
引言:为什么我们需要本地大模型?
随着ChatGPT、Claude等云端大语言模型(LLM)的崛起,我们见证了AI能力的飞跃。然而,将所有数据和处理都依赖于第三方云服务,也带来了数据隐私、成本控制、网络依赖和定制化自由度等方面的挑战。
本地部署大模型,正是为了解决这些痛点而生。它意味着将强大的AI能力直接运行在你的个人电脑或服务器上,带来以下核心优势:
数据隐私与安全:所有数据均在本地处理,无需上传到云端,对于企业内部文档、个人隐私信息等敏感内容至关重要。成本效益:一次部署,终身使用。无需为每次API调用付费,尤其适合高频使用场景。离线可用性:无网络环境下也能正常运行,适用于移动办公、特殊工业环境等。高度定制化:可以针对特定领域(如法律、医疗、金融)进行微调,打造专属的专家模型,并自由集成到各种应用中。
本文将作为一份详尽的指南,带你从硬件准备开始,一步步完成大模型的本地部署,并最终构建一个实用的“本地知识库问答”应用。
第一部分:基础准备 – 开启本地AI之旅
在开始之前,我们需要确保有合适的“土壤”来培育我们的AI模型。
1.1 硬件要求:你的“算力家底”
大模型的运行对硬件有一定要求,尤其是GPU。以下是不同等级的配置建议:
| 组件 | 最低要求(体验7B模型) | 推荐配置(流畅运行13B-34B模型) | 理想配置(探索更大模型) |
|---|---|---|---|
| CPU | 4核心 | 8核心或更多 | 16核心或更多 |
| 内存 (RAM) | 16 GB | 32 GB | 64 GB 或更多 |
| 显卡 (GPU) | NVIDIA GTX 1660 (6GB VRAM) | NVIDIA RTX 3060 (12GB VRAM) / RTX 4080 (16GB VRAM) | NVIDIA RTX 4090 (24GB VRAM) 或 A100/H100 |
| 硬盘 (Storage) | 50GB SSD | 100GB NVMe SSD | 1TB+ NVMe SSD |
核心要点:
GPU是关键:NVIDIA显卡因其CUDA生态系统的成熟,是目前本地部署的首选。VRAM(显存)大小直接决定了你能运行的模型规模和速度。内存很重要:模型加载和处理过程需要大量内存,内存不足会导致系统频繁使用虚拟内存(硬盘),速度极慢。SSD是必须:模型文件通常很大(几GB到几十GB),使用固态硬盘(SSD)可以极大缩短加载时间。
[图片描述:一张展示不同GPU(如RTX 3060, 4090)和其对应VRAM容量的对比图,旁边标注着它们能流畅运行的模型参数量(如7B, 13B, 70B)。]
1.2 软件环境:搭建“AI工作台”
我们将以Linux(如Ubuntu 22.04)为例,因为它对AI开发的支持最好。Windows和macOS用户也可参照,但部分步骤可能需要调整。
安装Python:推荐使用Conda来管理环境,避免版本冲突。
# 下载并安装Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 创建并激活一个专用环境
conda create -n llm_local python=3.10
conda activate llm_local安装NVIDIA驱动与CUDA:
访问NVIDIA官网,下载并安装与你显卡匹配的最新驱动程序。安装CUDA Toolkit(推荐版本11.8或12.x)。安装后,在终端输入
nvidia-smi
安装核心Python库:
# PyTorch是深度学习框架,CUDA版本需对应
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Hugging Face生态,模型加载和处理的瑞士军刀
pip install transformers accelerate
# 量化库,用于在显存中运行更大的模型
pip install bitsandbytes
# 一个高性能的LLM推理引擎
pip install llama-cpp-python第二部分:模型部署 – 两种主流方法
部署模型有多种方式,这里我们介绍两种最主流的方法:
llama.cpp
transformers
2.1 方法一:使用
llama.cpp
llama.cpp
llama.cpp
流程图:
llama.cpp
graph TD
A[“开始”] –> B[“从 GitHub 克隆 llama.cpp 仓库”];
B –> C[“编译 llama.cpp(执行 make 命令)”];
C –> D[“从 Hugging Face 下载 GGUF 格式模型”];
D –> E[“使用 ./main 命令启动模型”];
E –> F[“在终端进行交互式对话”];
F –> G[“结束”];
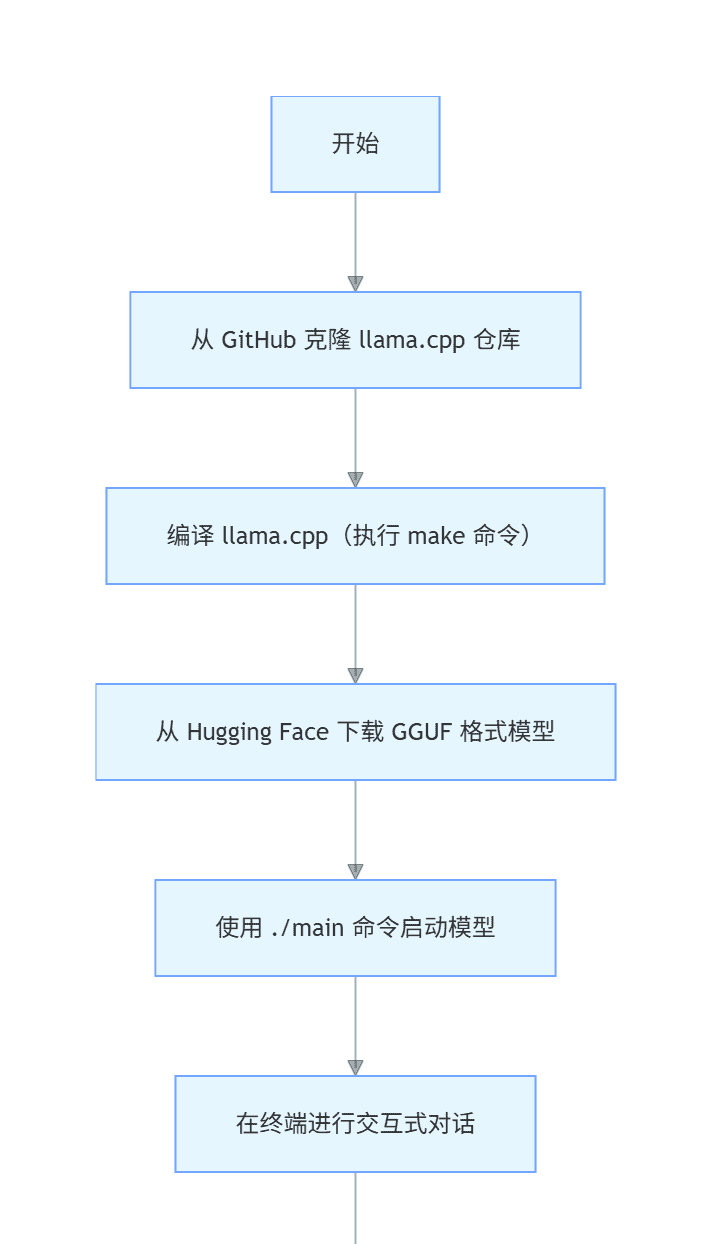
实战步骤:
获取并编译
llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# 如果有NVIDIA GPU,启用CUDA支持以加速
make LLAMA_CUDA=1下载GGUF模型:
GGUF模型由社区成员量化后发布。Hugging Face是主要来源。我们以流行的Mistral 7B Instruct模型为例。
访问Hugging Face上的TheBloke/Mistral-7B-Instruct-v0.2-GGUF页面。选择一个合适的量化版本。
Q4_K_M
git lfs
# 安装git-lfs用于下载大文件
git lfs install
git clone https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF
# 进入下载目录,模型文件就在里面
cd Mistral-7B-Instruct-v0.2-GGUF运行推理:
回到
llama.cpp
./main -m ../Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q4_K_M.gguf
-n 512
--color
-i
-r "User:"
--in-prefix " "
**参数解释**:
* `-m`:指定模型文件路径。
* `-n`:生成文本的最大长度。
* `--color`:使输出带颜色,更易读。
* `-i`:进入交互模式。
* `-r` 和 `--in-prefix`:用于设置对话的停止符和前缀,以匹配模型的训练格式。现在你就可以在终端里与Mistral模型对话了!
2.2 方法二:使用 Hugging Face
transformers
transformers
对于开发者而言,直接在Python代码中加载和使用模型更为灵活。
transformers
流程图:
transformers
graph TD
A[“开始”] –> B[“安装核心 Python 库(transformers、accelerate、bitsandbytes 等)”];
B –> C[“编写 Python 脚本(含模型加载、生成逻辑)”];
C –> D[“用 AutoModelForCausalLM 加载目标模型”];
D –> E[“配置量化参数(如 load_in_4bit=True,依赖 bitsandbytes)”];
E –> F[“选择生成方式(Pipeline 封装调用 / 手动写生成循环)”];
F –> G[“运行脚本,获取文本生成输出”];
G –> H[“结束”];
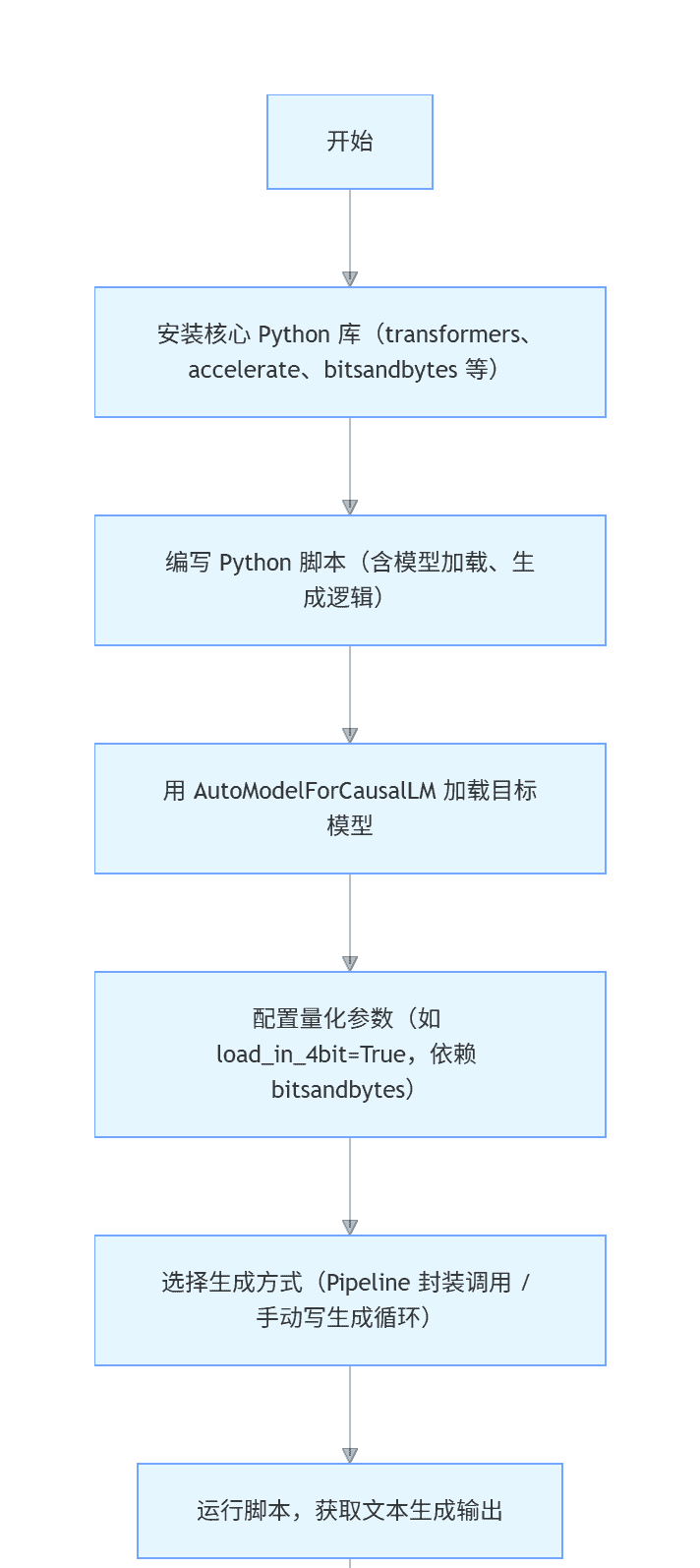
实战代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# 模型ID,来自Hugging Face Hub
model_id = "mistralai/Mistral-7B-Instruct-v0.2"
# 加载Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载模型,并启用4-bit量化以节省显存
# load_in_4bit=True 需要安装 bitsandbytes 库
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto", # 自动分配到GPU/CPU
torch_dtype=torch.bfloat16, # 使用bfloat16精度,平衡速度和效果
load_in_4bit=True, # 关键:4-bit量化
)
# 创建一个文本生成pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# 准备Prompt,遵循Mistral的Instruct格式
prompt = "<s>[INST] 请用一句话解释什么是量子纠缠。 [/INST]"
# 生成文本
outputs = pipe(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
print(outputs[0]['generated_text'])代码解释:
device_map="auto"
accelerate
load_in_4bit=True
pipeline
transformers
第三部分:应用实战 – 构建本地RAG知识库问答机器人
仅仅和模型聊天是不够的,真正的价值在于解决实际问题。我们来构建一个检索增强生成应用,它能基于你提供的本地文档(如PDF、TXT)来回答问题,有效避免模型“胡说八道”(幻觉)。
RAG核心思想:不直接问模型问题,而是先从你的知识库中找到最相关的几段文字,然后将这些文字和问题一起“喂”给模型,让它基于提供的上下文来回答。
流程图:RAG应用工作流程
graph TD
A[用户提问] –> B[将问题向量化];
B –> C[在向量数据库中检索最相似的文档片段];
C –> D[构建包含上下文的Prompt];
D –> E[将Prompt发送给本地LLM];
E –> F[LLM基于上下文生成答案];
F –> G[将答案返回给用户];
subgraph 准备阶段
H[加载本地文档] –> I[将文档切分成小块];
I –> J[使用Embedding模型将文档块向量化];
J –> K[将向量存入向量数据库];
end
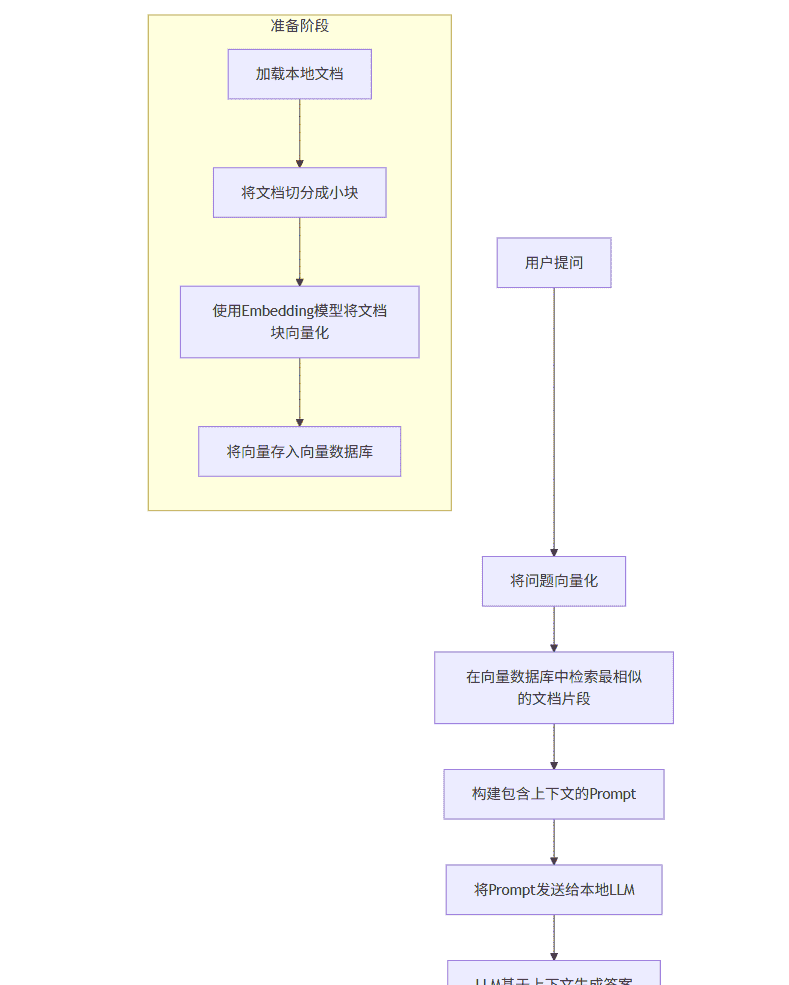
3.1 技术栈选择
LLM:我们已部署的Mistral-7B-Instruct。文档处理与框架:
LangChain
ChromaDB
sentence-transformers
3.2 实现步骤
步骤1:安装所有依赖
pip install langchain langchain_community langchain_chroma sentence-transformers pypdf
步骤2:准备知识库
创建一个名为
knowledge_base
.txt
.pdf
ai_history.txt
人工智能的历史可以追溯到1950年。艾伦·图灵提出了著名的“图灵测试”来判断机器是否具有智能。
1956年,在达特茅斯会议上,约翰·麦卡锡首次提出了“人工智能”这一术语,标志着AI学科的诞生。
深度学习是机器学习的一个分支,它在2010年代取得了突破性进展,特别是在图像和语音识别领域。
Transformer架构是2017年由Google提出的,它彻底改变了自然语言处理领域,是当今所有主流大模型(如GPT、Llama)的基础。步骤3:编写Python脚本实现RAG
创建一个
rag_app.py
import os
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# --- 1. 加载和切分文档 ---
def load_and_split_docs(directory_path):
documents = []
for filename in os.listdir(directory_path):
file_path = os.path.join(directory_path, filename)
if filename.endswith(".txt"):
loader = TextLoader(file_path, encoding='utf-8')
elif filename.endswith(".pdf"):
loader = PyPDFLoader(file_path)
else:
continue
documents.extend(loader.load())
# 文本切分器,chunk_size是每块的大小,chunk_overlap是块之间的重叠
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
return docs
# --- 2. 创建向量数据库 ---
def create_vector_db(docs, persist_directory="./chroma_db"):
# 使用Hugging Face的Embedding模型
# all-MiniLM-L6-v2 是一个轻量且效果不错的模型
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 从文档创建Chroma向量数据库
vector_db = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory=persist_directory
)
return vector_db
# --- 3. 定义RAG链 ---
def setup_rag_chain(vector_db, llm):
# 定义检索器
retriever = vector_db.as_retriever(search_kwargs={"k": 3}) # 检索最相似的3个文档块
# 定义Prompt模板
template = """
请仅根据以下提供的上下文信息来回答问题。如果上下文中没有相关信息,请回答“根据提供的文档,我无法找到答案。”
上下文:
{context}
问题:
{question}
答案:
"""
prompt = PromptTemplate.from_template(template)
# 创建RAG链
# LangChain的LCEL语法,非常直观
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return rag_chain
# --- 主函数 ---
if __name__ == "__main__":
# 准备知识库
docs = load_and_split_docs("./knowledge_base")
if not docs:
print("知识库为空,请先在 ./knowledge_base 目录下放入 .txt 或 .pdf 文件。")
exit()
# 创建或加载向量数据库
# 如果数据库已存在,直接加载,否则创建
if os.path.exists("./chroma_db"):
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
else:
vector_db = create_vector_db(docs)
# 加载本地LLM (这里使用transformers pipeline作为示例)
# 在实际应用中,你可能需要将其封装成一个LangChain兼容的LLM对象
# 为简化,我们直接调用之前定义的pipeline
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", torch_dtype=torch.bfloat16, load_in_4bit=True
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=512)
# 将pipeline包装成LangChain可用的LLM
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
llm = HuggingFacePipeline(pipeline=pipe)
# 设置RAG链
rag_chain = setup_rag_chain(vector_db, llm)
# --- 交互式问答 ---
print("本地RAG知识库已准备就绪!输入 'exit' 退出。")
while True:
query = input("
请输入你的问题: ")
if query.lower() == 'exit':
break
# 调用RAG链
response = rag_chain.invoke(query)
print(f"
回答: {response}")
3.3 Prompt示例与解析
在RAG应用中,Prompt的设计至关重要。我们代码中使用的模板就是一个经典范例:
请仅根据以下提供的上下文信息来回答问题。如果上下文中没有相关信息,请回答“根据提供的文档,我无法找到答案。”
上下文:
{context}
问题:
{question}
答案:解析:
明确指令:第一句是核心指令,强制模型只能依据给定的
{context}
运行与测试:
将上述代码保存为
rag_app.py
knowledge_base
ai_history.txt
python rag_app.py
[图表描述:一个简单的柱状图,X轴为“问题类型”,Y轴为“回答准确率”。两个柱子分别为“基于知识库的问题”(准确率95%)和“知识库外的问题”(幻觉率5%),直观展示RAG的效果。]
第四部分:进阶与展望
掌握了基础的部署和RAG应用后,你还可以探索更多可能:
模型微调:如果你有特定领域的数据(如1000条法律问答),可以使用
LoRA
Streamlit
Gradio
vLLM
结论
本地部署大模型不再是遥不可及的技术。通过本文的指南,你已经从硬件选型、环境搭建,到模型部署,再到构建一个完整的RAG应用,走通了全流程。这不仅是技术的实践,更是将AI能力真正掌握在自己手中的开始。
从今天起,你可以利用这些工具,打造属于自己的、安全、高效、且高度定制化的AI应用,无论是用于提升个人工作效率,还是作为企业创新的基石。本地AI的未来,正由你我共同书写。

















暂无评论内容