在分布式系统中,数据同步是绕不开的话题 —— 列如用户下单后,订单数据需要实时同步到数据分析平台做库存计算,或者同步到搜索服务构建索引。而提到 MySQL 数据同步,阿里巴巴开源的Canal绝对是绕不开的利器。它轻量、高性能、实时性强,早已成为业内增量同步 MySQL 数据的首选方案之一。
一、为什么需要 Canal?先搞懂它的核心原理
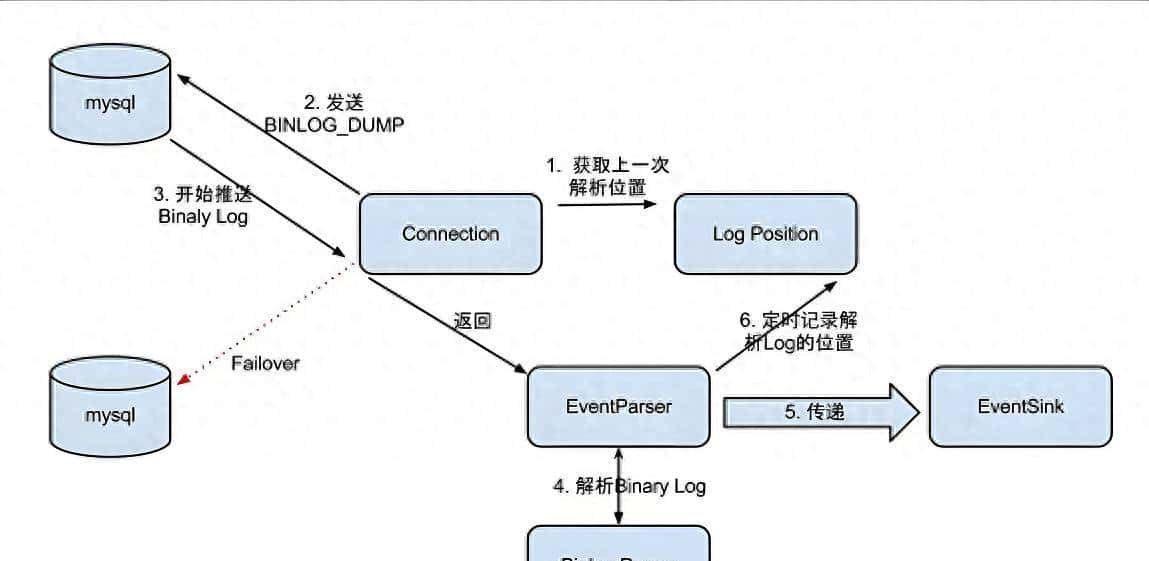
在聊怎么用之前,我们得先清楚:Canal 到底是怎么实现 MySQL 数据同步的?
1.1 本质:模拟 MySQL 从库的 “复制逻辑”
MySQL 主从复制的原理你肯定不陌生:
1. 主库(Master)将数据变更记录到binlog(二进制日志);
2. 从库(Slave)连接主库,发送dump命令,请求获取 binlog;
3. 主库的 IO 线程将 binlog 日志传给从库;
4. 从库的 IO 线程将接收到的 binlog 写入本地relay log(中继日志),SQL 线程再解析中继日志,执行 SQL 重现数据变更。
而 Canal 的核心思路,就是模拟一个 MySQL 从库:
1. Canal 伪装成从库,向 MySQL 主库发送dump请求;
2. 主库将 binlog 推送给 Canal;
3. Canal 解析 binlog 日志(将二进制格式转成可读的结构化数据);
4. 开发者通过 Canal Client 消费这些解析后的数据,同步到其他系统(如 ES、Redis、Kafka 等)。
这种方式的优势很明显:
5. 无侵入:不需要在 MySQL 主库写任何业务代码,仅依赖 binlog;
6. 实时性强:binlog 实时生成,Canal 实时解析,延迟一般在毫秒级;
7. 低性能损耗:主库推送 binlog 的开销极小,不会影响业务运行。
1.2 Canal 的核心组件
Canal 的架构主要分为两部分,部署和使用时需要重点关注:
1、 Canal Server(服务端):
1. 负责连接 MySQL 主库,订阅 binlog;
2. 解析 binlog 日志,将二进制数据转成结构化的Event(如插入、更新、删除事件);
3. 提供数据接口,供 Client 端获取同步数据。
2、 Canal Client(客户端):
1. 连接 Canal Server,拉取解析后的Event数据;
2. 自定义业务逻辑,将数据同步到目标存储(如写入 ES、发送到 Kafka、更新 Redis 缓存等);
3. 支持断点续传(记录消费位置),避免数据丢失。
二、实战第一步:Canal Server 部署(以 Linux 为例)
接下来我们从 0 开始,搭建 Canal Server 环境。在此之前,需要先满足两个前提条件:
2.1 前提:配置 MySQL 主库
Canal 依赖 MySQL 的 binlog,所以必须先确保主库开启 binlog,且配置正确:
1. 编辑 MySQL 配置文件(如/etc/my.cnf),添加以下配置:
|
# 开启binlog,日志格式必须为ROW(Canal仅支持ROW格式)
log-bin=mysql-bin
binlog-format=ROW # 主库唯一ID(从库也需要,Canal伪装从库时会用)
server-id=1
# 可选:指定需要同步的数据库(不指定则同步所有库)
binlog-do-db=test_db # 替换为你的业务数据库名
|
2. 重启 MySQL,验证配置是否生效:
|
— 执行后若显示ON,说明binlog已开启
show variables like 'log_bin';
— 查看binlog格式(需为ROW)
show variables like 'binlog_format';
|
3. 创建 Canal 专属账号,并授予权限:
|
— 创建账号(用户名:canal,密码:Canal@123)
CREATE USER 'canal'@'%' IDENTIFIED BY 'Canal@123';
— 授予复制权限(Canal需要模拟从库,必须有此权限)
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
— 刷新权限
FLUSH PRIVILEGES;
|
2.2 下载并部署 Canal Server
Canal 的官方下载地址:https://github.com/alibaba/canal/releases,提议选择稳定版(如 1.1.7)。
1. 下载并解压安装包:
|
# 下载(替换为最新稳定版链接)
wget
https://github.com/alibaba/canal/releases/download/canal-1.1.7/canal.deployer-1.1.7.tar.gz
# 创建安装目录
mkdir -p /opt/canal
# 解压到安装目录
tar -zxvf
canal.deployer-1.1.7.tar.gz -C /opt/canal
|
2. 配置 Canal Server:
进入配置目录,修改instance.properties(每个 “实例” 对应一个 MySQL 主库的同步配置):
|
cd /opt/canal/conf/example # example是默认实例名,可自定义
vim instance.properties
|
关键配置项修改如下(其他保持默认):
|
# 1. MySQL主库地址(IP:端口)
canal.instance.master.address=192.168.1.100:3306
# 2. MySQL账号密码(刚才创建的canal账号)
canal.instance.dbUsername=canal
canal.instance.dbPassword=Canal@123
# 3. 同步的数据库(与MySQL配置的binlog-do-db一致)
canal.instance.defaultDatabaseName=test_db
# 4. 从哪个binlog文件开始同步(首次同步可留空,Canal会自动找最新的)
canal.instance.master.journal.name=
# 5. 从binlog的哪个位置开始同步(首次同步可留空)
canal.instance.master.position=
|
3. 启动 Canal Server:
|
# 进入bin目录
cd /opt/canal/bin
# 启动
sh startup.sh
# 查看日志,验证是否启动成功(无ERROR则正常)
tail -f
/opt/canal/logs/canal/canal.log
tail -f
/opt/canal/logs/example/example.log
|
三、编写 Canal Client,实现数据同步
Canal Server 启动后,就需要编写 Client 端代码,消费同步过来的数据。这里以 Java 为例,演示如何将 MySQL 的user表数据同步到本地日志(实际业务中可替换为同步到 ES、Redis 等)。
3.1 引入依赖(Maven)
在pom.xml中添加 Canal Client 的依赖:
|
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.7</version>
<!– 与Server版本保持一致 –>
</dependency>
|
3.2 编写 Client 核心代码
核心逻辑:连接 Canal Server,循环拉取数据,解析数据并处理业务逻辑。
|
import
com.alibaba.otter.canal.client.CanalConnector;
import
com.alibaba.otter.canal.client.CanalConnectors;
import
com.alibaba.otter.canal.protocol.CanalEntry;
import
com.alibaba.otter.canal.protocol.Message;
import
java.net.InetSocketAddress;
import java.util.List;
public class CanalClientDemo {
public static void main(String[] args) {
// 1. 配置Canal Server地址、实例名、账号密码(默认账号密码都是canal)
String host = “192.168.1.101”; // Canal Server所在服务器IP
int port = 11111; // Canal默认端口
String destination = “example”; // 实例名(与Server配置的一致)
String username = “canal”;
String password = “canal”;
// 2. 创建Canal连接器
CanalConnector connector =
CanalConnectors.newSingleConnector(
new InetSocketAddress(host, port),
destination,
username,
password
);
try {
// 3. 连接Canal Server
connector.connect();
// 4. 订阅数据(*.*表明订阅所有库所有表,也可指定如test_db.user)
connector.subscribe(“test_db.user”);
// 5. 回滚到上次消费的位置(避免重复消费)
connector.rollback();
// 6. 循环拉取数据(实际业务中可放在线程池里)
while (true) {
// 拉取数据(1024表明一次最多拉取1024条记录)
Message message = connector.getWithoutAck(1024);
// 获取批次ID
long batchId = message.getId();
// 获取数据条数
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
// 没有数据,休眠1秒再拉取(避免空轮询消耗CPU)
Thread.sleep(1000);
} else {
// 7. 解析并处理数据
handleMessage(message.getEntries());
// 8. 确认消费成功(Canal会记录消费位置,下次从这里开始)
connector.ack(batchId);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 9. 关闭连接器
connector.disconnect();
}
}
/**
* 解析Canal消息,处理数据变更
*/
private static void handleMessage(List<CanalEntry.Entry> entries) throws Exception {
for (CanalEntry.Entry entry : entries) {
// 过滤非ROWData类型的日志(如事务开始、结束的日志)
if (entry.getEntryType() !=
CanalEntry.EntryType.ROWDATA) {
continue;
}
// 解析binlog日志的内容(转成JSON格式,方便查看)
CanalEntry.RowChange rowChange =
CanalEntry.RowChange.parseFrom(entry.getStoreValue());
// 获取数据变更类型(INSERT/UPDATE/DELETE)
CanalEntry.EventType eventType = rowChange.getEventType();
// 获取表名
String tableName = entry.getHeader().getTableName();
System.out.printf(“=== 表名:%s,变更类型:%s ===
“, tableName, eventType);
// 遍历每一行数据
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
if (eventType ==
CanalEntry.EventType.DELETE) {
// 处理删除操作(旧数据)
printColumn(
rowData.getBeforeColumnsList());
} else if (eventType ==
CanalEntry.EventType.INSERT) {
// 处理插入操作(新数据)
printColumn(
rowData.getAfterColumnsList());
} else {
// 处理更新操作(旧数据和新数据)
System.out.println(“旧数据:”);
printColumn(
rowData.getBeforeColumnsList());
System.out.println(“新数据:”);
printColumn(
rowData.getAfterColumnsList());
}
}
}
}
/**
* 打印列数据(字段名+字段值)
*/
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.printf(“字段名:%s,字段值:%s,是否为主键:%s
“,
column.getName(),
column.getValue(),
column.getIsKey() ? “是” : “否”);
}
}
}
|
Canal 作为阿里开源的 MySQL 同步工具,凭借其 “无侵入、高性能、实时性强” 的特点,成为了分布式系统中数据同步的首选方案。本文从原理到实战,介绍了 Canal 的部署、Client 编写和进阶用法,希望能协助你快速上手。
实际业务中,Canal 的应用场景远不止于此 —— 列如同步数据到 ES 构建搜索索引、同步到 Redis 做缓存预热、同步到数据仓库做离线。

















暂无评论内容