
一、引言:为什么需要本地部署大模型?
随着 GPT-4、Llama 3 等大模型的爆发,云端 API 调用成为主流交互方式,但在企业级应用、隐私敏感场景(如医疗、金融)、离线环境中,本地部署具有不可替代的优势:
隐私安全:数据无需上传云端,避免信息泄露风险成本可控:一次性硬件投入替代按调用量计费的云端成本离线可用:无网络环境下仍能稳定运行定制灵活:可基于本地数据微调,适配特定业务场景
本文将从基础环境搭建到实战应用开发,全方位讲解大模型本地部署技术,包含 3 类部署工具实操、3 个完整应用案例,附代码、流程图和 Prompt 设计指南。
二、本地部署基础:硬件与环境准备
2.1 硬件要求参考
不同参数规模的模型对硬件要求差异显著,以下为实测最低配置(量化后):
| 模型类型 | 参数规模 | 推荐 GPU(显存) | 最低 CPU(内存) | 存储需求 |
|---|---|---|---|---|
| 轻量模型 | 2-7B | RTX 3090(24G)/A10 | i7-12700(32G 内存) | 10-30GB |
| 中等模型 | 13-33B | RTX 4090(24G)/A100 | i9-13900(64G 内存) | 30-80GB |
| 大型模型 | 70B+ | 多卡 A100(80G×2+) | 服务器 CPU(128G+) | 100GB+ |
表 1:不同规模模型的硬件要求参考
2.2 系统与依赖环境
2.2.1 操作系统选择
优先推荐:Ubuntu 22.04(对 GPU 支持最完善,适合生产环境)Windows 用户:Windows 11 + WSL2(兼顾兼容性与开发体验)macOS 用户:macOS 13+(M 系列芯片可利用 Metal 加速)
2.2.2 核心依赖安装
以 Ubuntu 为例,基础环境配置步骤:
bash
# 1. 安装Python(推荐3.10+)
sudo apt update && sudo apt install python3.10 python3.10-venv python3.10-dev
# 2. 创建虚拟环境
python3.10 -m venv llm-env && source llm-env/bin/activate
# 3. 安装CUDA(若有NVIDIA GPU)
# 参考NVIDIA官网安装对应版本,推荐CUDA 11.8+
nvidia-smi # 验证GPU驱动是否正常
# 4. 安装基础依赖库
pip install torch==2.1.0 transformers==4.36.2 accelerate==0.25.0 sentencepiece==0.1.99三、主流大模型选型与下载
3.1 开源模型特性对比
| 模型名称 | 开发者 | 许可证 | 优势场景 | 量化版本可用性 |
|---|---|---|---|---|
| Llama 3 8B | Meta | 非商业许可 | 通用对话、创意写作 | 4/8/16bit |
| Qwen 7B | 阿里达摩院 | 商业许可 | 中文理解、多轮对话 | 4/8/16bit |
| Phi-3 Mini | Microsoft | MIT 许可 | 轻量部署、代码生成 | 4/8bit |
| Mistral 7B | Mistral AI | Apache 2.0 | 效率平衡、工具调用 | 4/8/16bit |
表 2:适合本地部署的开源模型对比
3.2 模型下载方法
3.2.1 通过 Hugging Face 下载
需先注册 Hugging Face 账号并同意模型协议,以 Llama 3 8B 为例:
bash
# 安装huggingface-cli
pip install huggingface_hub
# 登录(需输入Access Token,在Hugging Face个人设置中获取)
huggingface-cli login
# 下载模型(指定4bit量化版本)
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="meta-llama/Llama-3-8B-Instruct",
local_dir="./models/Llama-3-8B-Instruct",
local_dir_use_symlinks=False,
revision="main" # 若需量化版本,指定如"4bit"分支
)3.2.2 国内加速下载(ModelScope)
针对国内用户,可使用阿里 ModelScope:
bash
pip install modelscope
from modelscope.hub.snapshot_download import snapshot_download
snapshot_download(
"qwen/Qwen-7B-Chat",
cache_dir="./models",
revision="master"
)四、三大部署工具实操教程
4.1 基础部署:Transformers 库(适合开发调试)
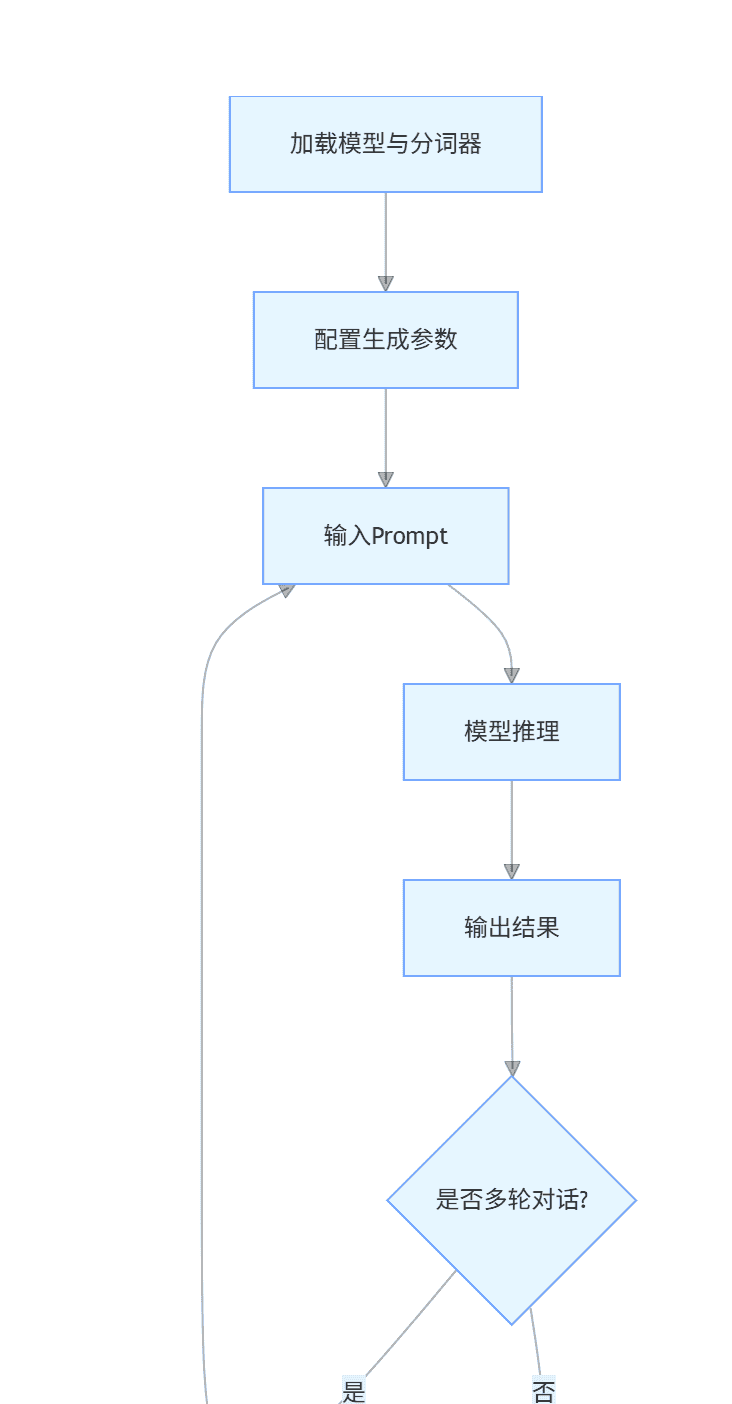
4.1.1 部署流程(mermaid 流程图)
graph TD
A[加载模型与分词器] --> B[配置生成参数]
B --> C[输入Prompt]
C --> D[模型推理]
D --> E[输出结果]
E --> F{是否多轮对话?}
F -->|是| G[更新对话历史]
G --> C
F -->|否| H[结束]4.1.2 代码实现(Llama 3 8B-Instruct)
python
运行
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
# 量化配置(4bit量化,降低显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载模型与分词器
model_path = "./models/Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=bnb_config,
device_map="auto", # 自动分配设备(GPU优先)
trust_remote_code=True
)
model.eval() # 推理模式
# 定义对话函数
def chat(prompt, history=[]):
# 构建Llama 3格式的Prompt
messages = history + [{"role": "user", "content": prompt}]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
# 生成配置
outputs = model.generate(
input_ids,
max_new_tokens=512, # 最大生成长度
temperature=0.7, # 随机性(0-1)
top_p=0.9, # 核采样参数
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# 提取回答
response = tokenizer.decode(
outputs[0][len(input_ids[0]):],
skip_special_tokens=True
)
return response, history + [{"role": "user", "content": prompt}, {"role": "assistant", "content": response}]
# 测试对话
if __name__ == "__main__":
history = []
while True:
user_input = input("用户: ")
if user_input.lower() in ["exit", "quit"]:
break
response, history = chat(user_input, history)
print(f"助手: {response}")4.2 高性能部署:vLLM(适合高并发场景)
vLLM 基于 PagedAttention 技术,吞吐量比 Transformers 高 10-20 倍,支持 API 服务部署。
4.2.1 部署步骤
bash
# 安装vLLM
pip install vllm
# 启动API服务(Llama 3 8B,支持OpenAI兼容接口)
python -m vllm.entrypoints.openai.api_server
--model ./models/Llama-3-8B-Instruct
--quantization awq # 使用AWQ量化加速
--port 8000
--host 0.0.0.0
--gpu-memory-utilization 0.9 # 显存利用率4.2.2 调用示例(OpenAI 兼容接口)
python
运行
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123" # 任意值
)
response = client.chat.completions.create(
model="Llama-3-8B-Instruct",
messages=[
{"role": "system", "content": "你是一个专业的技术助手,用简洁的语言回答问题。"},
{"role": "user", "content": "解释什么是vLLM的PagedAttention技术?"}
],
temperature=0.5,
max_tokens=300
)
print(response.choices[0].message.content)4.3 轻量部署:llama.cpp(适合 CPU / 低配置设备)
llama.cpp 支持 CPU 推理,且兼容多数开源模型(通过转换格式),适合嵌入式或无 GPU 环境。
4.3.1 部署流程
bash
# 1. 克隆仓库并编译
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make
# 2. 转换模型格式(以Llama 3为例)
python convert.py ../../models/Llama-3-8B-Instruct --outfile models/llama3-8b-f16.bin
# 3. 量化模型(4bit,适合CPU)
./quantize models/llama3-8b-f16.bin models/llama3-8b-q4_0.bin q4_0
# 4. 启动交互式对话
./main -m models/llama3-8b-q4_0.bin -i -r "### 助手:" -p "### 用户: 你好
### 助手:"五、实战应用案例开发
案例 1:本地知识库问答系统(企业文档查询)
需求分析
实现基于企业内部文档(PDF/Word)的本地化问答,支持精确检索 + 大模型生成,保护敏感信息。
技术架构(mermaid 流程图)
graph TD
A[用户提问] --> B[文本预处理]
B --> C[向量检索引擎]
D[本地知识库] --> E[文档分块+向量生成]
E --> C
C --> F[获取相关上下文]
F --> G[大模型生成回答]
G --> H[输出结果]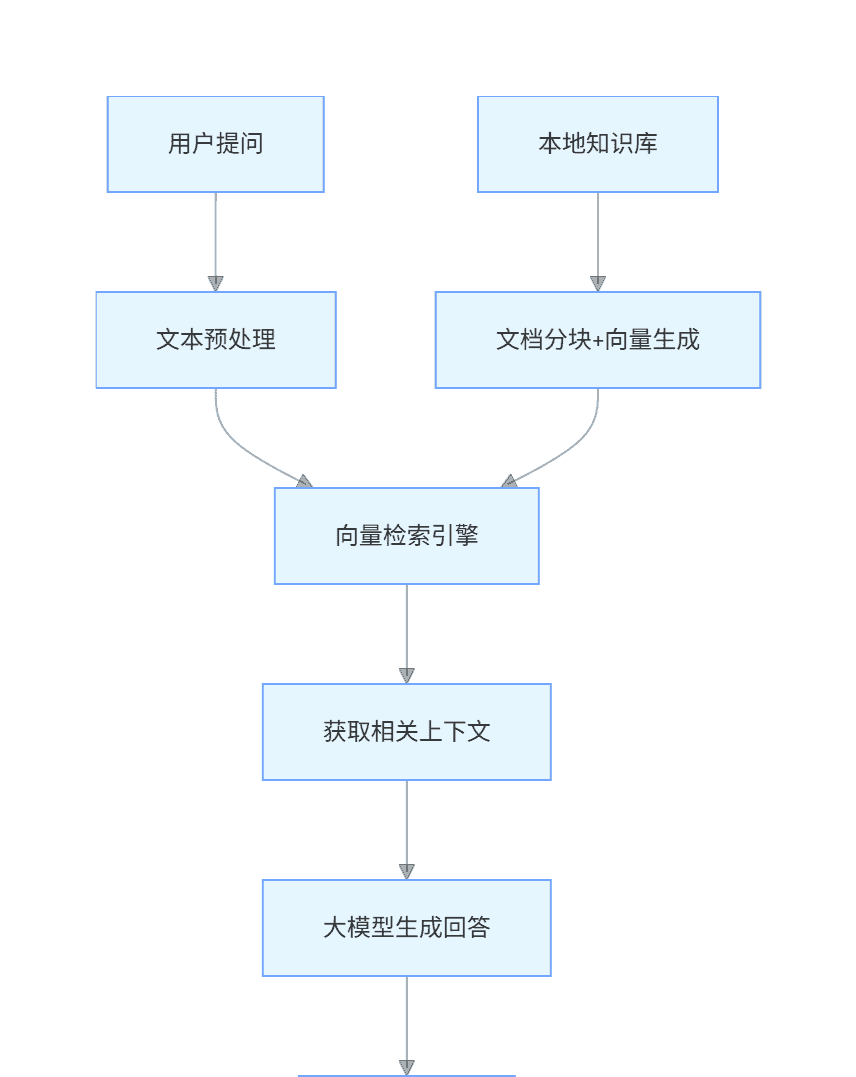
实现步骤
环境准备
bash
pip install langchain chromadb pypdf python-docx sentence-transformers
代码实现
python
运行
from langchain.document_loaders import PyPDFLoader, Docx2txtLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.llms import HuggingFacePipeline
from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer
# 1. 加载本地文档
def load_documents(doc_dir):
documents = []
# 加载PDF
for pdf in Path(doc_dir).glob("*.pdf"):
loader = PyPDFLoader(str(pdf))
documents.extend(loader.load())
# 加载Word
for docx in Path(doc_dir).glob("*.docx"):
loader = Docx2txtLoader(str(docx))
documents.extend(loader.load())
return documents
# 2. 文档分块
def split_documents(documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 块大小
chunk_overlap=50, # 重叠部分
separators=["
", "
", ".", " ", ""]
)
return text_splitter.split_documents(documents)
# 3. 初始化向量数据库
def init_vector_db(split_docs):
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-en-v1.5", # 轻量嵌入模型
model_kwargs={'device': 'cuda'}, # 用GPU加速
encode_kwargs={'normalize_embeddings': True}
)
# 持久化向量库到本地
db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory="./chroma_db"
)
db.persist()
return db
# 4. 配置大模型管道
def init_llm_pipeline(model_path):
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
load_in_4bit=True
)
# 定义生成管道
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.3,
top_p=0.9
)
# 包装为LangChain的LLM
llm = HuggingFacePipeline(pipeline=pipe)
return llm
# 5. 构建问答链
def build_qa_chain(db, llm):
# 自定义Prompt模板(关键!影响回答质量)
prompt_template = """
已知上下文:
{context}
基于上述上下文,用简洁准确的语言回答问题:{question}
注意:
1. 只使用上下文提供的信息,不编造内容
2. 若上下文无相关信息,回答"未找到相关内容"
3. 引用具体文档段落时标注来源(如"根据文档3.2节")
"""
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
llm_chain = LLMChain(llm=llm, prompt=prompt)
stuff_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context"
)
# 检索器(返回最相关的3个片段)
retriever = db.as_retriever(search_kwargs={"k": 3})
return RetrievalQA(
retriever=retriever,
combine_documents_chain=stuff_chain,
return_source_documents=True # 返回来源文档
)
# 6. 主函数
if __name__ == "__main__":
doc_dir = "./enterprise_docs" # 文档目录
model_path = "./models/Llama-3-8B-Instruct"
# 初始化(首次运行需执行,后续可注释)
# docs = load_documents(doc_dir)
# split_docs = split_documents(docs)
# db = init_vector_db(split_docs)
# 加载已有向量库
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
db = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings
)
# 启动问答
llm = init_llm_pipeline(model_path)
qa_chain = build_qa_chain(db, llm)
while True:
question = input("请输入问题(输入exit退出):")
if question.lower() == "exit":
break
result = qa_chain({"query": question})
print(f"回答:{result['result']}")
print("来源文档:")
for doc in result["source_documents"]:
print(f"- {doc.metadata['source']}(页码:{doc.metadata.get('page', '未知')})")Prompt 设计说明
明确限定 “仅使用上下文信息”,避免模型幻觉增加来源标注要求,提升回答可信度处理 “无相关信息” 的边界情况,增强鲁棒性
案例 2:离线代码生成助手(支持多语言)
需求分析
开发本地化代码生成工具,支持根据需求描述生成 Python/Java/JavaScript 代码,并提供注释和使用说明。
功能流程
用户输入需求(如 “写一个 Python 的快速排序函数”)模型生成代码 + 注释 + 测试用例支持代码解释和优化建议
代码实现
python
运行
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
class CodeGenerator:
def __init__(self, model_path):
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
load_in_4bit=True,
trust_remote_code=True
)
self.model.eval()
# 代码生成管道
self.code_pipeline = pipeline(
"text-generation",
model=self.model,
tokenizer=self.tokenizer,
max_new_tokens=1024,
temperature=0.6, # 代码生成适当降低随机性
top_p=0.95,
repetition_penalty=1.15 # 减少重复代码
)
def generate_code(self, requirement, language="python"):
"""生成指定语言的代码"""
# 代码生成Prompt(结构化模板)
prompt = f"""
请根据需求生成{language}代码:
需求:{requirement}
输出格式:
1. 功能说明:简要描述代码实现的功能
2. 代码:完整可运行的{language}代码,包含详细注释
3. 测试用例:验证代码功能的示例
4. 注意事项:使用时的潜在问题或优化建议
"""
# 针对Llama 3的格式封装
formatted_prompt = f"""<|begin_of_text|><|start_header_id|>user<|end_header_id|>
{prompt}
<|start_header_id|>assistant<|end_header_id|>
"""
# 生成代码
result = self.code_pipeline(formatted_prompt)[0]['generated_text']
# 提取助手回答部分
return result.split("<|start_header_id|>assistant<|end_header_id|>")[1].strip()
# 测试代码生成器
if __name__ == "__main__":
code_gen = CodeGenerator("./models/Phi-3-Mini-4K-Instruct") # Phi-3适合代码生成
while True:
req = input("请输入代码需求(输入exit退出):")
if req.lower() == "exit":
break
lang = input("请输入目标语言(默认python):") or "python"
code = code_gen.generate_code(req, lang)
print("
===== 生成结果 =====")
print(code)
print("===================
")效果示例
用户输入:”写一个 Python 函数,计算两个日期之间的工作日天数(排除周末和指定节假日)”
生成结果:
plaintext
1. 功能说明:
计算两个日期之间的工作日天数,自动排除周六和周日,并支持传入自定义节假日列表进行排除。
2. 代码:
import datetime
from typing import List, Optional
def count_workdays(
start_date: datetime.date,
end_date: datetime.date,
holidays: Optional[List[datetime.date]] = None
) -> int:
"""
计算两个日期之间的工作日天数(排除周末和节假日)
参数:
start_date: 开始日期
end_date: 结束日期(包含)
holidays: 自定义节假日列表,默认为空
返回:
工作日天数
"""
if start_date > end_date:
raise ValueError("开始日期不能晚于结束日期")
holidays = holidays or []
workdays = 0
current_date = start_date
while current_date <= end_date:
# 排除周末(周六:5,周日:6)
if current_date.weekday() < 5:
# 排除节假日
if current_date not in holidays:
workdays += 1
current_date += datetime.timedelta(days=1)
return workdays
3. 测试用例:
# 测试正常工作日
start = datetime.date(2023, 10, 9) # 周一
end = datetime.date(2023, 10, 13) # 周五
print(count_workdays(start, end)) # 输出:5
# 包含周末
start = datetime.date(2023, 10, 7) # 周六
end = datetime.date(2023, 10, 8) # 周日
print(count_workdays(start, end)) # 输出:0
# 包含节假日
holidays = [datetime.date(2023, 10, 10)] # 假设10月10日为节假日
print(count_workdays(start, end, holidays)) # 输出:4
4. 注意事项:
- 日期参数需为datetime.date类型,不可直接传入字符串
- 节假日列表需确保日期格式一致,建议使用datetime.date构造
- 若需处理跨年度日期,函数仍可正常工作
- 优化建议:对于超大日期范围(如超过1年),可考虑批量计算而非逐天循环案例 3:多模态本地助手(图文理解)
需求分析
基于多模态模型(如 LLaVA)实现本地图文交互,支持 “上传图片 + 提问” 模式(如 “分析这张图表的数据趋势”)。
技术准备
使用 LLaVA-1.5-7B 模型(开源多模态模型,支持图文理解)
代码实现
python
运行
from transformers import AutoProcessor, LlavaForConditionalGeneration
import torch
from PIL import Image
import requests
class MultimodalAssistant:
def __init__(self, model_path):
self.processor = AutoProcessor.from_pretrained(model_path)
self.model = LlavaForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
def chat_with_image(self, image_path, question):
"""结合图片回答问题"""
# 加载图片
if image_path.startswith("http"):
image = Image.open(requests.get(image_path, stream=True).raw)
else:
image = Image.open(image_path)
# 构建输入
prompt = f"USER: <image>
{question}
ASSISTANT:"
inputs = self.processor(prompt, image, return_tensors="pt").to("cuda", torch.float16)
# 生成回答
outputs = self.model.generate(
**inputs,
max_new_tokens=512,
temperature=0.5,
do_sample=True
)
response = self.processor.decode(outputs[0], skip_special_tokens=True).split("ASSISTANT:")[-1].strip()
return response
# 测试多模态助手
if __name__ == "__main__":
# 需先下载LLaVA-1.5-7B模型
assistant = MultimodalAssistant("./models/llava-v1.5-7b")
# 本地图片路径或URL
image_path = "./test_chart.png" # 假设为一张销售趋势图
question = "分析这张图表的趋势,指出销售额最高的月份和增长最快的阶段"
response = assistant.chat_with_image(image_path, question)
print(f"回答:{response}")Prompt 设计技巧
明确图片内容类型(如 “这是一张折线图”)指定分析维度(如 “从时间趋势、数值对比两方面分析”)要求结构化输出(如分点说明)
六、性能优化与问题排查
6.1 显存优化策略
1.** 模型量化 :优先使用 4bit/8bit 量化(比 16bit 节省 50%-75% 显存)2. 梯度检查点 :推理时启用
model.gradient_checkpointing_enable()
torch.cuda.empty_cache()
device_map="balanced"
6.2 常见问题解决方案
| 问题现象 | 可能原因 | 解决方法 |
|---|---|---|
| 显存溢出(OOM) | 模型过大或量化配置不当 | 降低量化位数(如 8bit→4bit);减小 batch_size |
| 推理速度慢 | CPU 推理或未启用加速 | 切换 GPU 模式;安装 FlashAttention 加速库 |
| 回答质量差 | Prompt 设计不合理 | 优化 Prompt 模板;增加上下文信息 |
| 模型加载失败 | 模型文件损坏或版本不兼容 | 重新下载模型;升级 transformers 版本 |
表 3:常见问题排查指南
七、总结与扩展方向
本文系统讲解了大模型本地部署的全流程,从硬件准备、模型选型到三大部署工具实操,并通过 3 个实战案例展示了本地化应用的开发方法。未来可扩展的方向包括:
1.** 模型微调 :基于本地数据进行 LoRA 微调,提升特定场景性能2. 多模型协同 :构建模型路由系统,根据任务自动选择最优模型3. 前端交互 :结合 Gradio/Streamlit 开发可视化交互界面4. 边缘部署 **:在嵌入式设备(如 Jetson)上部署轻量模型
本地部署大模型正在从技术探索走向实际应用,随着硬件成本降低和模型效率提升,更多企业和开发者将能享受到大模型的技术红利。
















暂无评论内容