
你的硬盘(SSD / NVMe / HDD)在默默工作,但偶尔会在关键时刻“罢工”。
本文教你一套简单可落地的盘健康监控方法:安装必备工具 → 手动检查 → 写脚本自动巡检并报警(Linux 与 Windows 两套),步骤清晰,能马上用。
一、为什么要做盘况监测(简短)
- 提前发现坏道、重分配扇区、寿命耗尽等风险
- 自动告警避免数据损失(尤其是备份/数据库服务器)
- 性能退化、异常温度也能及时响应
只要设置好巡检并在发现异常时报警,就能把风险降到最低。
二、先决条件与工具清单
- Linux:smartmontools(smartctl)、nvme-cli(NVMe 专用)
- Windows:CrystalDiskInfo(GUI,适合快速查看),或在命令行使用 smartctl(smartmontools 的 Windows 版)/PowerShell 查看基础健康信息
- 报警方式(任选):邮件(sendmail/msmtp)、Webhook(企业微信/Slack)、简单 SMS/钉钉机器人
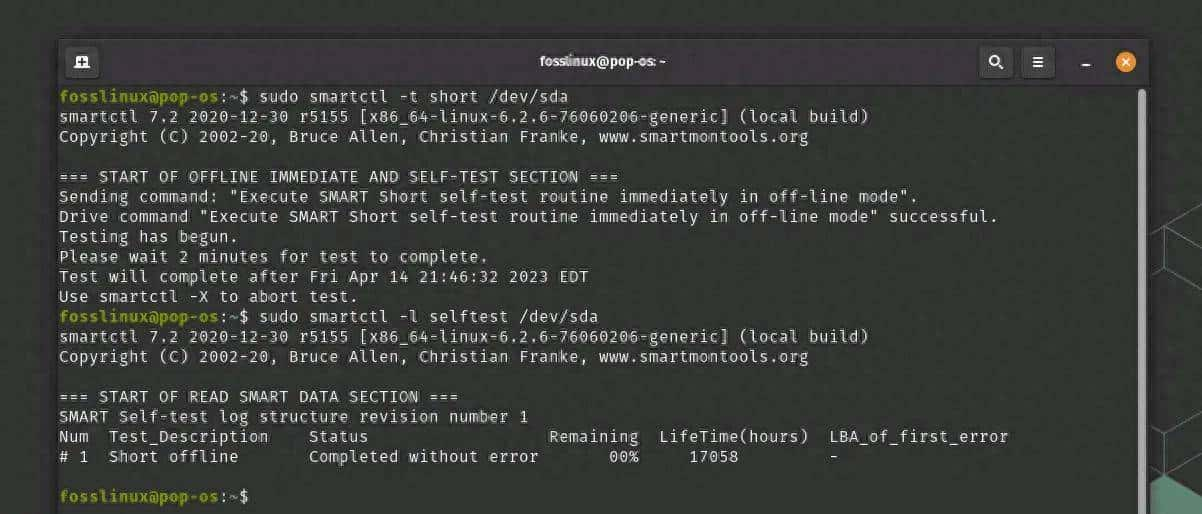
三、Linux:安装与手动检查(一步到位)
1)安装(Debian/Ubuntu / CentOS)
# Debian / Ubuntu
sudo apt update
sudo apt install smartmontools nvme-cli -y
# CentOS / RHEL
sudo yum install smartmontools -y
# nvme-cli 可从 EPEL 安装:sudo yum install epel-release && sudo yum install nvme-cli
2)识别设备
lsblk -o NAME,MODEL,SIZE,TYPE
# 或
sudo fdisk -l
假设设备为 /dev/sda(SATA SSD/HDD)或 /dev/nvme0n1(NVMe)。
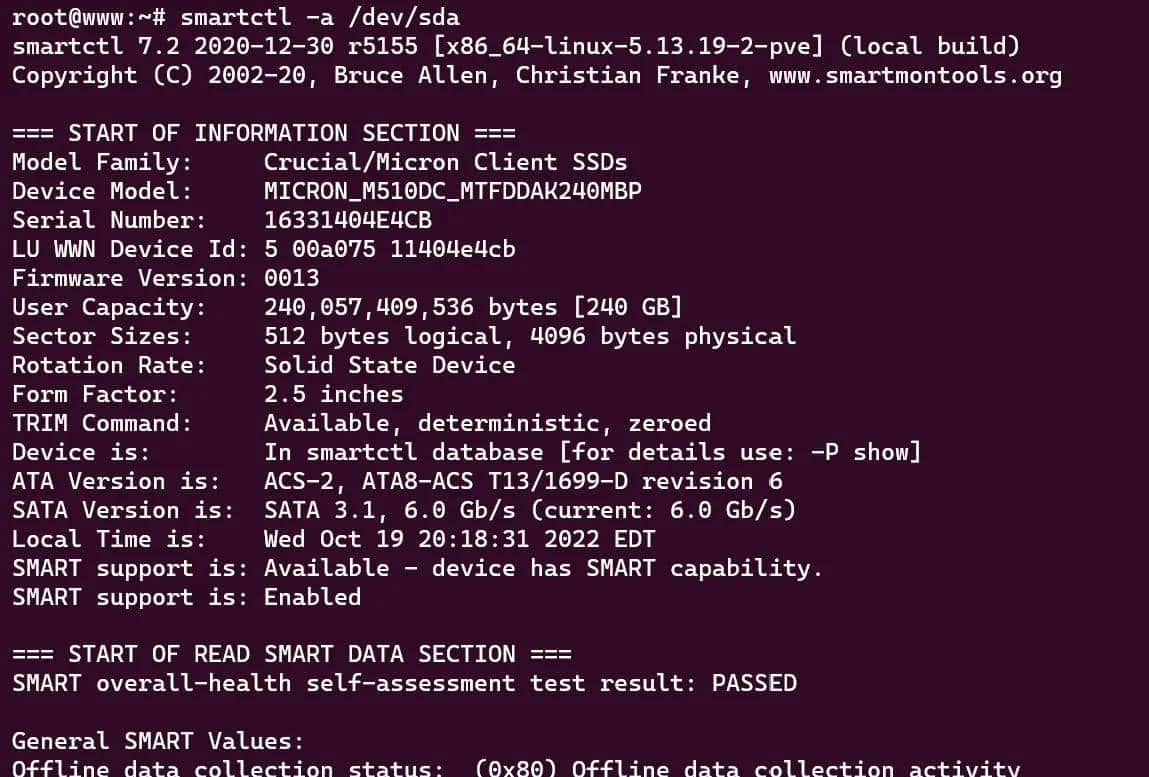
3)SATA / NVMe 基本健康查询
# SATA / NVMe 都能用 smartctl(NVMe 需加 -d nvme)
# 对 SATA:
sudo smartctl -a /dev/sda
# 对 NVMe:
sudo smartctl -a -d nvme /dev/nvme0n1
# nvme-cli 的 nvme-smart-info(更直观 NVMe)
sudo nvme smart-log /dev/nvme0
4)关注的关键 SMART 指标(解读要点)
- Reallocated_Sector_Ct(重分配扇区数)>0 要警惕,持续增长代表坏道
- Current_Pending_Sector(待映射扇区)>0 很危险,需立即备份
- Power_On_Hours(通电时长)+ Power_Cycle_Count(开关次数)了解寿命
- NVMe 特有:Percentage Used(寿命使用百分比),Data Units Written(写入总量),温度(℃)
示例:看到 Percentage Used: 98% → SSD 快到寿命上限,应计划更换并立即备份。
四、Linux:一键巡检脚本 + 报警(示例)
下面脚本 check_disk.sh 会检查指定设备的关键项,异常时通过 mail 发送邮件(也可改为 webhook)。
#!/bin/bash
# /usr/local/bin/check_disk.sh
# 用法: sudo check_disk.sh /dev/nvme0n1
DEV=$1
ALERT_EMAIL=”you@example.com”
if [ -z “$DEV” ]; then
echo “Usage: $0 /dev/sdX or /dev/nvme0n1”
exit 1
fi
# 获取 smartctl 输出(自动识别 NVMe)
SMART_OUT=$(sudo smartctl -a -d nvme “$DEV” 2>/dev/null || sudo smartctl -a “$DEV” 2>/dev/null)
# 检查重分配扇区
REALLOC=$(echo “$SMART_OUT” | grep -i “Reallocated_Sector_Ct” | awk '{print $NF}')
PENDING=$(echo “$SMART_OUT” | grep -i -E “Current_Pending_Sector|Pending_Sector” | awk '{print $NF}')
# NVMe 识别 Percentage Used
PERC_USED=$(echo “$SMART_OUT” | grep -i “Percentage Used” | awk -F: '{print $2}' | tr -d ' %')
# 温度
TEMP=$(echo “$SMART_OUT” | grep -i “Temperature” | head -n1 | awk '{print $NF}' | tr -d 'C')
ALERT_MSG=””
if [ -n “$REALLOC” ] && [ “$REALLOC” -gt 0 ]; then
ALERT_MSG=”$ALERT_MSG
Reallocated sectors: $REALLOC”
fi
if [ -n “$PENDING” ] && [ “$PENDING” -gt 0 ]; then
ALERT_MSG=”$ALERT_MSG
Pending sectors: $PENDING”
fi
if [ -n “$PERC_USED” ] && [ “$PERC_USED” -gt 80 ]; then
ALERT_MSG=”$ALERT_MSG
SSD Percent Used: $PERC_USED%”
fi
if [ -n “$TEMP” ] && [ “$TEMP” -gt 60 ]; then
ALERT_MSG=”$ALERT_MSG
Temperature high: ${TEMP}C”
fi
if [ -n “$ALERT_MSG” ]; then
SUBJECT=”Disk alert for $DEV on $(hostname)”
BODY=”Disk check report for $DEV on $(hostname):
$ALERT_MSG
Full smartctl output:
$SMART_OUT”
echo -e “$BODY” | mail -s “$SUBJECT” “$ALERT_EMAIL”
fi
配置说明:
- 需要系统能发邮件(mail 命令)。可安装 mailutils 或改为 curl 调用 webhook。
- 把脚本放 /usr/local/bin/check_disk.sh,赋可执行 chmod +x。
5)用 systemd timer 自动运行(每日一次)
创建服务单元
/etc/systemd/system/check-disk.service:
[Unit]
Description=Disk health check
[Service]
Type=oneshot
ExecStart=/usr/local/bin/check_disk.sh /dev/nvme0n1
创建 timer
/etc/systemd/system/check-disk.timer:
[Unit]
Description=Run disk health check daily
[Timer]
OnCalendar=daily
Persistent=true
[Install]
WantedBy=timers.target
启用并启动:
sudo systemctl daemon-reload
sudo systemctl enable –now check-disk.timer
五、Windows:查看与自动化(GUI + 脚本)
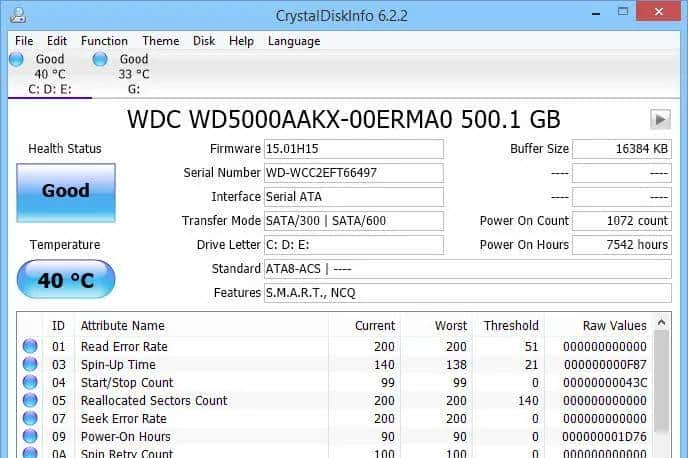
1)快速 GUI:CrystalDiskInfo
- 下载并运行 CrystalDiskInfo(免费,界面友善)可实时看到 SMART 状态与温度、健康度(Good/Warning/Bad)。适合桌面用户。
2)命令行:smartctl(Windows 版)
- 下载 smartmontools 的 Windows 包,放到 C:Program Filessmartmontools,使用命令:
# 以管理员 PowerShell 运行
& 'C:Program Filessmartmontoolsinsmartctl.exe' -a /dev/sda
# NVMe:
& 'C:Program Filessmartmontoolsinsmartctl.exe' -a -d nvme /dev/nvme0n1
注意:Windows 设备名称可能为 //./PhysicalDrive0 等,smartctl 文档有说明。
3)PowerShell 监控脚本(示例)
下面示例用 PowerShell 调用 smartctl 并在发现问题时通过邮件(SMTP)发出告警:
# save as C:ScriptsCheck-Disk.ps1
$dev = “//./PhysicalDrive0”
$smartPath = “C:Program Filessmartmontoolsinsmartctl.exe”
$out = & $smartPath -a $dev
# 检查关键字
if ($out -match “Reallocated_Sector_Ct.*s([0-9]+)$”) {
$realloc = [int]$Matches[1]
if ($realloc -gt 0) {
$smtpServer = “smtp.example.com”
$msg = New-Object System.Net.Mail.MailMessage
$msg.From = “monitor@example.com”
$msg.To.Add(“you@example.com”)
$msg.Subject = “Disk alert on $env:COMPUTERNAME”
$msg.Body = “Reallocated sectors: $realloc`n`nFull output:`n$out”
$smtp = New-Object Net.Mail.SmtpClient($smtpServer,25)
$smtp.Send($msg)
}
}
4)把脚本做成计划任务(Task Scheduler)
- 在任务计划程序中新建任务:触发器 → 每日/每小时,操作 → 运行 PowerShell 并指定脚本路径,勾选“以最高权限运行”。
六、报警方式替代(更现代的做法)
- Webhook:把脚本里发送邮件部分改为 curl 请求企业微信或 Slack webhook,收到即时消息。
- Prometheus + node_exporter + alertmanager:大型环境推荐把 SMART 指标收集到监控系统,再配置阈值告警(进阶)。
- 日志滚动:把检测结果写入日志文件并用 fail2ban / logwatch 做二次处理。
七、日常运营提议(实用清单)
- 定期备份:任何报警都先做立即备份(镜像或数据同步)。
- 监测阈值:为每台盘设置合理阈值(不同厂商 SMART 名称可能不同)。
- 温度管理:若温度常年偏高(>60℃),请清理散热或更换散热方案。
- 写入量监控:对 SSD 关注写入总量与 Percentage Used,高写入环境需评估更耐写企业级 SSD。
- 做好更换计划:当 SMART 报警出现,计划在可控时间内更换并恢复数据。
八、常见问题 FAQ(速查)
Q:SMART 报警后还能继续用吗?
A:短期可用,但必须立即备份并尽快更换。
Q:SMART 值为 0 就必定安全?
A:不绝对,SMART 是补充手段,仍需关注写入量、温度与性能异常。
Q:能否把脚本改为微信告警?
A:可以,把发送部分替换为推送到企业微信机器人或 ServerChan 类服务的 HTTP 请求。
九、示例资源(可复制粘贴)
- Linux 检查一次所有磁盘并输出简短报告:
for d in /dev/nvme*n1 /dev/sd?; do
[ -b “$d” ] || continue
echo “=== $d ===”
sudo smartctl -H -a -d nvme “$d” 2>/dev/null || sudo smartctl -H -a “$d”
done
十、结语(行动提议)
- 目前就运行一次 smartctl / nvme smart-log,读一遍关键指标;
- 把上面的 check_disk.sh 放到服务器并用 systemd timer 每日检查;
- 一旦脚本发现异常,立刻备份并计划更换硬盘。


![在苹果iPhone手机上编写ios越狱插件deb[超简单] - 鹿快](https://img.lukuai.com/blogimg/20251123/23f740f048644a198a64e73eeaa43e60.jpg)
















暂无评论内容