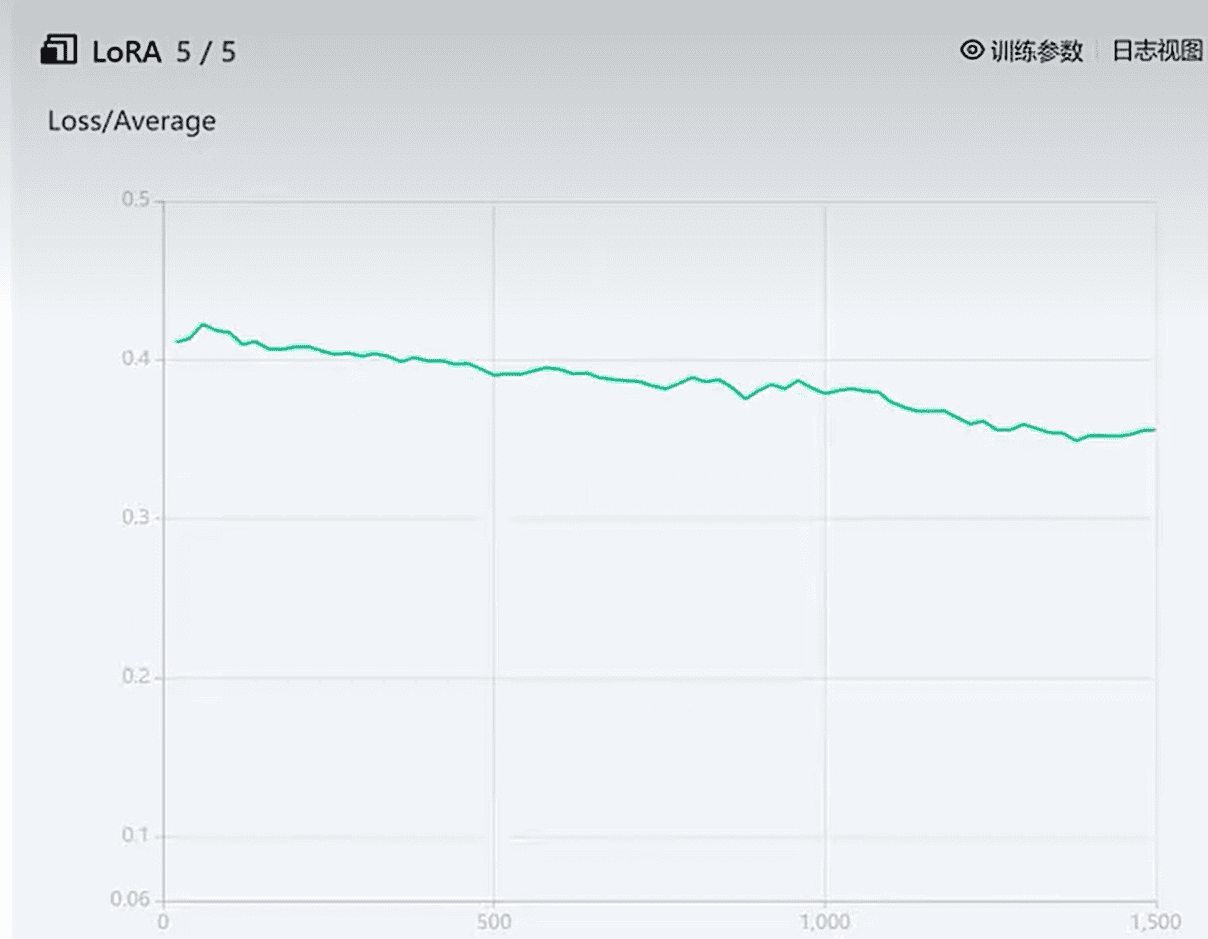
左边的训练并非一帆风顺,总会有点‘波澜’,这种波澜称为发散。右边这个虽然更为平稳,但是它对吗?答案是肯定的,他不对,因为他的loss虽然较为恒定,但是太差了,始终在0.4 上下。这就像一个成绩差的学生,成绩很稳定,每次100分的满分总是考 61,62。当然,在数学上基本用方差活协方差来恒定稳定,用平均值来衡量整体好坏。对于右边的情况,也要引起足够重视,如果始终平稳,但是达不到你想要的平均水平,你可能需要结合前面的参数,学习率,算法,以及网络参数,loss函数进行适当调整。因为在这些都确定的情况下,目前你只能在 0.4 左右徘徊(其实平均水平不太好,LORA尽管稳定,但质量一般)。
模型效果检验
SD环境中测试生图质量
根据训练出的LORA模型,在SD环境中测试生成图像的质量,是评估模型性能的重要环节。通过在实际应用场景中测试模型的生成效果,可以直观地了解模型的性能和适用性。例如,在训练一个图像生成模型后,可以在SD环境中生成一系列图像,并对生成图像的质量进行评估,包括图像自清晰度、细节表现、风格一致性等方面以确定模型是否达到了预期的性能要求。
评估指标与方法
指在评估模型性能时,可以使用多种评信标和方法。常见的评估指标包括准确率救 增召回率、F1分数等,用于评估模型的性能;生成图像质量的评估指标包括峰信噪比(PSNR)、结构相似性指数(SSIM)等,用于评估生成图像的质量评估方法可以包括定性评估和定量评估。通过观察生成图像的视觉效果评估模型的性能;定量评估则通过计算估指标的数值来客观地评估模型的性能。
模型优化与改进
根据评估结果,可以对模型进行优化和改进。如果模型的性能未达到预期要求,可以通过调整模型结构、优化算法、学习率等参数来提高模型的性能。
例如,如果生成图像的质量较差可以尝试调整LORA模型的参数,如NetworkAlpha和Rank,或者调整训练过程中的学习率和循环轮次等参数,以优化模型的性能。


![在苹果iPhone手机上编写ios越狱插件deb[超简单] - 鹿快](https://img.lukuai.com/blogimg/20251123/23f740f048644a198a64e73eeaa43e60.jpg)
















暂无评论内容