
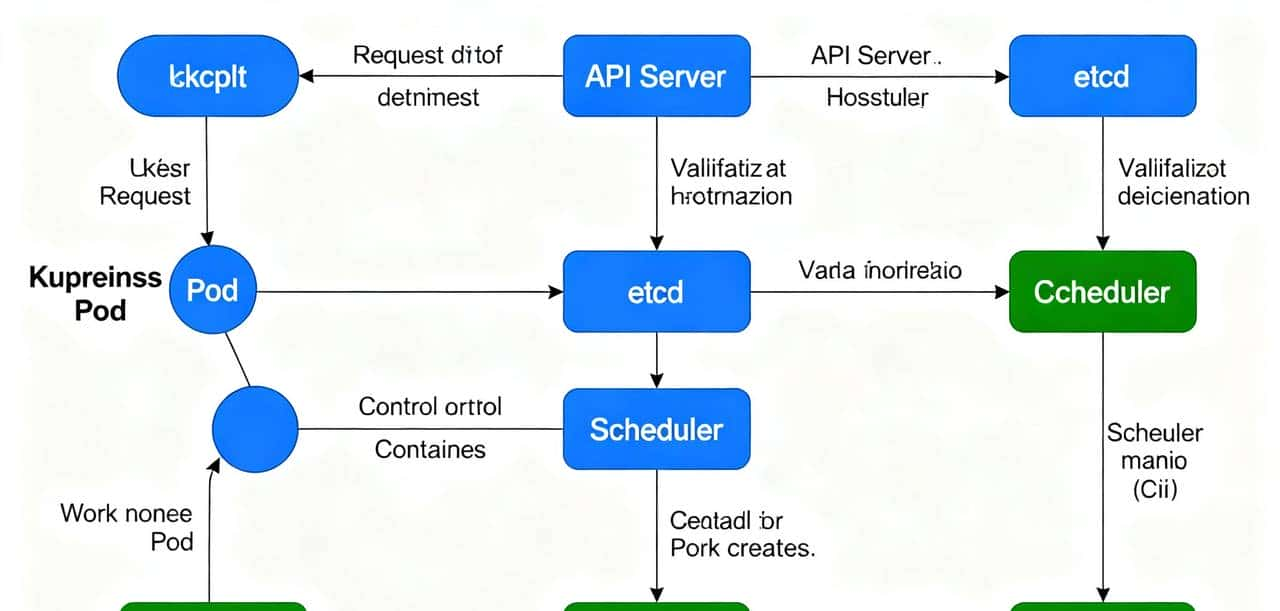
当你在终端敲下kubectl apply -f my-pod.yaml这条命令时,看似只是提交了一份 Pod 配置,实则触发了 Kubernetes 集群内部一场精密的 “分布式协作”。从请求发起 to Pod 正常提供服务,需经过 8 个核心阶段,涉及控制平面(API Server、Scheduler 等)与工作节点(Kubelet)的多轮交互,每一步都承载着 “将期望状态转化为实际状态” 的关键逻辑。

一、阶段 1:请求发起 ——kubectl 与 API Server 的 “首次通信”
一切流程始于用户的操作指令,核心是 “将配置文件转化为集群可识别的 API 请求”。
- 配置解析:kubectl 会先解析my-pod.yaml中的内容,将其转化为符合 K8s API 规范的对象(若配置的是 Deployment,则生成 Deployment 对象;若直接是 Pod,则生成 Pod 对象)。
- 请求发送:通过 HTTPS 协议向集群的API Server发送请求 —— 若为 Pod 则是POST /api/v1/namespaces/default/pods,若为 Deployment 则是POST /apis/apps/v1/namespaces/default/deployments。
- 关键定位:API Server 是集群的 “唯一入口”,所有组件间的交互、用户的操作,都必须经过它转发或验证,不存在组件间的直接跨级通信。
二、阶段 2:请求校验与持久化 ——API Server 与 etcd 的 “状态存储”
API Server 收到请求后,并非直接执行创建,而是先完成 “合法性校验” 与 “状态落地”,确保集群数据的一致性。
- 四层校验逻辑: 认证(Authentication):验证发起请求的用户身份,支持 Token、证书、RBAC 等多种认证方式,拒绝未授权访问。 授权(Authorization):检查用户是否有 “在目标命名空间创建资源” 的权限,例如普通用户可能无权在kube-system命名空间创建 Pod。 准入控制(Admission Control):执行额外的集群策略,列如资源配额(ResourceQuota)限制命名空间总资源、自动注入 Sidecar 容器(如 Istio)、校验 Pod 安全策略等。 对象验证:检查 YAML 字段是否符合 API Schema,例如resources.requests.cpu格式是否正确、image字段是否合法。
- 持久化到 etcd:所有校验通过后,API Server 将 Pod(或 Deployment)的 “期望状态(Desired State)” 写入 etcd——etcd 作为集群唯一的分布式数据库,存储着所有资源的元数据与状态,是 K8s 的 “数据大脑”。
- 状态标记:此时 Pod(若直接创建)的status.phase会被设为Pending,且spec.nodeName为空(尚未分配到具体节点)。
三、阶段 3:控制器介入 ——Deployment/ReplicaSet 的 “Pod 创建驱动”
若用户通过 Deployment 创建 Pod(而非直接创建 Pod),则需要控制器完成 “从 Deployment 到 Pod 的拆解”,这是 K8s “声明式管理” 的核心体现。
- Deployment Controller 的作用:它通过 “List-Watch” 机制实时监听 etcd 中 Deployment 对象的变化,当发现新的 Deployment 时,会根据replicas字段(如副本数 3)生成对应的 ReplicaSet 对象。
- ReplicaSet Controller 的作用:同样通过 “List-Watch” 监听 ReplicaSet 变化,对比 “期望副本数” 与 “当前运行 Pod 数”,若当前 Pod 不足,则自动向 API Server 发起 Pod 创建请求,生成的 Pod 会被打上与 ReplicaSet 匹配的标签(Labels),以便后续关联管理。
- 关键逻辑:控制器的核心是 “控制循环(Control Loop)”—— 持续对比 “期望状态” 与 “实际状态”,若存在差异则自动调整,例如 Pod 意外删除后,ReplicaSet 会重新创建 Pod,确保副本数达标。
四、阶段 4:Pod 调度 ——Scheduler 的 “节点匹配”
无论 Pod 是直接创建还是由控制器创建,此时都处于Pending状态(spec.nodeName为空),需要 Scheduler 为其 “找到合适的运行节点”。
- 调度触发:Scheduler 通过 “List-Watch” 监听 API Server,当发现未分配节点的 Pod 时,立即启动调度流程。
- 两步调度决策: 过滤(Filtering/Predicates):先排除不符合 Pod 需求的节点,例如节点剩余 CPU / 内存不足、不满足nodeSelector标签要求、存在 Pod 无法容忍的 “污点(Taint)”、持久卷(PV)无法匹配等,最终筛选出 “候选节点列表”。 打分(Scoring/Priorities):对候选节点按优先级规则排序,例如优先选择资源使用率低的节点(避免单点过载)、优先选择与 Pod 有 “亲和性(PodAffinity)” 的节点(减少跨节点网络延迟)、优先选择本地存储匹配的节点等,得分最高的节点成为 “目标节点”。
- 绑定节点:Scheduler 通过 API Server 更新 Pod 的spec.nodeName字段,将目标节点名称写入 etcd,此时调度完成,Pod 仍为Pending态,但已明确运行位置。
五、阶段 5:任务接收 ——Kubelet 的 “List-Watch 监听”
调度完成后,任务流转到目标节点的 Kubelet,这是 “从控制平面到工作节点” 的关键衔接。
- Kubelet 的监听机制:每个工作节点上的 Kubelet,都会持续 “List-Watch” API Server 中分配给本节点的 Pod(通过spec.nodeName匹配)。
- 任务触发:当 Kubelet 发现 “新的 Pod 被分配到自己节点” 时,立即启动本地的 Pod 创建流程,此时 Pod 状态开始向ContainerCreating过渡。
六、阶段 6:Pod 落地 ——Kubelet 与容器运行时的 “容器创建”
这一阶段是 Pod 在节点上的 “物理落地”,由 Kubelet 主导,依赖容器运行时(如 Containerd、CRI-O)完成具体操作,分为三步核心动作。
- 创建 Pod 沙箱(Pod Sandbox):Kubelet 调用容器运行时创建一个 “沙箱容器”(一般是 pause 容器),它不运行业务逻辑,仅为 Pod 提供独立的网络命名空间(Network Namespace)、IPC 命名空间、PID 命名空间等,确保 Pod 内所有容器共享统一的运行环境。同时,通过 CNI(容器网络接口)插件(如 Calico、Flannel)为 Pod 分配集群内唯一的 IP 地址(Pod IP),配置网络路由规则。
- 拉取容器镜像:根据 Pod yaml 中的image字段(如nginx:1.25),容器运行时从指定仓库(公有仓库或私有仓库)拉取镜像。若私有仓库需要认证,需先通过imagePullSecrets获取凭证;若镜像拉取失败(如镜像名错误、仓库不可达),Pod 会进入ImagePullBackOff状态。
- 创建并启动业务容器:为每个业务容器创建独立实例,共享 Pod 沙箱的网络与存储资源;根据volumes配置挂载存储卷,如 ConfigMap(配置文件)、Secret(敏感信息,如密码)、PersistentVolume(持久化存储)等;执行lifecycle钩子(如postStart在容器启动后执行初始化操作),最终启动容器内的业务进程。此时,Pod 的状态正式变为ContainerCreating。
七、阶段 7:健康检查与状态同步 ——Kubelet 的 “持续监控”
容器启动后,K8s 并非直接认定 Pod 可用,而是通过 “健康探针” 验证服务可用性,并同步状态到控制平面。
- 两类探针检测: 存活探针(Liveness Probe):检测容器是否 “存活”,例如通过 HTTP 请求检查服务端口是否正常响应、执行命令查看进程是否存在。若探测失败,Kubelet 会根据restartPolicy(重启策略)重启容器,避免 “容器存活但服务死亡” 的情况。 就绪探针(Readiness Probe):检测容器是否 “就绪”,即是否能正常处理请求。若探测通过,Pod 会被标记为 “就绪”;若失败,会从 Service 的 Endpoint 列表中移除,避免流量路由到不可用的 Pod。
- 状态同步:Kubelet 定期将 Pod 的 “实际状态(Actual State)”(如运行状态、容器健康状态)上报给 API Server,再由 API Server 更新到 etcd。当所有容器的就绪探针通过后,Pod 的status.phase正式变为Running,status.conditions中Ready字段设为True,表明 Pod 已具备服务能力。

八、阶段 8:服务就绪 ——Service 与 Ingress 的 “流量接入”
Pod 运行后,还需完成 “流量路由配置”,确保集群内外部能访问到 Pod 提供的服务。
- Service 的负载均衡配置:Service Controller 或 kube-proxy 通过 “List-Watch” 发现新的 Running 状态 Pod,若 Pod 标签与某个 Service 的selector匹配(如 Service 标签app: nginx对应 Pod 标签app: nginx),则将 Pod 的IP:Port加入 Service 的 Endpoint(或 EndpointSlice)列表。同时,kube-proxy 在节点上更新 iptables 或 IPVS 规则,实现请求的负载均衡 —— 当外部访问 Service 的 ClusterIP 时,流量会自动转发到后端健康的 Pod。
- Ingress 的外部流量路由:若需要外部流量(如公网)访问集群内服务,Ingress Controller(如 Nginx Ingress)会监听 Ingress 资源的变化,根据 Ingress 规则(如域名、路径)更新路由配置,将外部 HTTP/HTTPS 流量转发到对应的 Service,再由 Service 分发到 Pod。
总结:K8s “声明式自动化” 的核心逻辑
从kubectl apply到 Pod 运行,整个流程的本质是 “组件协同 + 状态驱动”:
- 组件分工明确:API Server 是 “入口与中枢”,etcd 是 “数据存储”,Scheduler 是 “决策大脑”,Kubelet 是 “执行手脚”,控制器是 “自动化保障”,各组件通过 “List-Watch” 机制实现无感知通信;
- 声明式核心:用户只需定义 “期望状态”(如 Pod 副本数、资源需求),K8s 通过控制循环自动处理中间细节,无需手动干预调度、创建、重启等操作,这也是 K8s 实现自愈、弹性、自动化的根本。
理解这一流程,不仅能快速定位 Pod 故障(如Pending查调度、ImagePullBackOff查镜像、CrashLoopBackOff查日志),更能掌握云原生系统 “以状态为核心” 的设计思想。

编辑


















暂无评论内容