
前言:日志乱象的技术债务与治理必要性
作为技术架构师,在多年的系统设计和代码评审中,我目睹了太多因日志滥用导致的技术债务:
- 性能损耗:DEBUG级别日志在生产环境全量输出,导致I/O阻塞和存储浪费
- 安全漏洞:敏感信息(密码、密钥)明文记录,违反安全合规要求
- 排查困难:缺乏统一TraceId,分布式请求链路无法追踪
- 监控失效:日志格式混乱,无法被日志平台有效解析和分析
本文将从架构设计角度,系统阐述如何构建高效、安全、可观测的日志体系。
一、日志规范治理:从混乱到有序
1.1 常见日志反模式与纠正方案
|
反模式 |
危害 |
架构纠正方案 |
|
log.debug(“用户ID:” + userId + “操作:” + operation) |
字符串拼接性能损耗 |
参数化日志:log.debug(“用户ID:{} 操作:{}”, userId, operation) |
|
log.error(“订单创建失败”) |
无法定位问题根因 |
完整异常记录:log.error(“订单创建失败,订单号:{}”, orderNo, exception) |
|
生产环境开启DEBUG级别 |
存储成本激增,性能下降 |
动态日志级别:通过配置中心实时调整,问题排查后及时恢复 |
|
日志中记录完整卡号 |
安全合规风险 |
敏感信息脱敏:卡号:${前6位}****${后4位} |
1.2 架构级日志规范制定
# 日志规范配置模板 (application-logging.yml)
logging:
level:
com.yourcompany: INFO
com.important.module: WARN
pattern:
# 标准化日志格式,便于解析
console: "%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level [%X{traceId:-N/A}] %logger{50}#%M:%L - %msg%n"
file:
path: /var/log/yourapp
# 日志文件滚动策略,避免单文件过大
max-size: 100MB
max-history: 30架构师管控要点:
- 通过代码规范插件在CI流程中强制检查日志规范
- 重大系统要求日志覆盖率达到关键路径100%
- 建立日志审计机制,定期扫描敏感信息泄露
二、全链路追踪架构设计
2.1 TraceId的架构价值与实现选型
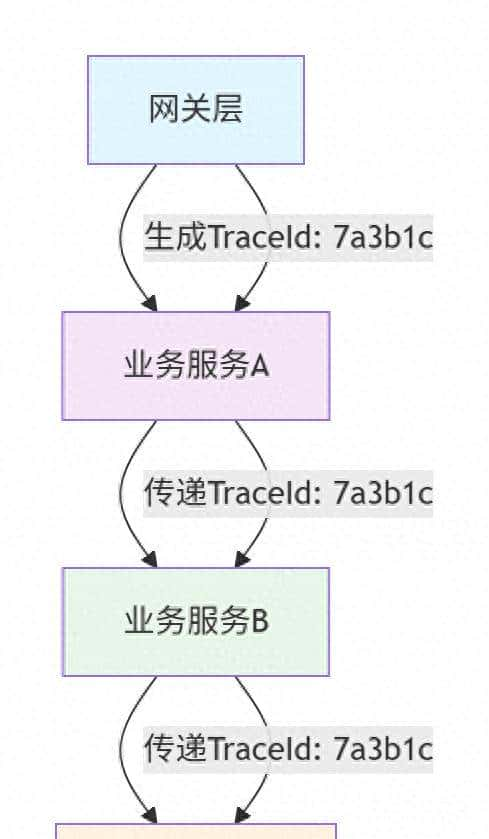
TraceId生成策略对比:
|
生成方式 |
优点 |
缺点 |
适用场景 |
|
UUID随机生成 |
简单易用,冲突概率低 |
长度较长,存储开销大 |
中小型系统 |
|
Snowflake算法 |
有序递增,便于排序 |
需要实例ID管理 |
大型分布式系统 |
|
时间戳+随机数 |
长度可控,可读性好 |
需要防冲突机制 |
一般业务系统 |
本文作者使用UUID随机生成,理由就是不用怕生成重复,也不用怕雪花的时间回拨等问题,另外互联网的大厂也这样用。
2.2 企业级TraceId实施方案
方案一:Spring Cloud Sleuth + Zipkin(推荐用于微服务架构)
// 1. 统一配置,确保TraceId传播
@Configuration
public class TracingConfig {
@Bean
public Sampler alwaysSampler() {
return Sampler.ALWAYS_SAMPLE;
}
// 自定义Span信息,丰富追踪数据
@Bean
public SpanHandler spanHandler() {
return new SpanHandler() {
@Override
public Mono<Void> doOnNext(TraceContext traceContext, Span span) {
span.tag("application", "order-service");
span.tag("environment", System.getenv("SPRING_PROFILES_ACTIVE"));
return Mono.empty();
}
};
}
}
// 2. 异步任务TraceId传递支持
@Async("mdcAwareTaskExecutor")
public void processOrderAsync(Order order) {
// 异步方法中自动携带TraceId
log.info("异步处理订单: {}", order.getId());
}方案二:自定义轻量级实现(适用于单体或简单微服务)
@Component
public class TraceIdFilter implements Filter {
private static final String TRACE_ID_HEADER = "X-Trace-Id";
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) {
HttpServletRequest httpRequest = (HttpServletRequest) request;
HttpServletResponse httpResponse = (HttpServletResponse) response;
// 获取或生成TraceId
String traceId = getOrGenerateTraceId(httpRequest);
// 设置到MDC和响应头
MDC.put("traceId", traceId);
httpResponse.setHeader(TRACE_ID_HEADER, traceId);
try {
chain.doFilter(request, response);
} finally {
// 确保清理,避免内存泄漏
MDC.clear();
}
}
private String getOrGenerateTraceId(HttpServletRequest request) {
String traceId = request.getHeader(TRACE_ID_HEADER);
if (StringUtils.isBlank(traceId)) {
// 使用更简洁的ID生成策略
traceId = IdUtil.getShortId(); // 示例:8位短ID
}
return traceId;
}
}三、日志组件技术选型指南
3.1 架构决策框架:如何选择合适的日志方案
// 架构决策树示例
public class LoggingFrameworkDecision {
public LoggingFramework decide(ProjectRequirements requirements) {
if (requirements.isHighPerformance()) {
return LoggingFramework.LOG4J2;
} else if (requirements.isSpringBootDefault()) {
return LoggingFramework.LOGBACK;
} else if (requirements.isLegacySystem()) {
return LoggingFramework.JUL;
} else {
return LoggingFramework.LOGBACK; // 默认选择
}
}
}3.2 企业级日志组件对比矩阵
|
维度 |
Logback (Spring Boot默认) |
Log4j2 (高性能) |
架构师提议 |
|
性能 |
良好 |
优秀(异步日志性能提升10倍) |
高并发场景选Log4j2 |
|
功能特性 |
基础功能完善 |
丰富(高级过滤、脚本支持) |
复杂需求选Log4j2 |
|
配置复杂度 |
简单 |
中等 |
团队技能思考 |
|
社区生态 |
活跃 |
超级活跃 |
长期项目优先 |
|
安全记录 |
良好 |
有历史漏洞但修复快 |
需关注安全公告 |
四、日志平台架构选型:ELK vs Loki深度对比
4.1 技术架构适配性分析
ELK技术栈:适合复杂分析场景
# 典型ELK架构配置
elasticsearch:
cluster-name: production-logs
indices:
# 按天分索引,便于管理
pattern: "app-logs-{date}"
logstash:
pipeline:
# 复杂的日志解析和处理管道
filters:
- grok: # 解析复杂日志格式
- mutate: # 字段转换
- elasticsearch: # 输出到ESLoki技术栈:云原生轻量方案
# Loki极简配置
loki:
storage:
- name: s3
s3: https://s3.amazonaws.com/logs-bucket
schema_config:
configs:
- from: 2023-01-01
store: boltdb-shipper
object_store: s34.2 架构选型决策矩阵
|
考量因素 |
ELK栈 |
Loki栈 |
架构指导 |
|
团队规模 |
需要专业运维 |
开发团队可维护 |
小团队选Loki |
|
日志量级 |
日均TB级别 |
日均GB级别 |
量级大选ELK需专业运维 |
|
查询需求 |
复杂聚合分析 |
关键词搜索、简单统计 |
分析需求复杂选ELK |
|
资源预算 |
服务器成本高 |
成本优化(存储节省60%+) |
预算有限选Loki |
|
技术栈 |
Java技术栈熟悉 |
Kubernetes原生 |
云原生环境选Loki |
五、企业级日志体系实施路线图
5.1 分阶段实施策略
阶段一:基础规范建设(1-2个月)
- ✅ 制定团队日志规范文档
- ✅ 统一日志格式和级别标准
- ✅ 代码扫描工具集成
阶段二:技术能力建设(2-3个月)
- ✅ TraceId全链路追踪实现
- ✅ 日志脱敏组件开发
- ✅ 关键业务日志覆盖率达标
阶段三:平台化建设(3-6个月)
- ✅ 选择合适的日志平台(ELK/Loki)
- ✅ 建立日志监控告警体系
- ✅ 实现日志审计和安全合规
5.2 架构师检查清单
// 日志健康度检查点
public class LoggingHealthCheck {
public void validateLoggingSystem() {
// 1. TraceId传递检查
checkTraceIdPropagation();
// 2. 性能影响评估
checkPerformanceImpact();
// 3. 安全合规验证
checkSecurityCompliance();
// 4. 监控覆盖评估
checkMonitoringCoverage();
}
private void checkTraceIdPropagation() {
// 验证网关->服务->异步任务->外部调用的TraceId连续性
log.info("TraceId连续性检查: {}", isTraceIdContinuous());
}
}
六、总结:构建可观测的日志体系
作为架构师,我们需要将日志从简单的调试工具提升为系统可观测性的核心支柱。优秀的日志体系应该具备:
- 可追踪性:通过TraceId实现全链路追踪
- 可分析性:结构化日志便于平台分析
- ⚡ 高性能:异步、分级存储避免性能瓶颈
- 安全性:敏感信息脱敏,符合安全合规
- 经济性:合理的存储策略控制成本
架构师决策要点:
- 根据团队技术栈和运维能力选择日志平台
- 建立强制性的日志规范和代码审查机制
- 将日志纳入系统设计的非功能性需求
- 定期进行日志体系健康度评估和优化
通过体系化的日志治理,我们不仅能快速定位问题,更能通过日志数据驱动系统优化,构建更加稳定、可靠的软件架构。
















暂无评论内容