
1.OpenVoice:轻松克隆任何声音用多种语言说话并可控制情感口音
由MyShellITTS开发。它能够仅使用一小段参考发言者的音频片段来复制其声音,然后能生成多种语言的语音。
openVoice能对声音风格的精细控制,包括情感、口音、节奏、停顿和语调,同时能够复制参考发言者的音色。
支持的语言包括英语(英国、美国、印度、澳大利亚)、西班牙语、法语、中文、日语和韩语。
网站
:http://research.myshell.ai/open-voice
GitHub: http://github.com/myshell-ai/OpenVoice
技术报告
:https://arxiv.org/pdf/2312.01479.pdf
在线演示
:http://lepton.ai/playground/openvoice
2.高效方法!Video-LAVIT:图文视频分解生成大模型!
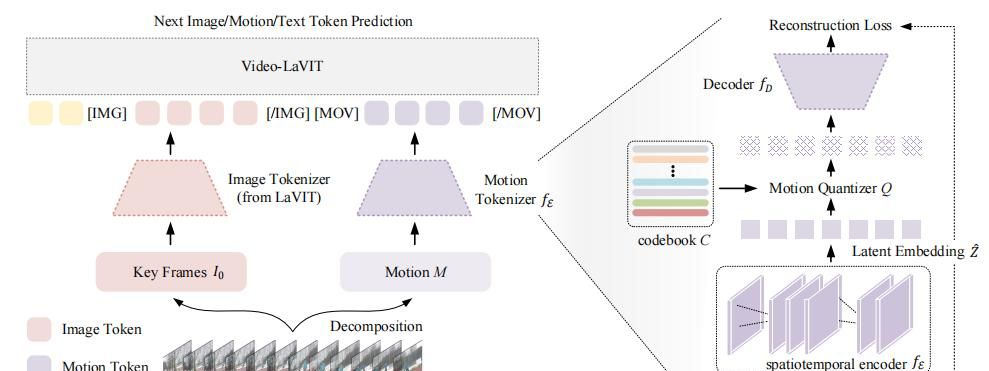
Video-LaVIT模型的核心在于将视频分解为关键帧和时间运动。视频一般被分为多个镜头,每个镜头内的视频帧往往存在大量的信息冗余。因此,将视频分解为交替的关键帧和运动向量,关键帧捕捉主要的视觉语义,而运动向量描述其对应关键帧随时间的动态演变。这种分解表明的好处在于,与使用3D编码器处理连续视频帧相比,单个关键帧和运动向量的组合需要更少的标记来表明视频的时空动态,这对于大规模预训练更为高效。
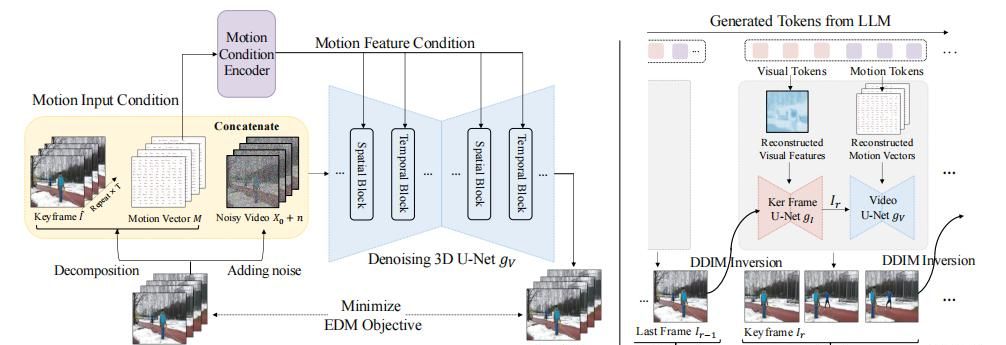
为了将连续的视频数据转换为紧凑的离散标记序列,Video-LaVIT设计了视频标记器。关键帧通过使用已建立的图像标记器进行处理,而时间运动的转换则通过设计一个时空运动编码器来实现。该编码器能够捕捉提取的运动向量中包含的随时间变化的上下文信息,从而显著提高LLMs理解视频中复杂动作的能力。
项目地址
:https://video-lavit.github.io
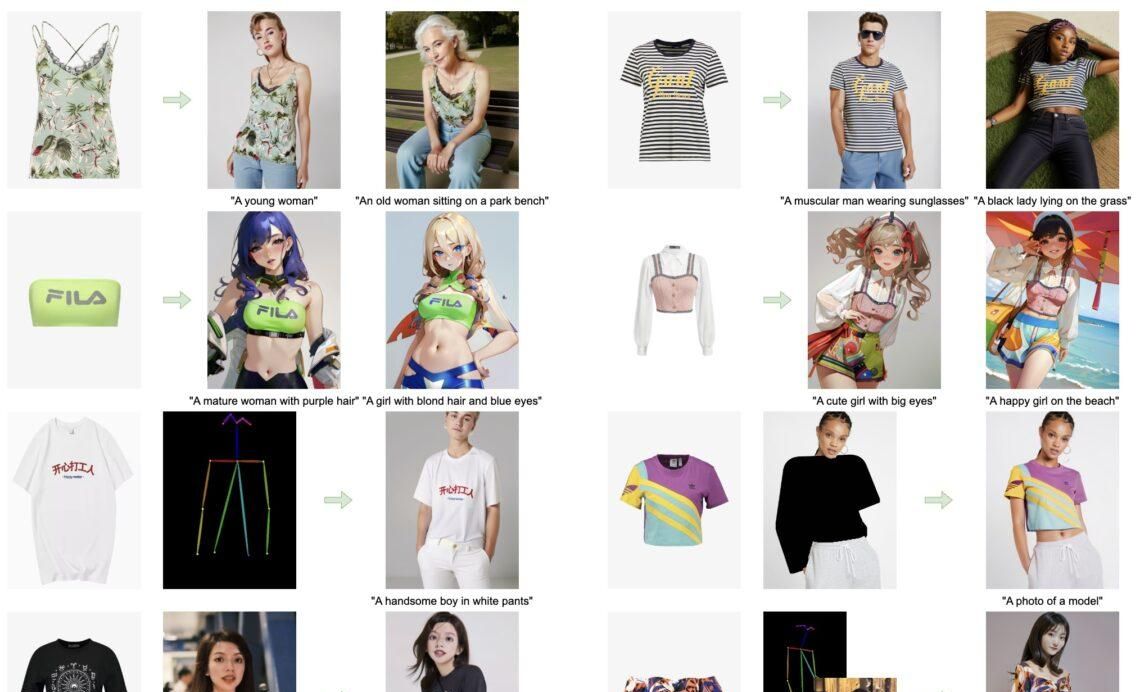
3.MagicClothing:根据文本提示定制生成穿着特定服装的人物图像
Magic Clothing是一个基于潜在扩散模型(Latent Diffusion Model, LDM)的图像合成系统,专门设计来处理服装驱动的图像合成任务。
它能够生成根据文本提示生成定制的、穿着特定服装的人物图像。这个系统通过在生成过程中融合服装细节,实现了高度可控和细粒度的图像输出。
Magic Clothing是OOTDiffusion的一个分支版本,侧重于可控服装驱动的图像合成。
github地址:
https://github.com/ShineChen1024/MagicClothing
4.DM-VTON:虚拟试衣技术能够生成高度真实的虚拟试衣图像
IDM-VTON是一个致力于提升虚拟试衣场景中的图像真实性和细节保留的新方法。让合成的试穿图片更加真实,细节更加精细,尤其是在真实环境中的应用表现更佳。
IDM-VTON能够生成高度真实的虚拟试,衣图像,协助用户在不实际穿着服装的情况下,通过图像看到自己穿上特定衣服的样子。这项技术尤其适用于在线购物,提升购物体验,协助消费者更好地做出购买决策。

在线体验:
https://huggingface.co/spaces/yisol/IDM-VTON
项目及演示:
https://idm-vton.github.io/
论文:
https://arxiv.org/abs/2403.05139
GitHub: https://github.com/yisol/IDM-VTON
5.打造自己的Al女友:基于Unity开发的Live2D虚桌拟人实时聊天系统
基于Unity开发的Live2D虚拟人聊天系统。它利用Live2D模型提供一个视觉上吸引人的虚拟人形象,结合Unity强劲的实时渲染功能,实现与用户的动态交互和聊天。
主要功能
1.Live2D虚拟人形象集成:
利用Live2D技术,项目实现了一个动态的虚拟人形象。这种技术允许二维图像在屏幕上以近乎三维的形式呈现,提供自然流畅的动画效果,增强用户交互体验。
2.实时聊天功能:
通过集成APIIAzure、OpenAl和APISpace,虚拟人能够与用户进行实时的文本交流。这些API支持基础的自然语言处理和生成,使虚拟人能够理解并回应用户的聊天输入。

github地址:
https://github.com/Navi-Studio/Virtual-Human-for-Chatting
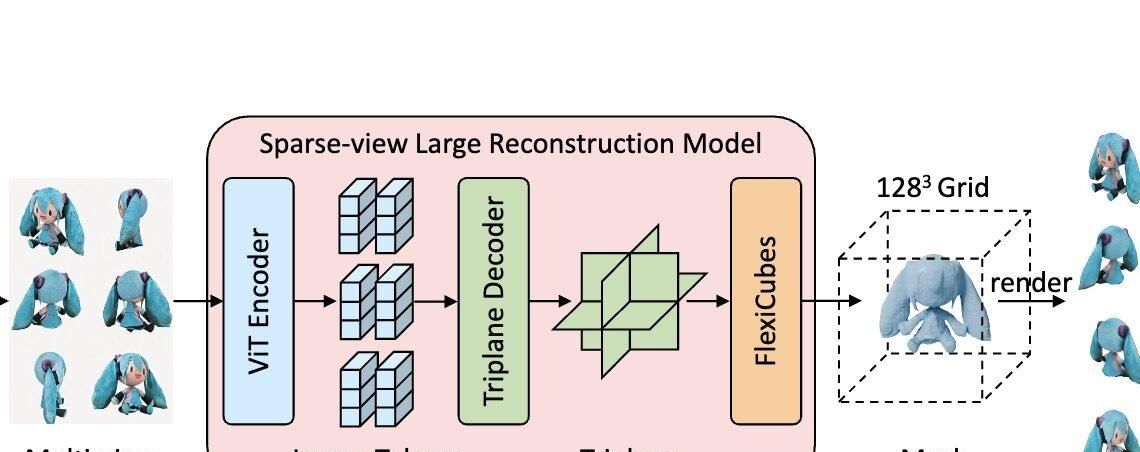
6.lnstantMesh: 10秒内从单张图片快速生成高质量的3D模型
InstantMesh是一个使用前馈框架的技术,它能够从单张图像快速生成高质量的三维网格模型。这个框架结合了多视图扩散模型和基于大规模重建模型(LRM)的稀疏视图重建技术,优化了3D资产的创建过程,并能在极短的时间(约10秒)内完成从图像到3D网格的转换。
“前馈式框架”(Feed-forward framework)在计算机科学和人工智能领域中,特别是在机器学习和神经网络中,是一个常见的概念。在这种框架中,输入数据通过一系列处理层流向输出,没有反馈〈即输出不会再次成为输入的一部分)的机制。这种模型的运作方式是单向的,即数据从输入端传递到输出端,中间可能经过多个处理阶段,但每个阶段只处理一次。
在线体验:
https://huggingface.co/spaces/TencentARC/InstantMesh
论文:
https://arxiv.org/abs/2404.07191
GitHub: https:/lgithub.com/TencentARC/InstantMesh
7.Twitter-Insight-LLM:抓取Twitter数据并可通过自然语言搜索图像
Twitter-Insight-LLM是一个开源项目,主要功能包括从Twitter抓取数据、基于嵌入的图像搜索,以及其他一些数据分析和处理功能。
同时利用LLM还能对Twitter数据进行深入分析,支持多种功能,包括数据可视化和图像标注。
主要功能:
1.Twitter数据抓取
2.基于嵌入的图像搜索
3.数据分析和可视化
4.图像标注
GitHub: https://github.com/AlexZhangji/Twitter-Insight-LLM
8.TeToS:集成多个文本到语音(TTS)服务商的统一接口
TeToS (Text-to-Speech Operating System)是一个开源项目,提供了一个统一的接口来集成和使用多个文本到语音(TTS)服务提供商。它旨在简化开发者在不同TTS服务之间的集成和使用过程,使得开发者可以轻松地切换或同时使用多种不同的文本到语音服务。

GitHub: https://github.com/frostming/tetos
9.Supermemory:轻松构建一个“第二大脑”可以和你收藏的任何内容聊天
supermemory的主要作用是协助用户构建一个”第二大脑”,通过一个简单的Chrome扩展,用户可以保存他们在互联网上发现的有价值的内容(允许用户将网页内容、推特收藏等转换成可搜索和可交互的格式)并能以类似ChatGPT的聊天方式与这些内容互动。
它不仅简化了内容的保存和导入流程,还通过智能化的特性,使得这些内容变得可搜索和可交互,你可以通过聊天的形式随时回顾你收藏和保持的任何网页内容并与这些内容互动。这不仅协助用户有效地存储信息,还能在需要时快速找到和使用这些信息,极大地提高了信息的利用率和个人的生产效率。
GitHub: https://github.com/Dhravya/supermemory
在线演示: supermemory.dhr.wtf
10.GPT-Academic:专门针对论文阅读、写作润色优化的学术GPT!
GPT-Academic主要是为了支持学术研究而设计的。它提供了多种工具和功能特别是针对那些需要处理大量文献、写作学术文章或进行数据分析的研究人员和学者。
github:https://github.com/binary-husky/gpt_academic
在线体验:
https://github.com/binary-husky/gpt_academic/wiki/online
11.Llama3-8B-Chinese-Chat:基于Llama3-8B微调的中文聊天模型优化中文回答

Llama3-8B-Chinese-Chat是基于Meta-Llama-3-8B-nstruct模型通过ORPo进行微调的中文聊天模型。与原始的 Meta-Llama-3-8B-Instruct模型相比,此模型显著减少了“中文问题英文回答”和混合中英文回答的问题。此外,相较于原模型,新模型在回答中大量减少了表情符号的使用,使得回应更加正式。
与Llama-3-8B-Insturct相比,模型在回答中文提示时一直都能做出更好的反应,而且在逻辑、编码、数学和写作方面表现出色。
模型下载:
https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat
12.VSR:利用AI算法准确识别一键去除视频中的字幕
Video-sSubtitle-Remover (VSR)一个基于Al技术的工具,专门用于从视频和图片中去除硬编码的字幕和文本水印。这个工具能在不损失图像分辨率的情况下,清除视频领或图片中的不需要的文字信息。

主要功能
1.高精度去除字幕:使用先进的Al算法模型准确识别视频或图片中的硬编码字幕,并将它们去除。
2.智能填充技术:对去除字幕后留下的区域进行智能填充处理,确保视频或图片的视觉连贯性和质量不受影响。
3.自定义字幕去除区域:允许用户自定义需要去除字幕的具体位置,使得去除工作更加精准和灵活。
4.全自动文本去除:支持自动检测视频全篇的字幕或文本,并进行全自动去除,适合批量处理大量视频。
5.批量处理图片:支持批量选择图片,并去除图片中的水印文本,提高处理效率
GitHub: https://github.com/YaoFANGUK/video-subtitle-rernover
13.2txt: Image to text提取任意图像上的文字并转换成可编辑的文本格式
2txt: lmage to text图像转文字
使用Claude Haiku和@vercel Al SDK创建
可以将任意图像转换成文字的工具
用户可以上传图片,系统会识别图片中的文字并将其转换成可编辑的文本格式。
它不只是简单的0CR,还会分析图片内容进行整理,确保图像到文本的转换过程快速且准确。

2txt项目的工作原理主要涉及几个关键技术组件: Vercel Al SDK、Claude Al以及 Next.js.
体验地址:2txt.vercel.app
GitHub: https://github.com/ai-ng/2txt
14.ZeST:将一种材质从一个图像迁移到另一个图像的对象上
ZeST (Zero-Shot Material Transfer)是一种从单一图像进行材质迁移的方法。该技术能够在没有任何先前训练的情况下,直接将一种材质从一个图像迁移到另一个图像中的对象上。

ZeST是由牛津大学、Stability Al和MIT CSAIL的研究团队共同完成。
技术优势:
零训练需求:作为一个零样本方法,ZeST不需要基于大量数据的预训练,这降低了技术使用的门槛和成本。
实时应用能力:由于不依赖云端处理或复杂的预训练模型,ZeST能够在设备上实时进行材质迁移,增强了应用的灵活性和即时反馈能力。
项目及演示:
https://ttchengab.github.io/zest/
论文:
https://arxiv.org/abs/2404.06425
GitHub: https://github.com/ttchengab/zest_code
在线体验:
https://replicate.com/camenduru/zest
#AI开源项目推荐##github##AI技术##AI知识#














- 最新
- 最热
只看作者