

自监督学习英文名称是 Self-Supervised Learning,简写为 SSL。它是一种无监督学习 的分支技术,是指通过无标注数据自动生成伪标签(Pseudo Labels),使模型能够从数据本身中学习特征表明,而无需人工标注的监督信号。
自监督学习是通过设计假托任务(Pretext Task),让模型在解决这些任务的过程中学习数据的内在结构,从而获得对数据的通用表征能力。这些表征可迁移到下游任务(如分类、生成等)。
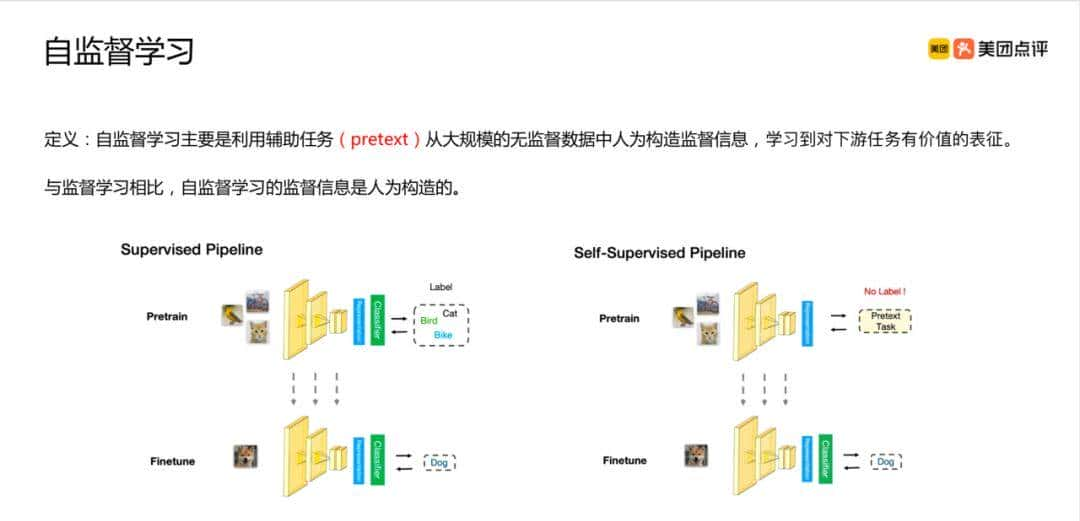
1. 自监督学习的背景与发展历程
1.1 背景信息
1.1.1 标注数据的局限性
监督学习依赖大量标注数据,但标注成本高昂且耗时,尤其在医疗、自动驾驶等领域,数据获取和标注难度更大。
无监督学习(如传统聚类、降维)虽无需标注,但难以捕捉语义信息,对下游任务协助有限。
1.1.2 自监督学习的提出
- 核心动机:
通过设计“代理任务”(Pretext Task),从数据自身生成伪标签,引导模型学习语义特征。
例如,通过预测图像旋转角度或文本中的掩码词,模型被迫理解数据的内在结构。
- 优势:
利用未标注数据,降低对人工标注的依赖6;
学习到的特征具有通用性,可迁移至多种下游任务
1.2 发展历程
1.2.1 早期探索(2010年代初期)
- 词向量表明:
Word2Vec(2013)通过上下文预测词向量,奠定了自监督学习的基础。
- 自编码器:
通过数据重建学习低维表明,但因缺乏语义导向,应用受限。
1.2.2 突破性进展(2018年后)
- BERT的崛起:
2018年,BERT 通过掩码语言建模(MLM)和下一句预测(NSP)任务,
在 NLP 领域实现突破,成为首个大规模自监督预训练模型。
- 对比学习的兴起:
SimCLR(2020)和 MoCo(2019)通过对比正负样本对,
在计算机视觉中取得显著效果,推动对比学习成为主流方法。
- 多模态与大规模模型:
CLIP(2021)通过图文对比学习实现跨模态对齐;
GPT-3(2020)和 T5(2020)则展示了自监督学习在大规模文本生成中的潜力。
1.2.3 当前趋势(2020年代中后期)
- 多模态融合:
联合训练图像、文本、语音等多模态数据,提升跨任务泛化能力。
- 轻量化与高效训练:
减少计算资源需求,推动边缘设备应用。
- 自动化设计:
结合 AutoML 技术,自动生成代理任务和优化模型架构。
2. 自监督学习的核心原理

2.1 数据的内在监督
自监督学习的核心在于利用数据自身的结构或关系生成监督信号。例如:
文本:通过掩码词预测上下文(如BERT)。
图像:通过预测图像的旋转角度或补全被遮挡部分。
视频:通过预测帧的顺序或时间连续性。
2.2 代理任务(Pretext Task)

定义:
人为设计的任务,目标是让模型通过这些任务学习通用的特征表明。
关键:
代理任务应与下游任务的特征需求相关(如语义理解、空间关系等)。
作用:
生成伪标签以指导模型学习数据的潜在特征。
常见任务类型:
对比学习(Contrastive Learning):最大化不同数据视图之间的类似性(如SimCLR、MoCo)。
生成学习(Generative Learning):通过编码-解码器重建数据(如MAE、Denoising Autoencoder)。
预测任务:预测数据中的缺失部分(如预测图像缺失区域、文本中的掩码词)。
2.3 特征表明迁移
下游任务(Downstream Task):
预训练模型通过代理任务学习到的特征,可以迁移到下游任务(如分类、检测)中,通过微调(Fine-tuning)或直接作为特征提取器使用。
迁移学习优势:
减少对标注数据的依赖,
提升模型泛化能力(如 BERT、GPT 等大语言模型基于此训练)。
2.4 数据效率
自监督学习能充分利用海量未标注数据,降低对人工标注的依赖,尤其适用于标注成本高的领域(如医疗、自动驾驶)
3. 自监督学习的关键方法
3.1 对比学习(Contrastive Learning)
原理:
正负样本对比:通过对比不同数据视图(如同一图像的不同增强版本),最大化正样本(同类)类似性,最小化负样本(异类)类似性。
数据增强:同一数据的多种增强视图(如裁剪、旋转)被视为正样本,增强模型对扰动的鲁棒性
公式示例:
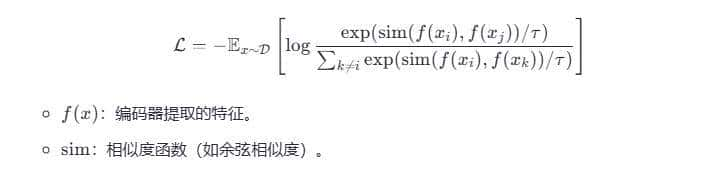
3.2 生成学习(Generative Learning)
原理:
通过编码器-解码器架构,学习数据的潜在表明并重建原始数据。
掩码重建:
如 BERT 的 MLM 任务,通过预测被掩码的输入部分(如文本中的词或图像块),学习上下文依赖关系。
自回归建模:
如 GPT 系列模型,通过预测序列中的下一个元素(词或像素),捕捉数据的时间或空间依赖。
公式示例:

3.3 对抗学习(Adversarial Learning)
原理:
通过生成器(Generator)和鉴别器(Discriminator)的对抗训练,
生成高质量数据并提升特征鲁棒性。
应用:
生成对抗网络(GAN)常用于图像生成,通过对抗训练使生成器欺骗鉴别器。
3.4 上下文预测(Context Prediction)
时序关系:
视频帧顺序预测或句子顺序判断,利用数据的时间或逻辑结构。
空间关系:
图像拼图(Jigsaw Puzzle)任务,要求模型恢复打乱的图像块顺序,学习空间语义。
3.5 理论基础扩展
表明学习理论:
通过代理任务学习到的低维表明应保留数据的语义信息,且在下游任务中可迁移。
信息最大化原则:
模型应最大化输入与表明之间的互信息,确保表明包含足够的信息量
4. 自监督学习的技术优势
4.1 减少对标注数据的依赖
优势:
利用海量未标注数据(如互联网文本、图像)训练模型,显著降低标注成本。
案例:
SEER模型:通过10亿张未标注的Instagram图像训练,在目标检测任务中达到 SOTA 性能。
DINO/DINOv2:在视觉任务中无需标注数据,成为多模态模型的视觉编码器首选。
4.2 提升泛化能力
机制:
学习到的特征表明具有更强的通用性,适应新领域或小样本场景。
案例:
医疗领域:标签成本高,自监督学习可减少标注需求。
多模态模型:DINOv2常用于视觉语言模型(VLM)的视觉编码。
4.3 动态适应与实时优化
结合强化学习:
如 Aifeex Takwin系统通过自监督强化学习,在复杂环境中实时调整策略,毫秒级响应。
5. 自监督学习的预训练步骤

5.1 数据准备与预处理
5.1.1 数据收集
获取无标注的原始数据(文本、图像、视频等),例如:
文本:维基百科、书籍、网页爬取内容。
图像:ImageNet未标注集、互联网图片。
视频:YouTube公开视频、监控录像。
5.1.2 数据清洗
过滤噪声数据:
文本:删除乱码、重复内容、非目标语言文本。
图像:去除低分辨率、损坏或无关图片。
视频:剔除静止帧或内容无关片段。
5.1.3 数据标准化
文本:统一大小写、分词、添加特殊标记(如[CLS]、[SEP])。
图像:归一化像素值(如缩放到[0,1]或标准化为均值为0、方差为1)。
时序数据:对齐采样频率(如视频统一为30fps)。
5.1.4 数据增强(关键步骤)
根据任务生成多样化的数据变体:
文本增强:同义词替换、随机掩码、句子重排。
图像增强:随机裁剪、旋转、颜色抖动、高斯噪声。
视频增强:帧速率变化、时空裁剪。
5.2 代理任务(Pretext Task)设计
任务类型选择
生成式任务:掩码重建(BERT的MLM)、自回归预测(GPT)。
对比式任务:SimCLR的视图对比、MoCo的动量编码。
上下文预测:句子顺序判断(BERT的NSP)、拼图恢复(Jigsaw)。
时序任务:视频帧顺序预测、未来帧生成。
任务参数设置
掩码比例:如BERT中掩码15%的词,MAE中掩码75%的图像块。
负样本策略:对比学习中负样本的数量与采样方式(内存库/批次内负样本)。
监督信号生成
自动化生成标签(伪标签):
掩码语言建模:原始被掩码词作为标签。
对比学习:同一数据增强样本对视为正样本。
5.3 模型架构搭建
骨干网络选择
文本:Transformer(BERT、GPT)、LSTM。
图像:ResNet、Vision Transformer(ViT)。
多模态:CLIP的双塔结构(图像编码器+文本编码器)。
任务头设计
生成式任务:输出层预测原始数据(如MLM的词汇分类头)。
对比式任务:投影头(Projection Head)将特征映射到低维空间(如SimCLR的MLP)。
参数初始化
使用预训练权重(如ImageNet预训练的ResNet)或随机初始化。
5.4 训练策略优化
损失函数设计
生成式任务:交叉熵损失(分类)、均方误差(回归)。
对比式任务:InfoNCE损失、Triplet Loss。
多任务联合训练:结合MLM和NSP(如BERT)。
优化器与学习率
常用优化器:AdamW、LAMB(大规模训练)。
学习率策略:线性预热(Warmup)、余弦衰减。
分布式训练
数据并行(Data Parallelism):单机多卡。
模型并行(Model Parallelism):如Megatron-LM的Transformer层拆分。
混合精度训练:FP16/AMP加速计算。
正则化与稳定性
梯度裁剪:防止梯度爆炸。
权重衰减:控制模型复杂度。
Dropout:防止过拟合(如BERT的Attention Dropout)。
5.5 模型评估与调优
代理任务验证
监控预训练任务的指标:
MLM的准确率、对比学习的特征类似度(如Top-1检索准确率)。
下游任务探针(Probing)
冻结预训练模型,添加简单分类头,评估特征质量:
文本:GLUE基准测试。
图像:线性分类(Linear Probing)。
超参数调优
调整掩码比例、学习率、批次大小等。
使用网格搜索或贝叶斯优化。
5.6 下游任务迁移
微调(Fine-tuning)
解冻部分或全部预训练参数,用标注数据微调:
全量微调:更新所有权重(适合充足标注数据)。
部分微调:仅更新分类头或顶层(适合小数据)。
提示学习(Prompt Tuning)
设计任务相关的提示模板(如“这句话的情感是[MASK]”),避免修改预训练模型。
特征提取
直接使用预训练模型提取特征,输入到独立的下游模型(如SVM)。
5.7 实际案例:BERT预训练步骤
数据:BooksCorpus + 英文维基百科(约33亿词)。
代理任务:MLM(掩码15%词) + NSP(50%正样本,50%负样本)。
模型:Transformer编码器(12层,768隐藏维度)。
训练:
批次大小:256
学习率:1e-4,1000步Warmup。
硬件:16个TPU,训练约4天。
评估:在GLUE、SQuAD等下游任务验证效果。
6. 实例:基于PyTorch的掩码语言模型(MLM)
以下是一个简化的BERT风格掩码语言模型实现,用于文本预训练。
6.1 环境准备
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
# 超参数
VOCAB_SIZE = 30522 # BERT-base的词典大小
MAX_LEN = 128 # 输入最大长度
BATCH_SIZE = 32
MASK_PROB = 0.15 # 掩码概率6.2 数据集构建
class MLMDataset(Dataset):
def __init__(self, texts, tokenizer, max_len):
self.tokenizer = tokenizer
self.texts = texts
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
inputs = self.tokenizer(
text,
max_length=self.max_len,
padding='max_length',
truncation=True,
return_tensors='pt'
)
# 创建掩码标签
input_ids = inputs['input_ids'].squeeze(0)
labels = input_ids.clone()
# 随机选择掩码位置
mask = torch.rand(input_ids.shape) < MASK_PROB
# 保留[CLS]和[SEP]
mask[0] = False
mask[-1] = False
# 80%替换为[MASK], 10%随机词, 10%保持不变
indices = torch.where(mask)[0]
for i in indices:
if torch.rand(1) < 0.8:
input_ids[i] = self.tokenizer.mask_token_id
elif torch.rand(1) < 0.5:
input_ids[i] = torch.randint(0, VOCAB_SIZE, (1,))
return {
'input_ids': input_ids,
'attention_mask': inputs['attention_mask'].squeeze(0),
'labels': labels
}
# 示例数据
texts = [
"Hello, how are you?",
"Self-supervised learning is powerful.",
"This is a masked language model example."
]
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
dataset = MLMDataset(texts, tokenizer, MAX_LEN)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE)6.3 模型定义
class BertMLM(nn.Module):
def __init__(self, vocab_size, d_model=768, nhead=8, num_layers=6):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model, nhead),
num_layers
)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, input_ids, attention_mask):
x = self.embedding(input_ids)
# 转换mask格式:0表明被padding的位置
key_padding_mask = (attention_mask == 0)
x = self.transformer(x, src_key_padding_mask=key_padding_mask)
logits = self.fc(x)
return logits
model = BertMLM(VOCAB_SIZE)6.4 训练循环
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
for epoch in range(5):
for batch in dataloader:
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['labels']
logits = model(input_ids, attention_mask)
loss = criterion(logits.view(-1, VOCAB_SIZE), labels.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")6.5 下游任务微调(示例:文本分类)
# 冻结底层参数(可选)
for param in model.embedding.parameters():
param.requires_grad = False
# 添加分类头
model.classifier = nn.Sequential(
nn.Linear(768, 256),
nn.ReLU(),
nn.Linear(256, 2) # 假设二分类
)
# 在分类数据上微调
# ...6.6 关键改善点
动态掩码:每次训练时重新生成掩码位置,避免过拟合。
更大模型:使用更多Transformer层和注意力头。
数据增强:加入随机截断、同义词替换等。
混合任务:结合MLM和NSP任务(如原始BERT)。
7. 自监督学习的最新进展
7.1 SimDINO:简化DINO训练流程
背景:
DINO系列需复杂工程(如温度调度、中心化操作),训练不稳定。
改善:
编码率正则化:通过显式正则化项防止特征崩溃,替代繁琐的超参数调整。
性能提升:训练更稳定,性能优于原始DINO,在ImageNet等任务中表现优异。
7.2 自监督强化学习(SSL+RL)
案例:
Aifeex Takwin系统:结合自监督学习提取特征与强化学习动态优化策略,实现实时决策。
优势:
在无标注环境中自主探索,减少人工干预。
7.3 大规模数据与模型
SEER模型:
通过10亿张未标注图像训练,证明自监督学习可处理超大规模数据。
多模态预训练:
如 BEiT-3 结合自监督学习与掩码预测,提升视觉-文本对齐能力。
8. 自监督学习的应用场景
8.1 计算机视觉
典型任务:
图像分类、目标检测(如DINO、MAE)。
视觉-语言模型(如CLIP、Flamingo)。
8.2 自然语言处理
典型模型:
BERT:通过掩码语言建模(MLM)预测缺失单词。
GPT系列:通过预测下一个词学习语言表征。
8.3 推荐系统
方法:
对比学习:通过用户-物品交互的对比学习提升推荐准确性。
生成学习:重建用户行为序列以捕捉潜在偏好。
8.4 多模态与跨领域
案例:
世界模型:Meta基于DINOv2构建,用于预测环境状态与动作。
视频理解:利用时间上下文(如相邻帧)作为监督信号。
自监督学习预训练的核心步骤涵盖数据→任务→模型→训练→迁移的全流程,其成功依赖于对数据内在规律的挖掘与高效的训练策略。通过合理设计代理任务、优化模型架构及训练方法,可以显著提升模型在下游任务中的表现,同时降低对标注数据的依赖。














暂无评论内容