
在这篇文章中,我们将展示如何直接在 DuckDB 中使用 SQL 来完成机器学习数据预处理中的关键任务,例如缺失值填补、类别编码以及特征缩放。这样的方式不仅简化了工作流程,还能充分利用 DuckDB 高性能的进程内执行引擎,实现快速高效的数据准备。

引言
数据预处理是任何机器学习流程中必不可少的一步,它既影响模型的有效性,也关系到后续维护的便利性。虽然 scikit-learn 因与更广泛的 Python 生态系统集成而被广泛应用于预处理,但 DuckDB 提供了一种切实可行的替代方案——允许在 Python 中通过 SQL 来进行数据转换。DuckDB 的声明式语法支持模块化工作流,使预处理步骤更容易拆解、检查和调试。此外,DuckDB 对列式数据格式的高效查询支持,以及将预处理逻辑持久化为 SQL 脚本的能力,都有助于构建更具可复现性和透明度的处理流程。
数据准备
我们将使用一个来自 Kaggle 的合成金融交易数据集,其中包含一些通用的金融交易信息,主要用于金融欺诈检测。
我们第一通过执行 SUMMARIZE 来分析数据。
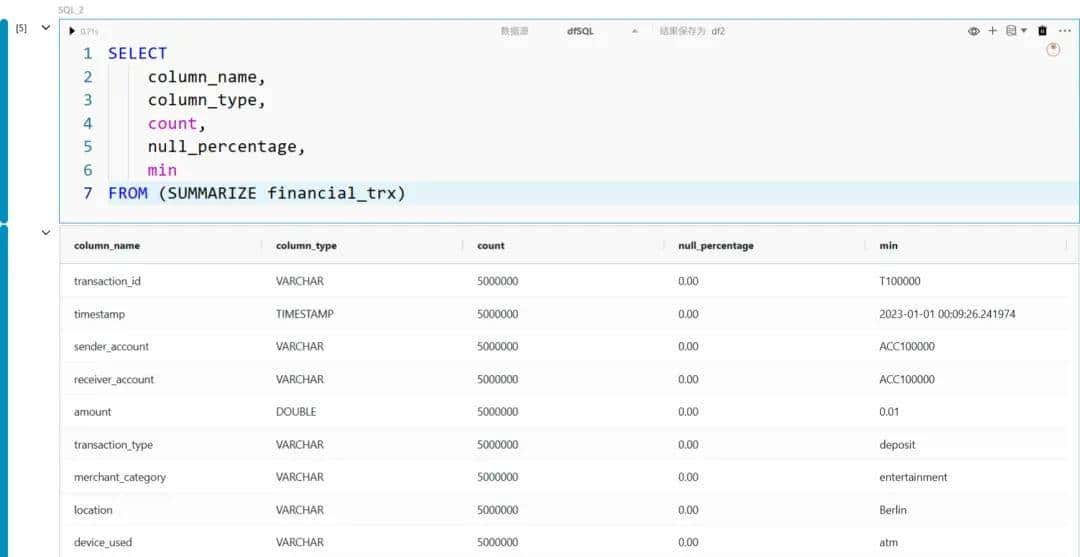
特征编码
从上面的数据统计中可以看到,数据聚焦包含一些类别型字段,例如 transaction_type、merchant_category 和 payment_channel。由于大多数机器学习模型都需要数值型输入,这类数据需要被转换为数值表明。这个过程称为编码,可以通过多种方式实现。下面我们将展示几种常见的 SQL 编码方法。
在本文中,我们会使用 DuckDB 的一些“友善 SQL”特性,包括 FROM 优先语法和前缀别名。
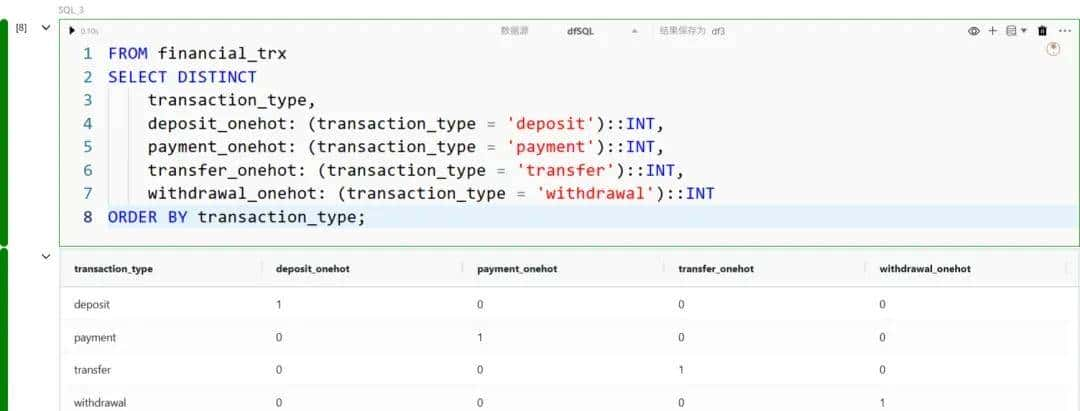
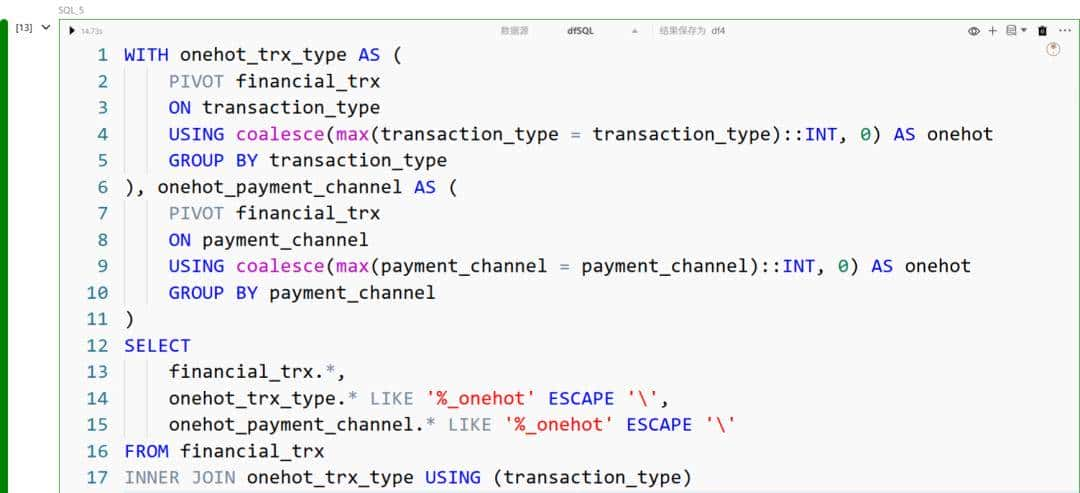
独热编码(One-Hot Encoding)
当对某个类别字段应用独热编码时,每个不同的取值都会被转化为单独的一列;若该行匹配该取值,则该列取值为 1,否则为 0。
另一种实现独热编码的方法是使用 PIVOT 语句:
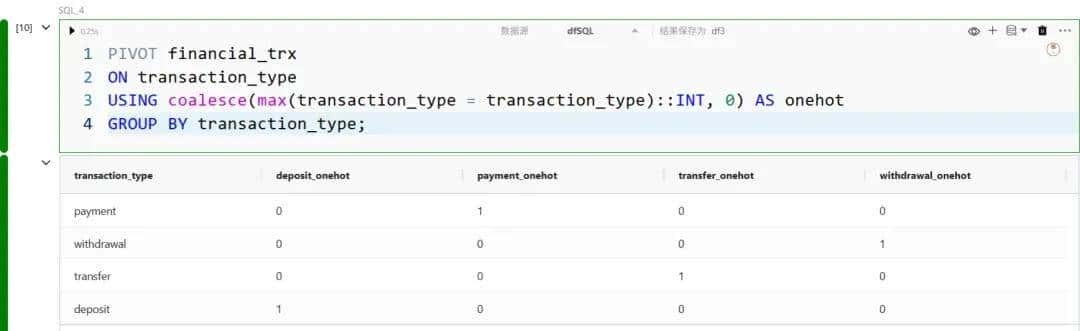
在上述语句中,我们完成了以下操作:
- 以类别字段 transaction_type 作为透视的依据;
- 透视条件是 transaction_type 是否与其各个取值相匹配;
- 将布尔值转换为整数,并在匹配结果上应用 max;
- 将转置后的列命名为对应的 transaction_type 值并加上后缀 _onehot。
如果有更多的类别字段需要进行独热编码,可以在 子查询 或 WITH 子句 中使用 PIVOT。
序数编码(Ordinal Encoding)
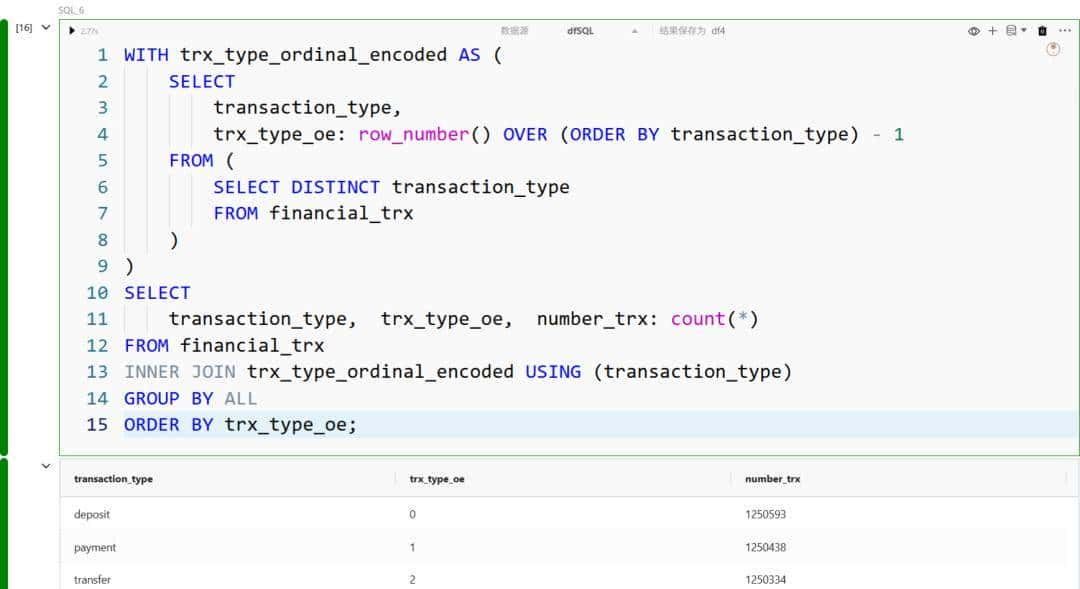
序数编码为每个类别取值分配一个唯一的标识符,一般在类别值之间存在某种顺序或层级关系时使用。
例如,我们可以通过 row_number 函数并按 transaction_type 排序来分配标识符:
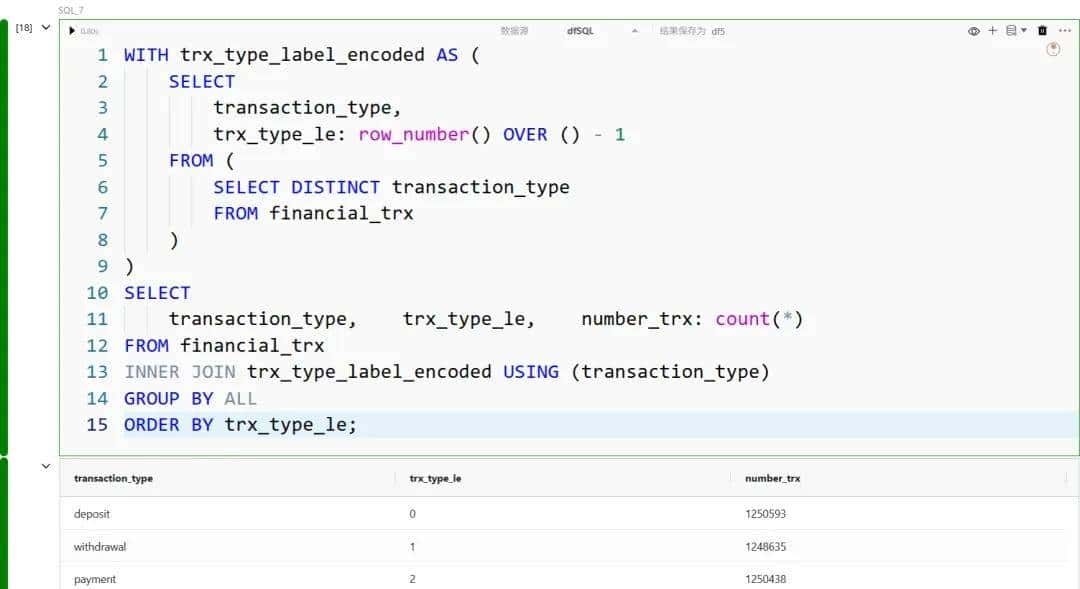
标签编码(Label Encoding)
与序数编码类似,标签编码也为每个类别值分配一个唯一的标识符,但它不思考顺序。这种方法一般用于输出数据。
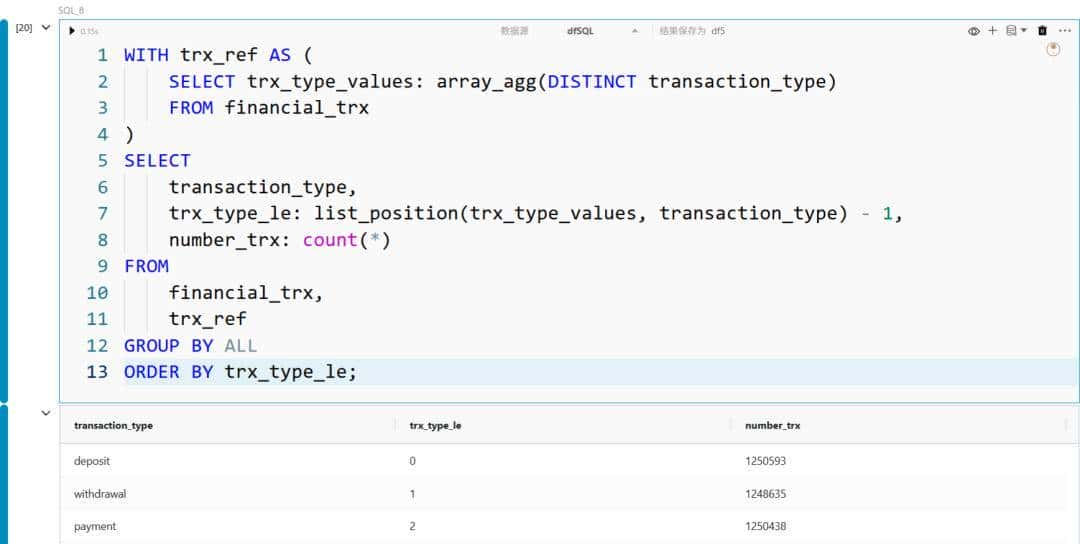
另一种实现上述方法的方式是使用 列表函数,例如通过 array_agg 创建包含所有不同取值的数组,再利用 list_position 提取每个取值在数组中的位置:
特征缩放(Feature Scaling)
机器学习中另一个常见的数据预处理步骤是对数值型特征进行缩放,使得不同特征的数值处于类似的范围或分布。缩放,也称为特征归一化或标准化,通过对特征进行变换,使它们具有可比的量级;一般方法包括将数值重新缩放到固定范围(如 0 到 1)或调整为零均值、单位方差。这个过程是必要的,由于许多算法依赖于距离计算或梯度更新,如果特征尺度差异过大,会导致结果偏差。
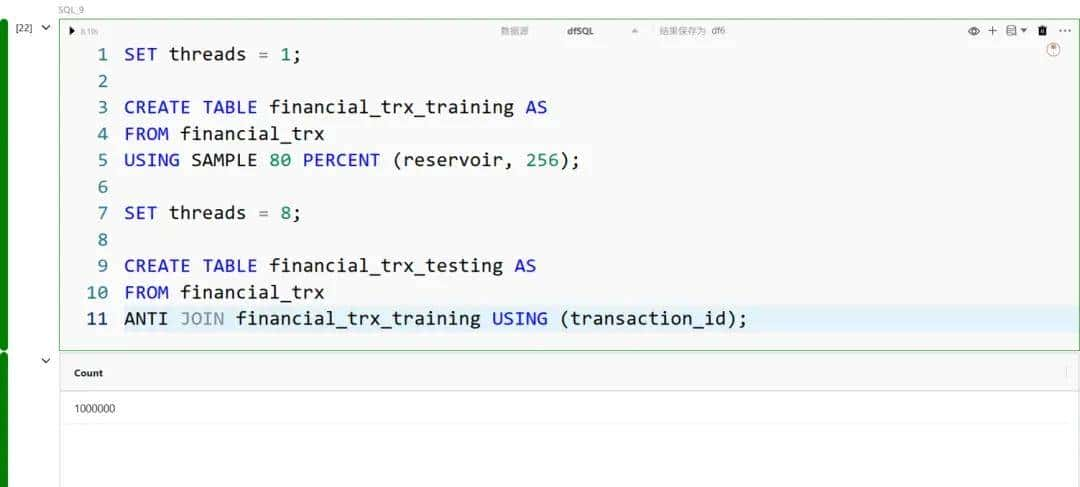
如果编码是在初始原始数据上进行的(需要知道整个类别取值列表),则缩放需要先将数据划分为训练集和测试集,以避免数据泄漏。在 DuckDB 中,我们可以通过采样的方式来划分数据:
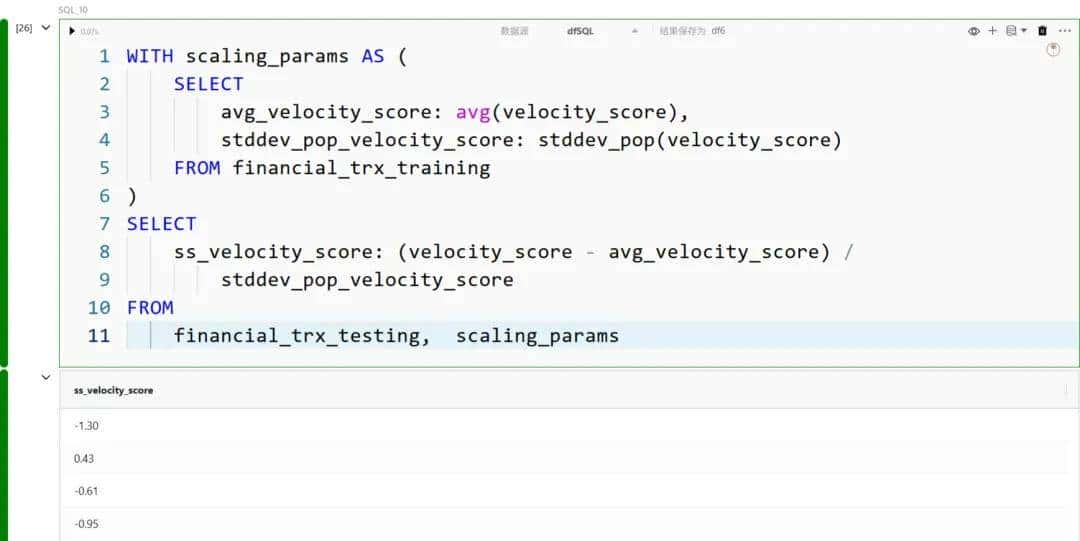
标准缩放(Standard Scaling)
标准缩放是一种预处理技术,通过对数值型特征减去均值再除以标准差,将每个特征转换为均值为 0、标准差为 1 的分布。
例如,要对 velocity_score 进行标准缩放,我们可以执行:
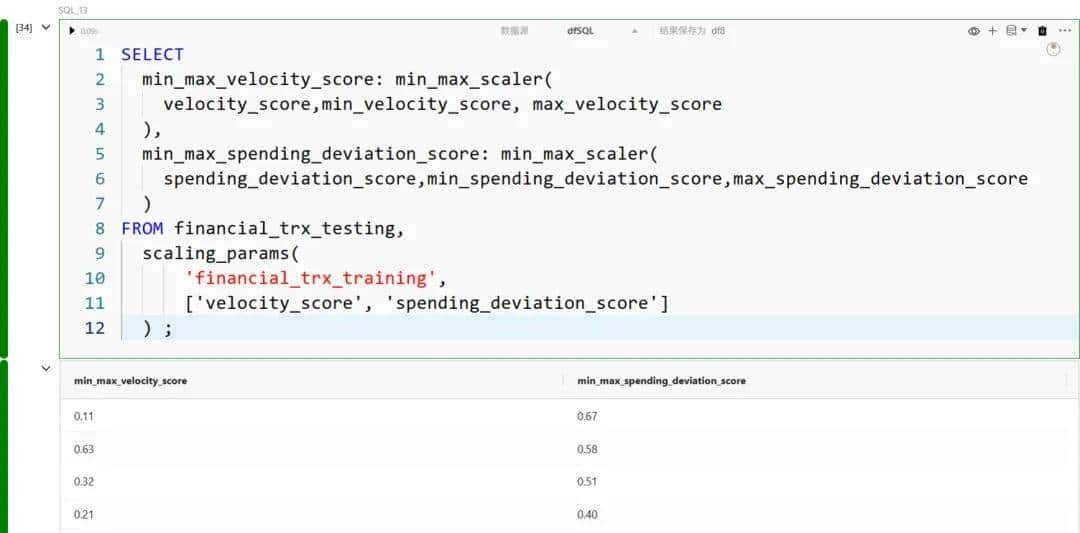
最小-最大缩放(Min-Max Scaling)
最小-最大缩放是一种归一化技术,通过减去最小值并除以范围(最大值 − 最小值),将特征转换到固定范围,一般是 0 到 1。这样既保留了原始分布的形状,又确保所有特征在一样的尺度上。
为了对特征进行最小-最大缩放,我们可以在 scaling_params 宏中扩展,对输入列列表计算最小值和最大值:
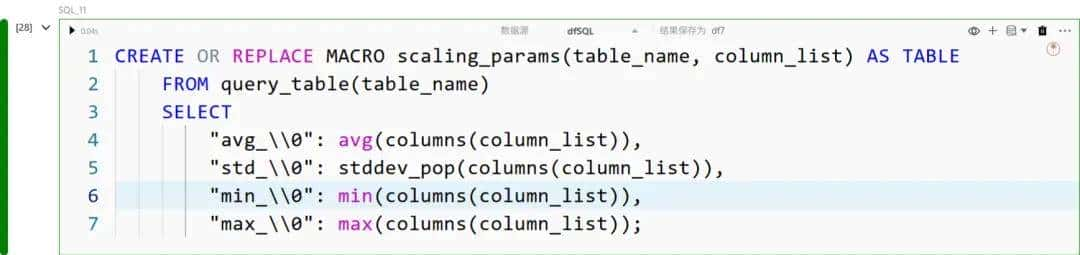
然后我们为最小-最大计算定义一个宏定义:

最后,我们提取值:
稳健/鲁棒缩放(Robust Scaling)
稳健缩放是一种数据归一化技术,通过减去中位数并除以四分位距(IQR)来转换数值型特征。与使用均值和标准差的标准缩放不同,稳健缩放通过关注数据的中间 50% 来降低异常值的影响,因此超级适合分布偏斜或存在极端值的数据集。
在 DuckDB 中,我们可以使用 quantile_cont 统计聚合函数来计算分位数范围:
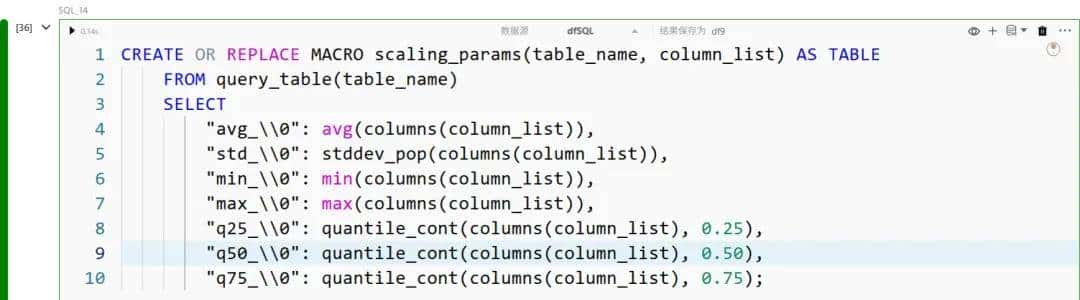
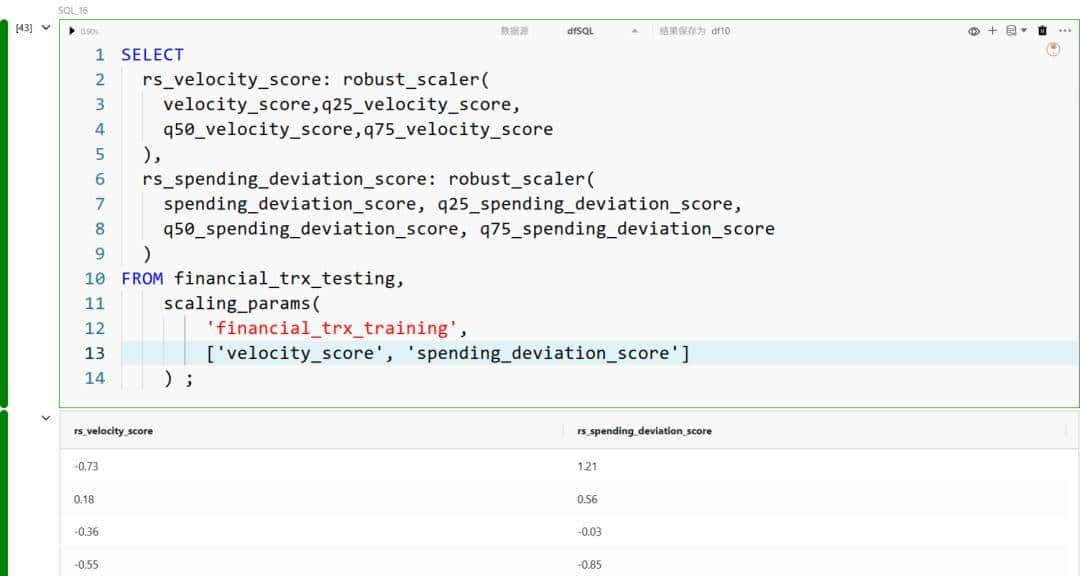
我们为鲁棒缩放计算定义标量宏:

并且,与其他缩放转换类似,我们直接在 SQL 中调用它:
处理缺失值(Handling Missing Values)
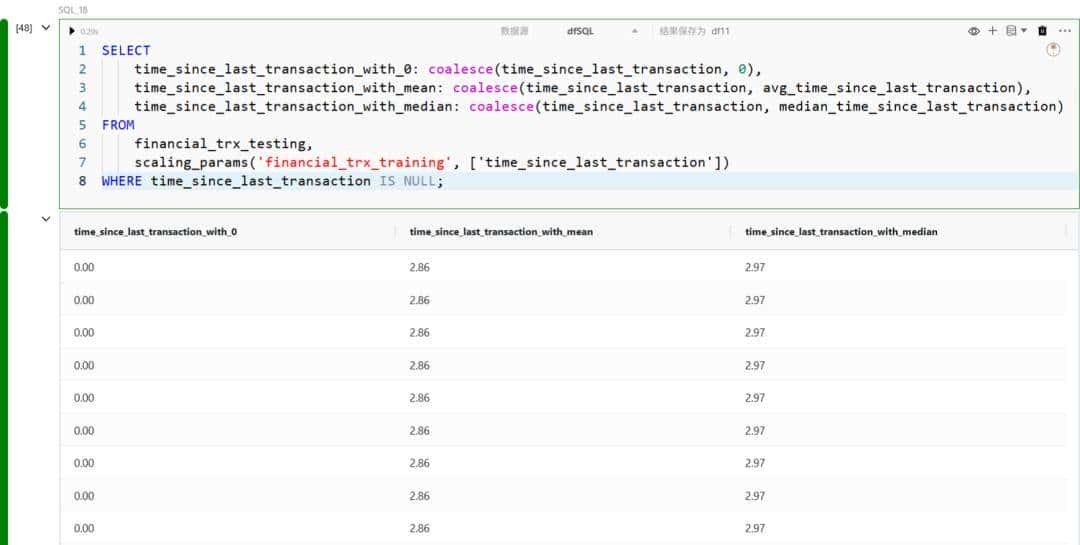
在实际数据处理中,输入数据往往存在不完整的情况,即包含缺失值。根据具体应用场景,这类数据可以被排除、直接使用,或者用一个常数填充。在 DuckDB 中,我们可以使用 coalesce 函数来获取列的值,如果列为 NULL,则返回默认值。
一些常用的缺失值处理方法包括:
- 用常数替换缺失值;
- 用平均值替换缺失值;
- 用中位数替换缺失值。
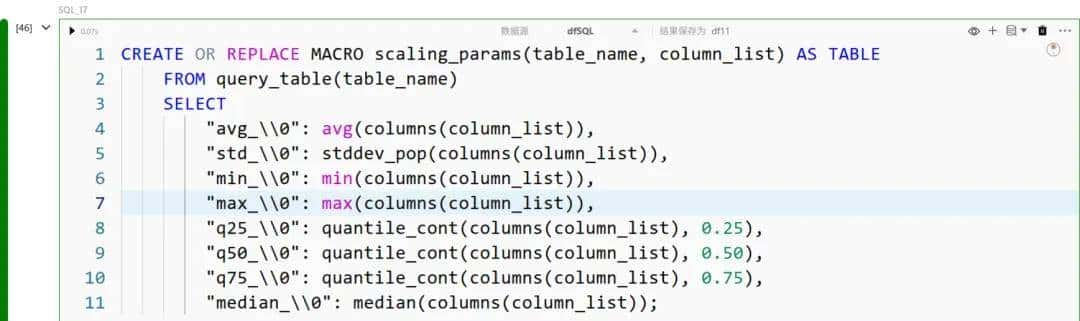
我们可以通过在 scaling_params 宏中加入中位数计算来扩展处理方法:
我们根据用例应用合并来处理缺失值:
在特征缩放之前应该填充缺失数据。
在本文中,我们演示了 DuckDB 如何为机器学习工作流提供高性能且 SQL 原生的数据预处理方法。通过直接在数据库引擎内部处理缺失值插补、分类编码和特征缩放等任务,可以消除不必要的数据移动并减少预处理延迟。

















暂无评论内容